GNN+RL:Flexible Job-Shop Scheduling via Graph Neural Network and Deep Reinforcement Learning
读paper的目的:
看懂GNN 如何和 RL 结合的方法。 本文的GNN是HGNN,RL用的PPO算法。主要是看懂GNN和RL如何连接起来以及如何训练的。
启发:
1.不同size 的graph经过feature 抽取之后可以经过pooling 来统一维度,再送入RL学习。
2.对于GNN 可以根据节点的不同特性用不同的 GAT 进行feature的抽取。
3. 对于不同的step,action的维度和可选择的值都在变化,作者是如何处理的??待考证,还没看懂
额外思考:
抽取的是 node feature output,有没有可能变成Link output?会带来什么好处么?
[1]W. Song, X. Chen, Q. Li, and Z. Cao, ‘Flexible Job-Shop Scheduling via Graph Neural Network and Deep Reinforcement Learning’, IEEE Transactions on Industrial Informatics, vol. 19, no. 2, pp. 1600–1610, Feb. 2023, doi: 10.1109/TII.2022.3189725.
code:songwenas12/fjsp-drl (github.com) https://github.com/songwenas12/fjsp-drl
https://github.com/songwenas12/fjsp-drl
要解决的问题:
flexible job-shop scheduling problem (FJSP):简单来讲,有n个Job,K个机器。 每个Job有一系列的Operation(可以理解为Job的子步骤,需要按照一定的顺序执行)。
决策:需要去决策,
- 每一个Operation在哪一台机器上执行,即machine assignment
- 调度哪一个任务,即operation selection。
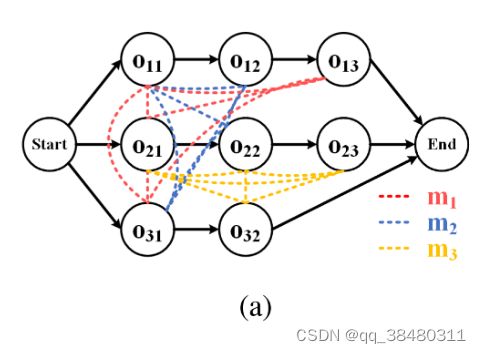
简单理解,就是如下面这个Job状态图,有三个Job,任务1有三个Operation,任务2有3个,任务3有2个。
如果现在只有一个machine,那么需要在这个machine上决定如何去执行这三个任务的每个子步骤,即Operation。现在有K个machine,既得把这些任务分到这K个machine上,又决定每个任务在machine上的执行顺序,所以是 两层决策。
采取的方案:
把Job 和machine建模为 顶点,关系建模为edge,构成一个异构的GNN图,然后从原始图raw features抽取隐含的 feature,送PPO,即RL中进行学习。
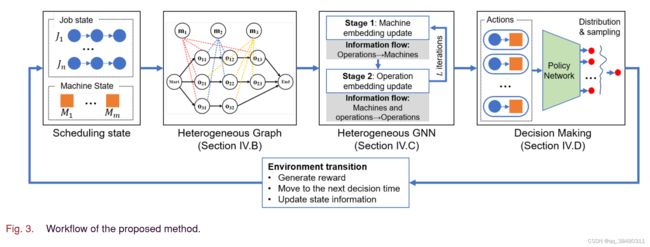
MDP:
State:即状态,是由一个异构Graph 表示的,具体不赘述。
表示的,具体不赘述。
Action:这里比较有意思,action 并不是一个从episode的开头到结尾一样的,而是 在t 时刻可行的O-M pair。 举个例子, 假设在 0时刻, 三个machine 都空闲, 三个任务的Operation 都没开始,即 需要从 ![]() 开始执行,那0 时刻的 feasible pairs 应该是 9个 ,即 {
开始执行,那0 时刻的 feasible pairs 应该是 9个 ,即 {![]() }
}
假如1时刻 采用了![]() , 那么相当于 M1机器被
, 那么相当于 M1机器被![]() 占用了,下一个时刻的 feasible pairs 变成了 4个{
占用了,下一个时刻的 feasible pairs 变成了 4个{![]() },这样的话 action在每个step的状态空间和状态值都不同,如何输出policy呢?
},这样的话 action在每个step的状态空间和状态值都不同,如何输出policy呢?
Reward: Makespan difference,即最大完工时间的差。
HGNN:
1)Machine Node embedding(融合了自己和周围的Operation,以及edge)
对于machine node,他的一阶邻居应该是 相连的可执行的Operation。
the importance of each neighboring operation Oij
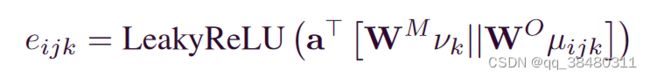
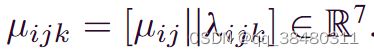
machine specific weights:
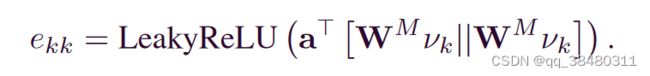
machine embedding ν′ k is computed by fusing features from neighboring operations and itself
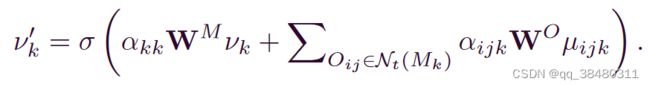
2)Operation Node Embedding:(融合了自己和,前一个、后一个operation 加上 可选的Machine 的features)
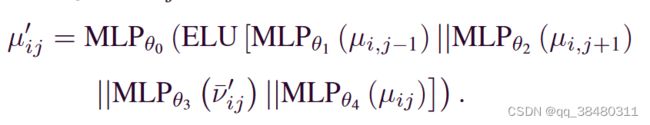
在经过 L层的HGNN 之后,放入 pooling layer:
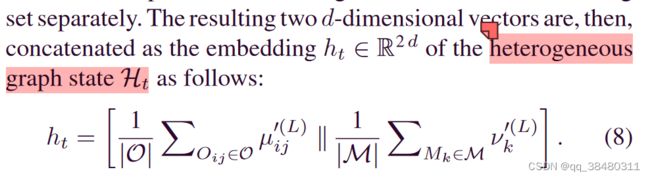
Through the above process, a varying-size heterogeneous graph can be transformed into a fixed-dimensional embedding.
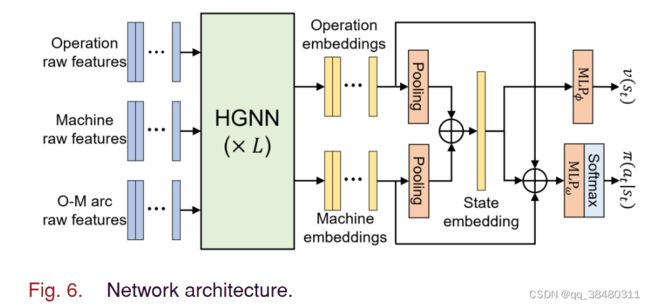
Decision making:
把operation,machine 和 state embedding加和起来作为policy network的输入。

每个 action 被采样的概率:
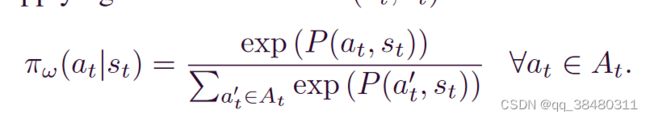
网络结构: