爬取东方财富网数据笔记
小白是如何学习爬虫的?首先先从简单的入手,在b站上寻找爬虫视频,这里推荐Python爬虫编程基础5天速成(2021全新合集)Python入门+数据分析_哔哩哔哩_bilibili
有编程基础的仅需要观看其中部分爬虫视频即可,如果没有编程基础可以自行观看完整视频。这里的爬虫讲解以豆瓣电影Top250的信息爬取为主,所以通过学习如何爬取豆瓣电影信息为基础,在此基础上摸索爬取东方财富网的信息数据。(爬取豆瓣的代码,在视频中有非常完整的讲解)
一、下面首先爬取了东方财富网的Title
网址:平安银行(000001)资金流向 _ 数据中心 _ 东方财富网 (eastmoney.com)
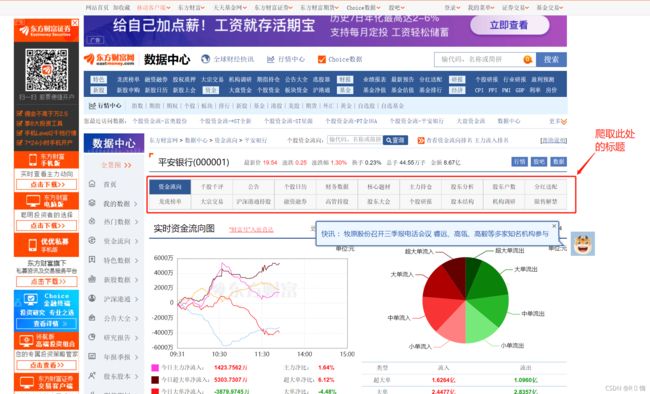
详细代码如下所示(包含部分代码解释) :
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
def main():
baseurl = "http://data.eastmoney.com/zjlx/000001.html"
# 1.爬取网页
datalist = getDate(baseurl)
# 2.逐一解析数据
# 3.打印数据或保存到当前代码文件夹下
savepath = "东方财富名称.xlsx"
saveData(datalist, savepath)
# 创建正则表达式的对象
findTitle = re.compile(r'(.*?)')
# 爬取网页
def getDate(baseurl):
datalist = []
html = askURL(baseurl) # 保存获取到的网页源码
# 2.逐一解析数据 在网页的解析中,寻找到需要的信息代码块
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('tr'):
for it in item.find_all('td'):
it = str(it)
tirle = re.findall(findTitle, it)
if len(tirle)!=0:
datalist.append(tirle[0][1])
# print(datalist)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
# 用户代理,表示告诉网页服务器,是何种类型的机器、浏览器
# 模拟浏览器头部信息,向网页服务器发送信息
headers = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 94.0.4606.61Safari / 537.36Edg / 94.0.992.31"
}
request = urllib.request.Request(url,headers=headers)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
# print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
# 保存数据
def saveData(datalist,savepath):
print('Title:\n', datalist)
book = xlwt.Workbook(encoding="utf-8", style_compression=0)
# cell_overwrite_ok=True每一个单元往里面输入的时候直接覆盖掉里面的内容
sheet = book.add_sheet('东方财富名称', cell_overwrite_ok=True)
# 向xlsx表中横向添加标题
for i in range(0, 20):
print("执行完第%d条"%(i+1))
data = datalist[i]
# print(data)
sheet.write(0, i, data)
book.save(savepath) # 保存
print('Title:\n',datalist)
if __name__ == "__main__":
# 调用函数
main()
print("爬取完毕!")二、爬取了东方财富网数据
其次进行最终的东方财富网数据的爬取会发现套用上面的代码并不能获取到我们想要的数据,这是因为上述代码以及豆瓣爬虫代码,都是爬取静态页面所用的代码,而东方财富网的数据是一个动态并且数据会不断变化的,这样看来就要对代码进行改写,但大体上的思路并没有改变。
进而学习了如何将动态数据的爬取并将其保存到数据库中,这里推荐爬虫实战 | 爬取东方财富网股票数据_cainiao_python的博客-CSDN博客_爬取东方财富网数据
想要将数据保存在csv中的同学,可以参考以上推荐博文。
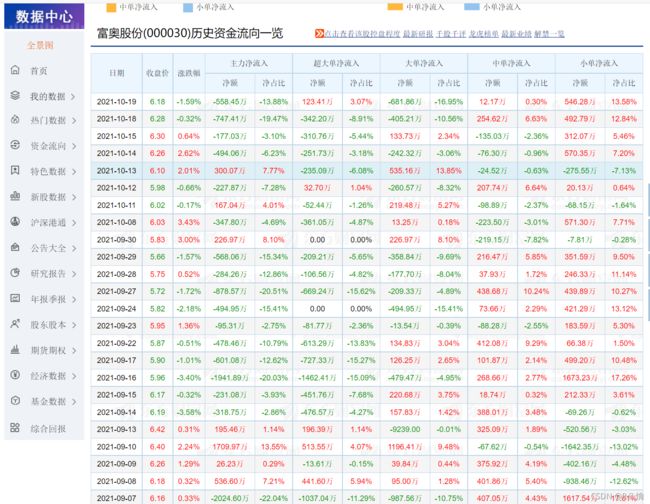
