初学python的体会心得20字,初学python的体会心得2000
大家好,给大家分享一下初学python的体会心得20字,很多人还不知道这一点。下面详细解释一下。现在让我们来看看!

很多同学抱怨自己很想学好Python,但学了好久,书也买不少,视频课程也看了不少,但是总是学了一段时间,感觉还是没什么收获,碰到问题没思路,有思路写不出多少行代码,遇到报错时也不知道怎么处理。
从入门到放弃,这是很多学习python的同学常常挂在嘴边上的口头禅用python绘制满天星。今天我分享一些自己学习Python的心得,并用一个案例来说明python解决问题的基本思路和框架。
1 如何学好Python
1.1 明确自己的需求(最好是刚需)
听到别人说Python很牛很厉害,也想跟着学,这样的人肯定是学不好python的。没有明确的需求和动力,就会导致你学python两天打鱼三天晒网,没有恒心也没有决心。
假如你有明确的需求,比如:
- 老板让我1周内完成一个数据分析报告
- 老板让我1个月内搭建一个自己的blog网站
- 我要处理很多excel文件,我想写一个脚本帮我自动处理
- 我每天都在手动审核数据质量,我想写一个脚本代替我的日常工作
- …
当你面对这样一些需求时,你还无法求助他人帮忙时,这个时候,你就必须学习Python来帮你处理了。
1.2 明确Python的学习方向
Python的学习方向有很多,比如:
- WEB方向
- GUI方向
- 数据处理方向
- 数据分析方向
- 人工智能方向
- …
我是日常用Python主要做数据处理和数据分析工作,所以我选择的是数据处理和数据分析方向,其他Python功能接触的比较少。
1.3 掌握Python的基本语法
- import模块导入方法
- 变量及基本数据类型
- 循环和条件基本控制语句
- 模块内嵌函数和自定义函数
- …
不管你选择了什么方向,Python的基本语法是必须掌握的。对于没有编程经验的人,Python是一门非常适合入门的编程语言,因为它是高度封装的,不需要对于底层特别了解,也能够很好学习使用。python语法非常简单,代码可读性高,对于零基础的人来说更容易接受和使用。
1.4 掌握Python数据处理方法
- 线性代数和统计学
- Pandas/Numpy/Matplotlib模块
- 数据导入、存储
- 数据清洗和准备
- 数据规整:连接、联合、重塑
- 数据整合和分组操作
- 时间序列数据操作
- 绘图和可视化
利用Python做数据处理,线性代数和统计学这两门基本理论知识还是要会点,线性代数你至少得需要知道矩阵和矩阵运算规则,统计学你至少要知道描述性统计。
常用的Python数据处理模块有Pandas和Numpy这两个,这是必须要掌握的,另外,Matplotlib模块是数据可视化模块,也是必须会的。
数据导入、清洗和准备、规整、分组等操作,都是数据处理中常用的方法,平常对比Excel数据操作,Python都可以实现,而且一行简单的代码,就可以操作比较复杂的数据处理方法。
1.5 多练!多练!多练!
- 自己找些小作业练习
- 解决平常工作中的问题
- 可以尝试输出文章
重要的事情说三遍,多练!多练!多练!
Python和数据分析都是实践学科,光学理论,不练习,是不会有任何收获的,学完之后不练就忘掉了。最好的方式,就是先掌握一点基础语法,然后把Python融合到工作中,解决日常工作中碰到的问题。在解决问题的时候,你会碰到各种问题,可以去"百度"寻找答案。最后,要定期总结和输出。
特别提示,假如你没有基础或者基础薄弱的话,建议工作期间不要尝试用Python解决复杂的问题,这是一个很浪费时间的事情,中间各种问题,会让你崩溃。最终Python没学好,还耽误了工作。所以,要利用工作之余的时间,把python基础打扎实。
2 Python数据处理示例
2.1 安装并搭建python环境
首先,需要安装python,我要推荐Anaconda3,从事数据分析的伙伴们,严重推荐此软件!
