LLM 4 Vulnerability Detection
LLM 4 Vulnerability Detection
- 1.InferROI
-
- 1.1.introduction
- 1.2.motivation
- 1.3.Approach
- 1.4.Evaluation
-
- 1.4.1.RQ1.Effectiveness in Intention Inference
- 1.4.2.RQ2.Resource Leak Detection
-
- 1.4.3.RQ3.Open-Source Project Scanning
- 1.4.4.RQ4.Ablation Study
- 1.5.Discussion
- 2.Latte
-
- 2.1.Motivation
- 2.2.Approach
-
- 2.2.1.Function Chain Generation
- 2.2.2.Dangerous Flow Generation
- 2.2.3.Prompt Sequence Construction
- 2.3.Evaluation
-
- 2.3.1.RQ1.Latte漏洞检测性能
- 2.3.2.SSF和EIS识别(source-sink识别)准确度
- 2.3.3.RQ3.Dangerous Flow提取精度
- 2.3.4.RQ4.Real world漏洞检查
- 2.4.Discussion
- 3.GPTScan
-
- 3.1.Motivation
- 3.2.Overview and Challenge
- 3.3.Function Matching & Static Confirmation
1.InferROI
paper地址
1.1.introduction
Issues:
-
Resource Acquisition/Release APIs的完全性以及漏报问题:现有resource leak的检测方式依赖于与定义API pair的完全性, 但FindBugs, Infer, CodeInspection只支持resource leak api的一个子集合。 因此,特定api相关 (
AndroidHttpClient) 会被漏报。 -
Resource可达性分析以及误报问题:在现有的检测技术中,在CFG上分析resource reachability会有误报发生。Torlak通过空指针条件判断(
cur != null)分析resource accessibility。然而,这种方法对于其它情况 (!bank.isDisabled)就不太适用,同时,误报在一些不可达路径也会被触发。 -
现有检测范式的复杂程度:以定位CFG路径中的一些预定义的API对(例如,
Socket申请和释放)为核心的检测范式,由于其固有的复杂性,面临着重大挑战。某些技术进行了不必要的跨函数控制流分析并追踪调用链。这可能会极大地增加路径分析的难度,尤其是考虑到跨过程控制流分析的不精确性。
solutions:结合资源管理知识以及代码上下文理解推断资源操作 (resource acquistion/release, 可达性验证)。在接收到代码片段时,InferROI使用一个prompt template来引导LLM推断涉及的resource acquistion/release意图,从而消除了对资源API对的预定义需求。
LLM
-
生成自然语言的输出,随后被解析成意图的形式表达。
-
通过汇总这些推断出的意图,InferROI继续实施基于轻量级静态分析的算法,分析从代码中提取的CFG路径,实现对资源泄漏的检测。该算法考虑了沿着个别CFG路径进行的资源获取和释放,以找到潜在的泄漏。然后,它考虑了这些路径上资源可达性对兄弟分支的影响,减轻了误报,提高了泄漏检测的精度。
Evaluation Summary:
InferROI基于Java实现,这项研究采用了DroidLeaks数据集,其中包含了86个Android应用程序中的漏洞,产生了172个(2 × 86)代码片段,包括有漏洞版本和修复版本。为了评估InferROI在推断面向资源的意图和检测资源泄漏方面的性能,进行了以下实验:
-
意图推断Evaluation: 手动对代码片段中的资源意图进行了注释,并使用InferROI进行意图推断。结果表明,InferROI在意图推断方面取得了74.6%的精度和81.8%的召回率,同时在DroidLeaks中列出的28个Android资源中达到了67.9%的覆盖率。
-
资源泄漏检测Evaluation: 在172个代码片段上应用InferROI进行资源泄漏检测。在有漏洞版本的代码片段中,InferROI实现了相对较高的漏洞检测率(53.5%),而基线方法的检测率为3.4%56.9%。在修复版本的代码片段中,InferROI产生了较低的误报率(8.1%),而基线方法的误报率为0%41.8%。
-
开源项目资源检测Evaluation: 将InferROI应用于真实的开源项目,对100个方法进行资源泄漏检测。实验结果显示,InferROI检测到了12个未知的资源泄漏,其中7个在提交时已被开发人员确认。
1.2.motivation
-
HttpClient.newInstance(mUserAgent)申请了http client资源。 -
在bug版本中
HttpClient.close()没有被调用。
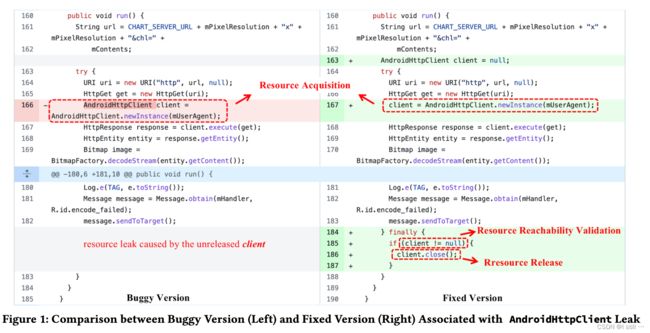
识别这个resource leak存在以下难点:
-
更全面地识别资源获取/释放操作: 在上述例子中,与
