{MySQL} 数据库约束& 表的关系& 新增&&删除& 修改& 查询
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、数据库约束
-
- 1.1约束类型:
- 1.2 NULL约束
- 1.3unique 唯一约束
- 1.4 DEFAULT:默认值约束
- 1.5 PRIMARY KEY:主键约束
- 1.6 FOREIGN KEY:外键约束
- 1.7 CHECK约束
- 二、新增
- 三.查询
-
- 3.1查询
- 3.2.GROUP BY子句
- 3.3HAVING
- 四、 联合查询
-
- 4.1 内连接
- 4.2外连接
- 4.3区别:
- 4.4合并查询
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
承接上文,继续讲一下MySQL
提示:以下是本篇文章正文内容,下面案例可供参考
一、数据库约束
1.1约束类型:
NOT NULL - 指示某列不能存储 NULL 值。
UNIQUE - 保证某列的每行必须有唯一的值。
DEFAULT - 规定没有给列赋值时的默认值。
PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标
识,有助于更容易更快速地找到表中的一个特定的记录。
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
1.2 NULL约束
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
1.3unique 唯一约束
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20),
qq_mail VARCHAR(20)
);
1.4 DEFAULT:默认值约束
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);
1.5 PRIMARY KEY:主键约束
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL PRIMARY KEY,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);
可以用auto_increment
-- 主键是 NOT NULL 和 UNIQUE 的结合,可以不用 NOT NULL
id INT PRIMARY KEY auto_increment,
1.6 FOREIGN KEY:外键约束
外键用于关联其他表的主键或唯一键
CREATE TABLE classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
`desc` VARCHAR(100)
);
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20),
classes_id int,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);
1.7 CHECK约束
drop table if exists test_user;
create table test_user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);
二、新增
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20),
classes_id int,
FOREIGN KEY (classes_id) REFERENCES classes(id)
)
DROP TABLE IF EXISTS test_user;
CREATE TABLE test_user (
id INT primary key auto_increment,
name VARCHAR(20) comment '姓名',
age INT comment '年龄',
email VARCHAR(20) comment '邮箱',
sex varchar(1) comment '性别',
mobile varchar(20) comment '手机号'
);
-- 将学生表中的所有数据复制到用户表
insert into test_user(name, email) select name, qq_mail from student;
三.查询
3.1查询

写俩个
//数学成绩总分
SELECT SUM(math) FROM exam_result;
-- 不及格 < 60 的总分,没有结果,返回 NULL
SELECT SUM(math) FROM exam_result WHERE math < 60;
SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;
3.2.GROUP BY子句
代码如下(示例):
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary numeric(11,2)
);
insert into emp(name, role, salary) values
('马云','服务员', 1000.20),
('马化腾','游戏陪玩', 2000.99),
('孙悟空','游戏角色', 999.11),
('猪无能','游戏角色', 333.5),
('沙和尚','游戏角色', 700.33),
('隔壁老王','董事长', 12000.66);
查询每个角色的最高最低工资
select role,max(salary),min(salary),avg(salary) from emp group by role;
select role,max(salary),min(salary),avg(salary) from emp group by role
having avg(salary)<1500;
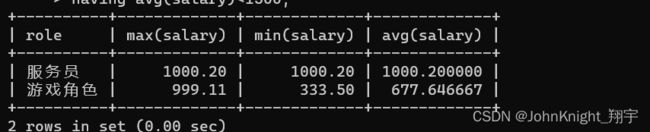
解释一下:依据角色选出最高最低工资,并且工资都是小于1500.
3.3HAVING
上面那个例子就说明了having的用法。
但是注意:GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING。
四、 联合查询
4.1 内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
SELECT
stu.sn,
stu.NAME,
stu.qq_mail,
sum( sco.score )
FROM
student stu
JOIN score sco ON stu.id = sco.student_id
GROUP BY
sco.student_id;
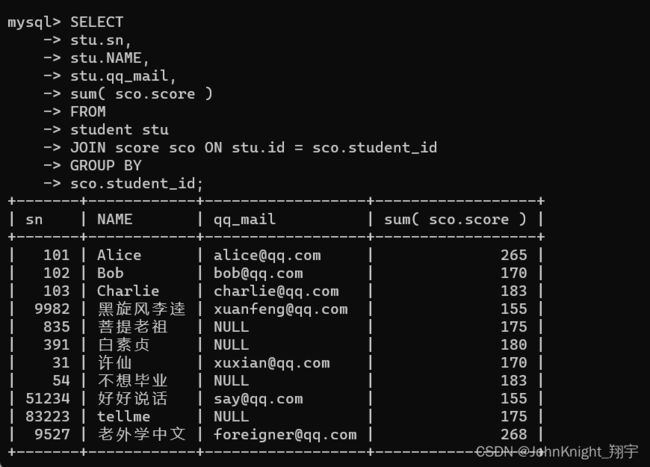
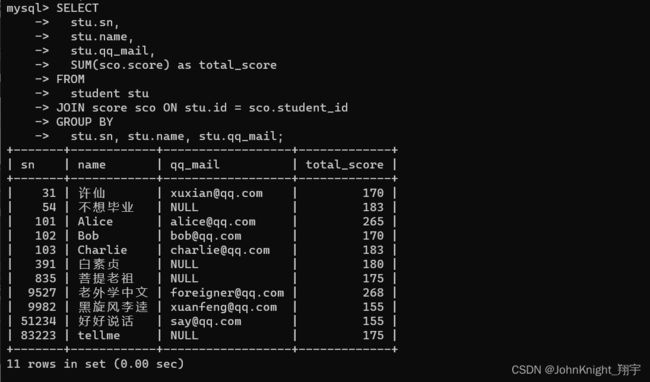
细细对比一下其实后面这个group by后面是什么不重要,主要是因为前面用了聚合函数sum,所以必须要加上group by;或者解释说把grou by 相同的分类再同一个组中,所以差距不大
4.2外连接
//左外连接
select * from student stu left join score sco on stu.id=sco.student_id;
-- 对应的右外连接为:
select * from score sco right join student stu on stu.id=sco.student_id;
4.3区别:
内连接(Inner Join):
内连接只返回两个表中连接条件匹配的行。
如果连接条件中的数据在两个表中没有匹配项,那么这些行将被忽略,不包含在结果中。
右外连接(Right Outer Join):
右外连接返回连接条件匹配的行以及右表中不匹配的行。
如果连接条件中的数据在左表中没有匹配项,左表的列将包含 NULL 值。
左外连接(Left Outer Join):
左外连接返回连接条件匹配的行以及左表中不匹配的行。
如果连接条件中的数据在右表中没有匹配项,右表的列将包含 NULL 值。
4.4合并查询
以使用集合操作符 union,union all。使用UNION
和UNION ALL时,前后查询的结果集中,字段需要一致
select * from course where id<3
union
select * from course where name='英文';
-- 或者使用or来实现
select * from course where id<3 or name='英文'
俩个意思一样
union all
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
案例:查询id小于3,或者名字为“Java”的课程
-- 可以看到结果集中出现重复数据Java
select * from course where id<3
union all
select * from course where name='英文';
总结
好了,这个是mysql的一些知识,希望大家支持呀~~