示例网页:富奥股份(000030)资金流向 _ 数据中心 _ 东方财富网 (eastmoney.com)
2.1 爬取下列动态数据:
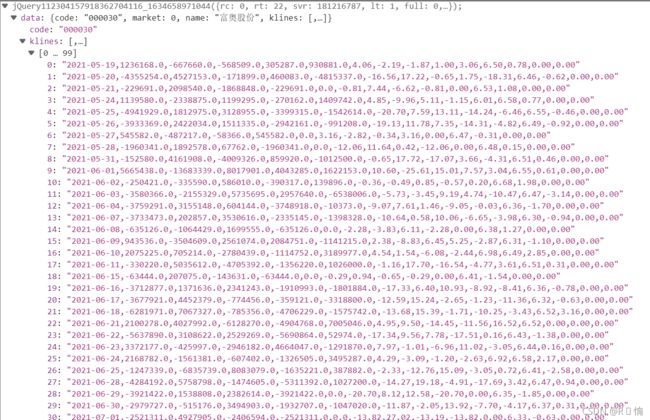
2.2 寻找网页源代码中自己所需部分:
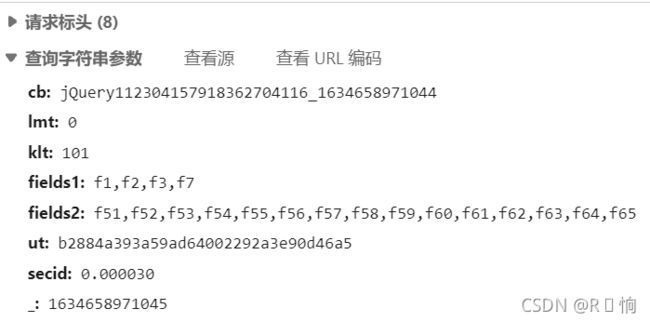
2.3 向网页发起访问请求:
headers = {
'User-Agent':'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 94.0.4606.81Safari / 537.36Edg / 94.0.992.50' }
params = {
'cb': 'jQuery11230696442006331776_1634611526503',
'lmt': '0',
'klt': '101',
'fields1': 'f1,f2,f3,f7',
'fields2': 'f51,f52,f53,f54,f55,f56,f57,f58,f59,f60,f61,f62,f63,f64,f65',
'ut': 'b2884a393a59ad64002292a3e90d46a5',
'secid': '0.000030',
'_': '1634611526504'
}
response = requests.get('http://push2his.eastmoney.com/api/qt/stock/fflow/daykline/get', headers=headers, params=params)
print(response.text)2.4 利用正则表达式对数据进行分析:
kliness = re.findall('"klines":(.*),', response.text)
# kliness1=kliness[0].split('"')
kliness1 = ','.join(kliness)
kliness2 = kliness1.strip('[')
kliness3 = kliness2.split('"')
print(kliness3)2.5连接数据库,向数据库中保存数据
# 链接数据库
connect = pymysql.connect(host='localhost', port=3306, user='****', passwd='****', database='****', charset='utf8')
print('成功与数据库连接')
# 使用该链接创建并返回的游标
cur = connect.cursor()
# 编写创建表的sql语句
sql = '''create table IdData(
riqis text ,
zhujinges text ,
xiaojinges text ,
zhongjinges text ,
dajinges text ,
chaodajinges text ,
shoupanjias text ,
zhangdiefus text
)
'''
# 执行一个数据库查询和命令
cur.execute(sql)
connect.commit()
# 这里以倒序的方式呈现进入数据库 即2021-10-19、2021-10-18……
for i in range(-len(kliness3), -1):
if len(kliness3[i]) >= 2:
# 重新连接数据库
connect.ping(reconnect=True)
data = kliness3[-i].split(',')
# print(data)
# 编写插入数据的sql语句
into = "INSERT INTO IdData(riqis,zhujinges,xiaojinges,zhongjinges,dajinges,chaodajinges,shoupanjias,zhangdiefus) values (%s,%s,%s,%s,%s,%s,%s,%s)"
# 执行一个数据库查询和命令
cur.execute(into, (data[0], data[1], data[2], data[3], data[4], data[5], data[11], data[12]))
# 提交数据库操作
connect.commit()
# 关闭数据库
connect.close()2.6 调取函数执行主函数:
if __name__ == '__main__':
main()
print("爬取成功!")2.7 执行后结果演示:

最后附完整代码:
import requests
import re
import pymysql
def main():
headers = {