AndroidHttpClient类相关的资源泄漏在DroidLeaks数据集中所评估的8个检测器均未被检测到。除了AndroidHttpClient之外,其它库/包中也实现相关http调用api。例如,在selenium库中,存在类似HttpClient、JdkHttpClient、NettyClient等相关API。在DroidLeaks中评估的8个检测器也未能检测到所有这些API的资源泄漏。这种失败可以归因于检测器无法把握这些API共享的基本共同特征,这些特征本质上代表相同的资源概念,即HTTP客户端及其使用。 -
更全面地进行资源可达性验证:资源可达性的验证是确定资源泄漏发生的关键因素。在修复版本中,第185行的
if条件用于在其在第186行释放之前验证获取的HTTP客户端资源的可达性。如果忽略了用于可达性验证的这个if条件,将在if语句的false分支中触发误报,实际上获取的资源是不可达的。现有的检测技术,通常通过匹配空值检查条件来识别可达性验证。但有的API,比如isDisabled(), isClose()有等价功能。 -
降低检测过程中程序分析的复杂性:现有的检测技术需要复杂的过程间分析技术来进行长距离调用链下的resource leak分析。比如
AndroidHttpClient的资源分配通常封装了socket API。这其中涉及了复杂了调用链。通过推断封装关系,可以减少跨函数分析。示例中,如果能识别AndroidHttpClient.newInstance直接申请了资源就不需要深入调用链。
1.3.Approach
- Resource-Oriented Intentions
通常资源泄漏会涉及以下操作
-
Resource Acquisition:可以通过
acquire(var, lineno)表示,var表明获取的资源,lineno表示语句行号。上图代码可以表示为acquire(client, 167)。 -
Resource Release:释放资源操作,可以通过
release(var, lineno)表示。上图代码可以表示为release(client, 186)。 -
Resource Reachability Validation:表明获取的资源是否可达(是否不为
null),可以通过validate(var, lineno)表示。上图代码可以表示为release(client, 185)。
- Intention Inference
根据以下prompt template输入LLM获取初始分析结果,随后提取formal expression
Task Description
Analyze the information about resource leaks in the provided code snippet
below. First, resolve the types of the involved objects. Then, identify the types
representing leakable resources. Next, identify the API/method calls for
acquiring the resources. After that, identify the API/method calls for releasing
the acquired resources. Finally, identify the if-conditions for checking whether
the acquired resources are closed or unclosed
Output format:
Desired format:
Leakable Resources:
:
API/method Calls for Acquiring Resources:
line : `` acquires `` resource
API/method Calls for Releasing Resources:
line : `` releases `` resource
If-conditions for Checking Resources closed or not:
line `` checks `` resource
Code PlaceHolder:
Code Snippet: `java
{CODE}
``
Answer of GPT4:
Leakable Resources:
AndroidHttpClient: client
API/method Calls for Acquiring Resources:
line 167: `AndroidHttpClient.newInstance(mUserAgent)` acquires `client`
resource
API/method Calls for Releasing Resources:
line 185: `client.close()` releases `client` resource
If-conditions for Checking Resources closed or not:
line 186: `if (client != null)` checks `client` resource
随后,使用正则表达式解析GPT的Answer,从 "line 这样的字眼中提取 line number, API call, resource variable。基于以上信息可以提取到 acquire(client, 167), release(client, 185), validate(client, 186)。
- Static Resource Leak Detection
通过轻量级静态CFG分析结合formal expression推测漏洞。
给定一个method-level的AST,作者遍历AST构建CFG,随后遍历entry到exit的路径,作者提出了2种策略修剪。
-
Loop:Loop的
true分支对应的路径只会遍历一次。 -
Resource independent branch:对于
if语句和switch语句,检查其分支条件是否无关于resource获取/释放并且不包含退出操作(return语句)。如果这些条件满足,那么只保留一个分支,因为其它分支可能具有相同的resource行为。这个检查操作会基于formal expression进行。
上面代码中,解析出来的CFG path包括 [160-185, 186, 187-190], [160-185, 187-190]。
随后基于path进行resource leak检测。
-
第一阶段是单路径分析,根据
acquire,release意图初步识别相关资源的泄露风险路径。 -
第二阶段是跨路径分析,通过识别
validate意图消除引入误报的路径。这部分insight在于假如有一个if语句判断资源是否为null,不为null则释放资源。那么在false branch就不会有释放资源的操作,这时false branch就会发生误报。因此需要通过validate意图识别消除这种false branch误报。 -
完成两个阶段后,该算法检查是否存在具有相应
true状态的路径。如果存在这样的路径,则报告res的资源泄露。
def LeakDetection(res, paths: Set[Path], intention_sets):
'''
res: concerned paths
paths: CFG paths
intention_sets: formal expressions of intention set
'''
# 单路径分析,标记潜在leak路径
for path in paths:
rd_counter = 0
for node in path:
ln = get_line_number(node) # 获取该node对应的行号
if acquire(res, ln) in intention_sets: # 如果ln申请了对应资源
rd_counter += 1
elif release(res, ln) in intention_sets: # 如果释放了资源
red_counter -= 1
if rd_counter > 0:
path.risky = True
else:
path.risky = False
# 跨路径分析,消除误报
if_stmts = get_all_if_stmts(paths) # 获取路径集合中所有的if语句
sort_stmts_in_line_number(if_stmts) # 按行号排序
for if_stmt in if_stmts:
ln = get_line_number(if_stmt)
# 如果不是validate操作
if not validate(res, ln) in intention_sets:
continue
G_prefix: Set[path] = group_paths_containing_if(if_stmt) # 提取所有包含validate if stmt的路径,set中的每一个元素为一个路径前缀
for g in G_prefix:
B1, B2 = group_paths_by_branches_of_if(if_stmt)
propagate(B1, B2)
# report leak
for path in paths:
if path.risky:
report_leak(path, res)
def propagate(B1: Set[path], B2: Set[path]):
if all([path.risky for path in B1]) and (not any([path.risky for path in B2])):
for path in B1:
path.risky = False
elif all([path.risky for path in B2]) and (not any([path.risky for path in B1])):
for path in B2:
path.risky = False
在示例的fix版本中,InferROI在第一阶段识别leak路径: [160-185, 187-190],但是在第二阶段,其对应的 true 分支不存在泄漏,因此被识别为误报被消除。
对于 try-with-resources 语句,作者实现了一个基于规则的后处理方法。
1.4.Evaluation
1.4.1.RQ1.Effectiveness in Intention Inference
这部分主要研究InferROI识别resource-oriented操作的准确率。作者从DroidLeak数据集中选取了86个bug,算上fix版本总共172个代码片段,包含28种不同的资源类型,比如 Cursor 和 InputStream。其中两位作者手动在172个代码片段上标注3种操作 (acquire, validate, release)。最后,InferROI取得了74.6%的precision和81.8%的recall。
下表反映了28种资源类型中不同检测器可以识别的数量,可以看到InferROI最多。
| Detector | 覆盖的资源类型数量 |
|---|---|
| Code Inspection | 16 (57.1%) |
| Infer | 11 (39.3%) |
| Lint | 3 (10.7%) |
| FindBugs | 9 (32.1%) |
| Relda2-FS | 6 (21.4%) |
| RElda2-FI | 6 (21.4%) |
| Elite | 2 (7.1%) |
| Verifier | 2 (7.1%) |
| InferROI | 19 (67.9%) |
不过,像 Camera 以及 MediaPlayer 并没有被成功识别。这类resource通常由Android lifecycle管理。
InferROI优势:
-
通过代码理解能力进行资源操作识别,因此,像
AndroidHttpClient都能被提取。 -
prompt也扮演了重要角色,如果没有前两个prompt,precision和recall直接下降20%-30%。
1.4.2.RQ2.Resource Leak Detection
通过召回率和误报率进行评估。
| Detector | Detected Bugs | False Alarms |
|---|---|---|
| Code Inspection | 49 (56.9%) | 36 (41.8%) |
| Infer | 37 (43.0%) | 16 (18.6%) |
| Lint | 10 (11.6%) | 0 (0%) |
| FindBugs | 6 (6.9%) | 0 (0%) |
| Relda2-FS | 11 (12.7%) | 9 (10.4%) |
| RE lda2-FI | 8 (9.3%) | 4 (4.6%) |
| Elite | 6 (6.9%) | 4 (4.6%) |
| Verifier | 3 (3.4%) | 2 (2.3%) |
| InferROI | 46 (53.5%) | 7 (8.1%) |
需要注意的是InferROI仅基于函数内分析就取得了相对较高的性能。无需进行复杂的跨函数分析。
1.4.3.RQ3.Open-Source Project Scanning
作者爬取了超过50 start的115个Java开源项目,这些项目是在2021年12月31日之后创建的。作者使用日期筛选条件以避免爬取gpt-4的训练集,随后,作者通过匹配20个常见的资源关键词,从13个项目中随机抽取了100个函数进行评估,而不是完全扫描这些项目。所使用的关键词如下:[stream、reader、client、writer、lock、player、connection、monitor、gzip、ftp、semaphore、mutex、stream、camera、jar、buffer、latch、socket、database、scanner、cursor]
作者用InferROI对这100个method进行检查。对于每个报告的漏洞,作者通过阅读代码和查询相关信息来手动标注是否是一个真正的漏洞。对于真正的漏洞,作者会提交相应的修复拉取请求,并要求项目开发者对其进行审查。
作者总共报告了16个resource leak,其中12个是true bug。paper提交的时候,7个已经被开发者确认。
12个bug中4个没有被现有的检测工具发现,resource type包括 URLClassLoader,ManagedBuffer,以及project定制的 JDBCConnection。
1.4.4.RQ4.Ablation Study
作者的ablation针对2部分:LLM-based资源意图识别以及静态leak检查。
为了进行ablation,作者创建了两个prompt模板,使gpt-4能够直接在代码中检测资源泄漏,从而得到两种资源泄漏检测器:GPTLeak和GPTLeak-chain。模版如下图所示:
GPTLeak
Identify resource leaks in the provided code snippet below.
Desired format:
Leaky Resources:
Code Snippet: `java
{CODE}
`
GPTLeak-Chain
Identify resource leaks in the provided code snippet below.
Analyze the information about resource leaks in the provided code snippet
below. First, resolve the types of the involved objects. Then, identify the types
representing leakable resources. Next, identify the API/method calls for
acquiring the resources. After that, identify the API/method calls for releasing
the acquired resources. Subsequently, identify the if-conditions for checking
whether the acquired resources are closed or unclosed. Finally, identify resource
leaks
Identify resource leaks in the provided code snippet below.