Anaconda降低了数据分析初学者的学习门槛,因为这个软件自带了python中大概有1000多个数据科学包,让你无需单独学习每个库的安装方法。另外,还自带了Jupter notebook代码编译器。现在,Anaconda和Jupyter notebook已成为数据分析的标准环境。
安装完成后,打开Jupter Notebook,就可以在上面输入代码。
2.2 问题说明
现在工作中面临一个批量化文件处理的问题:就是要把每个二级文件下csv文件合并到一个数据表里,同时要在最终的数据表里增加两列,一列是一级文件目录名称,另一列是二级文件目录名称。
- 总共有105个一级文件目录
- 每个一级文件下有若干个二级文件
- 每个二级文件下有若干个csv格式的数据
当工作中,碰到这样的问题时,我用最笨拙的方法——人工,一个一个文件整理,但是效率比较低,可能需要一个人一天的工作量。当然,我也可以寻找技术的帮忙,找一个Java工程师,这个问题也很容易解决,但麻烦别人一次,没问题。以后碰到类似的问题,总是麻烦,就不好了。假如自己掌握了Python,这个问题就变得很简单了。
2.3 程序实现
其实这个问题,对于一个专业的Python程序员来说,是一个再简单不过的问题。但是对于一个初学者来说,要解决这个问题,恐怕需要费一点时间和脑力。
编程之前,我是如何思考的:
1、首先,要读取文件名称,需要引入OS模块下的listdir函数
2、其次,遍历所有一级、二级、三级文件名称,需要用到for循环和循环嵌套
3、然后,读取文件下csv表,需要用到pandas模块下的read_csv函数
4、最后,整理合并后的所有表,需要用到DataFrame的操作方法
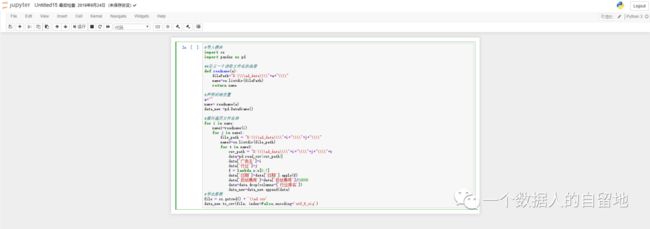
实现代码如下:
#导入模块
import os
import pandas as pd
##定义一个读取文件名的函数
def readname(a):
filePath="D:\\\\ad_data\\\\"+a+"\\\\"
name=os.listdir(filePath)
return name
#声明初始变量
a=""
name= readname(a)
data_new =pd.Dataframe()
#循环遍历文件名称
for i in name:
name1=readname(i)
for j in name1:
file_path = "D:\\\\ad_data\\\\"+i+"\\\\"+j+"\\\\"
name3=os.listdir(file_path)
for t in name3:
csv_path = "D:\\\\ad_data\\\\"+i+"\\\\"+j+"\\\\"+t
data=pd.read_csv(csv_path)
data['广告主']=i
data['行业']=j
f = lambda x:x[0:7]
data['日期']=data['日期'].apply(f)
data['投放费用']=data['投放费用']/10000
data=data.drop(columns=['行业排名'])
data_new=data_new.append(data)
#导出数据
file = os.getcwd() + '\\ad.csv'
data_new.to_csv(file, index=False,encoding='utf_8_sig')
这段代码虽然简单,但基本攘括了Python的大部分基本语法,接下来我带大家一一解剖下这些基本语法。
- import语句
- 声明变量
- 数据导入和导出
- 循环和嵌套循环
- 模块函数调用
- 自定义函数
- Lambda表达式
- Dataframe及操作
3 Python基本语法详解
3.1 import详解
下面程序使用导入整个模块的最简单语法来导入指定模块:
import os #导入OS模块
import pandas as pd #导入pandas模块
使用Python进行编程时,有些功能没必须自己实现,可以借助Python现有的标准库或者其他人提供的第三方库。像OS和pandas,都是标准库,导入后,就可以在程序中使用其模块内的函数,使用时必须添加模块名作为前缀。
name3=os.listdir(file_path) #导入os模块下的listdir函数
假如模块名长,就可以取别名,比如pandas模块,取别名为pd。像os模块,由于比较简短,就没有取别名。别名的作用,就是调用该模块下的函数时,减少代码的复杂度。
import pandas as pd
data=pd.read_csv(csv_path)
3.2 数据导入和导出
数据的导入是数据处理和分析的第一步,日常我使用的比较多的是利用pandas进行数据输入和输出,尽管其他库中也有许多工具可帮助我们读取和写入各种格式的数据。
将表格型数据读取为DataFrame对象是pandas的重要特性
- read_csv(csv文件输入函数)
- read_table(文本文件输入函数)
- to_csv(数据输出函数)
#遍历所有文件路径,读取所有文件下csv文件数据
csv_path = "D:\\\\ad_data\\\\"+i+"\\\\"+j+"\\\\"+t
data=pd.read_csv(csv_path)
当然,数据的输入,也有与数据库交互读取数据,也有与WEB API交互读取数据,这个是属于进阶的内容,后期带大家学习。
3.3 声明变量
变量是Python语言中一个非常重要的概念,其作用就是为Python程序中的某个值起一个名字。类似于"张三"、"李四"一样的名字。在Python语言中,声明变量的同时需要为其赋值,毕竟不代表任何值的变量毫无意义。
a="" #声明一个空字符类型
data_new =pd.Dataframe() #声明一个空数据集格式
声明变量非常简单,语法结构:等号(=)左侧是变量名,右侧是变量值,Python编译器会自动识别变量的数据类型。
说到变量,就不得不谈Python的基本数据类型,Python有6个标准的数据类型:
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
学习Python,掌握其基本数据类型,特别重要!重要!重要!详细的介绍,见:
3.4 控制语句