'User-Agent':'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 94.0.4606.81Safari / 537.36Edg / 94.0.992.50' }
params = {
'cb': 'jQuery11230696442006331776_1634611526503',
'lmt': '0',
'klt': '101',
'fields1': 'f1,f2,f3,f7',
'fields2': 'f51,f52,f53,f54,f55,f56,f57,f58,f59,f60,f61,f62,f63,f64,f65',
'ut': 'b2884a393a59ad64002292a3e90d46a5',
'secid': '0.000030',
'_': '1634611526504'
}
response = requests.get('http://push2his.eastmoney.com/api/qt/stock/fflow/daykline/get', headers=headers, params=params)
# print(response.text)
kliness = re.findall('"klines":(.*),', response.text)
# kliness1=kliness[0].split('"')
kliness1 = ','.join(kliness)
kliness2 = kliness1.strip('[')
kliness3 = kliness2.split('"')
# print(kliness3)
connect = pymysql.connect(host='localhost', port=3306, user='****', passwd='****', database='****', charset='utf8')
print('成功与数据库连接')
# 使用该链接创建并返回的游标
cur = connect.cursor()
sql = '''create table IdData(
riqis text ,
zhujinges text ,
xiaojinges text ,
zhongjinges text ,
dajinges text ,
chaodajinges text ,
shoupanjias text ,
zhangdiefus text
)
'''
# 执行一个数据库查询和命令
cur.execute(sql)
connect.commit()
# 数据插入
for i in range(-len(kliness3), -1):
if len(kliness3[i]) >= 2:
connect.ping(reconnect=True)
data = kliness3[-i].split(',')
# print(data)
into = "INSERT INTO IdData(riqis,zhujinges,xiaojinges,zhongjinges,dajinges,chaodajinges,shoupanjias,zhangdiefus) values (%s,%s,%s,%s,%s,%s,%s,%s)"
# 执行一个数据库查询和命令
cur.execute(into, (data[0], data[1], data[2], data[3], data[4], data[5], data[11], data[12]))
connect.commit()
connect.close()
print("插入成功")
if __name__ == '__main__':
main()
print("爬取成功!")
三、爬虫过程中容易出现的问题
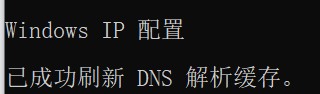
1)学习豆瓣爬虫过程中,因为豆瓣具有反爬机制,所以在爬取信息时出现404、403等问题,这里采用的方法是刷新自己电脑的IP方法:Windows键+r快速打开Windows系统的“运行”窗口,然后在这里输入cmd后点确定即运行“命令提示符”窗口,再输入ipconfig/flushdns,得到如下界面,则表示IP重置,操作成功。
2)在网页的HTML中找到自己所需要的信息数据。首先我们按F12打开开发者模式,对网页进行观察,往往从get中寻找所需数据位置,并对网页源代码进行分析,从而利用正则表达式将有效信息提取出来。
3)将数据插入数据库中,无法将所有数据一次性插入。解决方法:在循环插入数据中加如下代码:
connect.ping(reconnect=True)
出现错误的原因:在循环中增加了关闭数据库的操作,而后没有再次连接数据库,connect断开连接后,可以使用connect.ping(reconnect=True)将重新连接到数据库。
本文仅供参考学习