Desired format:
Leaky Resources:
Code Snippet: `java
{CODE}
`
对于GPTLeak,指令很简单,而对于GPTLeak-chain,则将额外的检测指令(最后一句话)合并到InferROI使用的模板中,以便在决策过程中向gpt-4模型提供具体的指导。
作者将这两种GPTLeak和GPTLeak-chain检测器应用到从DroidLeaks数据集收集的172个代码片段中。随后,计算每种检测器的bug检测率和误报率。
| Detector | Detected Bugs | False Alarms |
|---|---|---|
| GPTLeak | 44 (51.2%) | 18 (20.9%) |
| GPTLeak-Chain | 32 (37.2%) | 36 (41.9%) |
| InferROI | 46 (53.5%) | 7 (8.1%) |
结果表明,LLM可以通过代码理解能力辅助定位resource操作,但是LLM的推理能力依旧不足以进行漏洞检测。
1.5.Discussion
某些类型的资源泄漏可能会被漏报。例如,在Android回调中发生的资源泄漏代表了一个具有挑战性的领域,InferROI的轻量级静态分析可能会失败。
2.Latte
paper地址
-
SSF: security sensitive functions,安全敏感函数,sink点
-
EIS: external input source,外部输入,source点
-
PS: prompt sequence
-
DF: dangerous flow
2.1.Motivation
污点分析的复杂性和多样性以及其依赖人工定义污点规则的限制仍然阻碍了二进制污点分析工具器的整体性能。以下图中的整数溢出漏洞为例。
void bad(void) {
signed char a, b, c, d;
int e;
bool f;
a = ' ';
fscanf(stdin, "%c", &a);
b = a;
a = '0x1';
e = b + '0x1';
printf("%d\n", (ulong)e);
//No integer overflow after type conversion
if (b == '0x7f'){
printLine("data value is too larger" );
}
else {
c = b + '0x1';
printf("%02x\n", (ulong)(uint)(int)c);
//No integer overflow after sanitization
}
return ;
}
-
1.Source点-识别source以及分配污点label:在二进制文件中
-
手动识别接收外部输入的污点源是一个繁琐的过程。不仅标准的C/C++函数(如
recv、fscanf和fgets)可以接收外部数据,第三方函数(例如 OpenSSL 中的SSL_read和BIO_read)也可以接收外部数据。 -
更重要的是,确定返回值和参数的初始污点标签需要深入理解源语义。例如,只有了解
fscanf的语义,我们才能确定fscanf的第三个参数a(第6行)被污染。 -
请注意,确定第三方函数的初始污点标签比标准C/C++函数更具挑战性,因为前者通常没有文档,而后者至少在C/C++语言标准中有所记录。错误的标记经常导致数据的污点信息被错误地传播。
-
-
2.Propagation and Sanitization-定义污点传播规则:
- 污点标签可以通过赋值
b = a和算数运算e = b + 0x1传播,这可以通过数据依赖性分析自动识别。但是传播污点标签的过程不仅涉及标签传递,还涉及标签净化。 - 除了直接将安全数据分配或复制到污染区域(
a = 0x1)导致的净化外,还有与语义相关的净化情况。例如,if (b == 0x7f)排除了c = b + 0x1溢出的可能。之前的工作 (EmTaint, SATC, Karonte)忽略了这些语义净化的情况,从而导致了许多误报。而手动定义净化操作繁琐复杂。
- 污点标签可以通过赋值
-
3.Sink点-识别sink:和source一样,现有sink识别方法同样依赖人工标注,而不同类型漏洞需要不同的sink定义,它不仅包含标准库函数 (
printf),还有不同第三方库函数,如OpenSSL中的BIO_printf。要检查printf("%d\n", (ulong)e)调用是否会引发CWE-134漏洞,需要检查printf的第一个参数是否被污染;要检查基于第一个参数%d的调用是否会引发CWE-190漏洞,首先需要检查printf的第二个参数是否被污染,如果是污染的,还需要进一步检查该参数的计算过程是否溢出。需要注意的是,仅依赖于人类经验来理解和制定准确和全面的检查规则是不可扩展和可靠的。
2.2.Approach
dangerous flow: 一段涉及外部数据输入函数和可能导致漏洞的sink之间数据依赖链的函数链。
思路:首先基于LLM识别source和sink并构造一系列dangerous flow (func1 --> func2 --> func3),随后通过LLM逐函数分析dangerous flow。
2.2.1.Function Chain Generation
- Vulnerable Destinations Identification (sink):