我们所见到的程序,有很多程序都是按照顺序从上到下执行它们。如果你想要改变语句流的执行顺序,也就是说你想让程序做一些决定,根据不同的情况做不同的事情。这个时候,就需要通过控制流语句来实现。
3.5 模块函数调用
函数是组织好的,可重复使用的,用来实现单一、或者相关功能的代码段。
函数能提高程序的模块性,和代码的重复利用率。Python提供了许多标准模块的内建函数,比如os模块下的listdir函数,用来读取文件的名称,pandas模块下的read_csv函数,用来读取csv文件的数据。当然,也可以自己创建函数,也就是所谓的自定义函数,下一节详细讲。
import os #导入OS模块
import pandas as pd #导入pandas模块
name=os.listdir(filePath) #调用os模块下的listdir函数
data=pd.read_csv(csv_path) #调用pandas模块下的read_csv函数
3.6 自定义函数
我们可以自定义一个自己想要的功能函数,通常遵循以下规则:
- 函数代码块以def关键词开头,后接圆括号()和参数。
- 函数内容以冒号起始,并且缩进。
- return结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回None。
#自定义一个函数,动态传参,读取文件的名称
def readname(a):
filePath="D:\\\\ad_data\\\\"+a+"\\\\"
name=os.listdir(filePath)
return name
定义一个函数只给了函数一个名称,指定了函数里包含的参数和代码结构。这个函数的基本机构完成以后,你就可以通过调用该函数来实现你想要的返回结果。
a=""
#调用自定义函数
name= readname(a) #参数传递,传一个空字符串
3.7 Lamda表达式
Lambda是一个表达式,定义了一个匿名函数,代码x为入口参数,x[0:7]为函数体。非常容易理解,在这里lambda简化了函数定义的书写形式。使得代码更为简洁,更为直观易理解。
但是lambda函数,在Python社区是一个存在争议的函数,支持方认为,Lambda函数的使用,使得代码更加紧凑。反对法认为该函数用多了反而看起来不那么清晰。
f = lambda x:x[0:7]
data['日期']=data['日期'].apply(f)
在用pandas做数据处理的时候,个人习惯,apply+lambda配合使用,可以对dataframe数据集中的列做很多很多事情。
3.8 Dataframe及操作
DataFrame是一种表格型数据结构,在概念上,它跟关系型数据库的一张表,Excel里的数据表一样。
创建一个DataFrame
#根据字典创建一个DataFrame
import pandas as pd
data = {
'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]
}
frame = pd.DataFrame(data)
frame
#输出
state year pop
0 Ohio 2000 1.5
1 Ohio 2001 1.7
2 Ohio 2002 3.6
3 Nevada 2001 2.4
4 Nevada 2002 2.9
日常数据处理的过程中,通常是通过读取文件生成DataFrame,最常用的是read_csv,read_table方法。下面是最简单的读取文件语句,该方法中有很多重要的参数,在导入文件时候,通过这些参数,可以控制导入数据的格式和数量。其他创建DataFrame的方式也有很多,比如我经常会从SQL SERVER读取数据来生成。这里就不详细介绍。
pd.read_csv('C:\\Users\\ivan\\Desktop\\数据.csv')
DataFrame索引、切片
我们可以根据列名来选取一列,返回一个Series,同时也可以对这一列的数据进行操作。
#日期格式 2020-07-01,定义一个把日转换成月的函数,转换出2020-07
f = lambda x:x[0:7]
data['日期']=data['日期'].apply(f)
#对"投放费用"这一列进行处理,把单位转换成"万"
data['投放费用']=data['投放费用']/10000
4 总结
最后,我说下Python与Excel之间的关系,为什么要拿这两个工具比较,因为很人觉得:
- 日常工作中,Excel足够应对数据处理工作
- 有人宁愿使用Excel贼6,也不愿意使用python
从根本上来说,Python和excel都可以作为数据处理和分析以及展现的工具,工具本身没有好与坏,关键在于使用者的业务场景以及使用自身对工具的掌握程度。当两种工具都能达到使用者业务场景想要的效果时,使用者会更倾向于使用自己熟练或者更易于实现的工具高效地解决实际问题。
所以说,日常大部分与数据相关的工作中,少量数据的处理和分析,excel都足以胜任,除非遇到大样本数据导致excel无法处理或者计算很慢时,这时候python的优势才会体现出来。
除此之外,如果使用者的业务场景是报表呈现时,excel做出来的结果直接就是可以交付的结果。
当然,当面临大量需要重复处理的文件或者经常要做的数据工作,这个时候,如果自动化,会大大提高工作效率,这个时候,python的优势也很明显。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等习教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
Python学习路线汇总
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)
Python必备开发工具

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
Python学习视频600合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
100道Python练习题
检查学习结果。
面试刷题



这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