难点: 安全敏感类函数的识别通常依赖于动态链接库
solution:
- 对于动态链接库调用,函数名得意保留,Latte prompt LLM分析该函数是否可能成为sink;如果可能,LLM返回其可能导致漏洞的参数索引。
- 对于静态链接库调用,LLM直接对库函数代码进行分析并摘要,识别是否成为sink以及导致漏洞的参数索引。
输出结果为一个 List[Tuple[str, str]],每个元素表示 (func_name, para)。比如,(system, 1) 表示 system 调用的第一个参数可能导致漏洞。func_name 为一个SSF (sink)。
随后,Latte识别所有的SSF的调用点。每个调用位置以 (Loc;SSF;Arg) 的形式保存,比如,(0x12345678;system;local_1),表示 system 在 0x12345678 处调用,参数 local_1 需要进行污点验证。
- Backward Tracing:
获取每个SSF调用危险参数的数据依赖指令集合。
steps:
-
1.构建call graph
-
2.递归的过程间分析,直到没有跟当前caller的参数发生数据依赖或者找不到caller。
2.2.2.Dangerous Flow Generation
- Source Identification
使用LLM找到能够接收外部输入或者生成伪随机数的函数。返回值也是个 tuple。比如,(recv, 2) 表示 recv 第2个参数用来接收外部输入。
- Matching and Deduplication
从对应的function call chain中提取危险data flow。
-
对于function call chain中的每个caller,识别是否调用了EIS。如果是,分析EIS的对应参数是否可达sink的对应参数。如果是,那么生成对应危险data flow。
-
生成data flow时,每个function call chain保留最长的一个。
2.2.3.Prompt Sequence Construction
基于危险data flow识别漏洞。
prompt template:
每个prompt用来分析一个函数,如果一个dangerous flow有多个函数
start prompt:
As a program analyst, I give you snippets of C code generated by decompilation, using {start} as the taint source, and {parameter} marked as the taint label to extract the taint data flow. Pay attention to the data alias and tainted data operations. Output in the form of data flows.
-
start: source函数 -
parameter: 参数
middle prompt
Continue to analyze {function} according to the above taint analysis results. Pay attention to the data alias, tainted data operations, and {sources}.
function: callee function函数体。
end prompt
Based on the above taint analysis results, analyze whether the code has vulnerabilities. If there is a vulnerability, please explain what kind of vulnerability according to CWE.
2.3.Evaluation
Latte基于Ghidra和GPT-4.0实现,通过编写Ghidra插件(约2500行python代码)加载和分析二进制文件。Ghidra允许从二进制文件中提取反编译代码、控制流程图、导入表、堆栈帧和其他相关的信息供后续分析。使用GPT-4.0的API,Latte自动识别二进制中的SSF (sink)和EIS (source)。之后,LATTE执行反向数据依赖性分析来跟踪SSF调用点的数据流。dangerous flow代表可能导致漏洞的潜在程序路径。根据提取的dangerous和prompt模板,Latte构造prompt序列,以引导GPT-4.0进行漏洞检查。GPT-4.0在提供的指令上下文中分析代码段并执行检查以识别潜在漏洞。
数据集:
-
Juliet:也就是SARD,作者选用了CWE-78, CWE-134, CWE-190, CWE-606),作者同时删除了常量source的testcase(Juliet中有的代码直接将常量当作source,没有外部输入)。
-
Karonate:Karonte数据集包括了来自NETGEAR、D-Link、TP-Link和Tenda等流行厂商的real-world嵌入式设备固件数据集。数据集由49个基于Linux的固件样本组成。
作者选用了Arbiter和Emtaint作为baseline。
2.3.1.RQ1.Latte漏洞检测性能
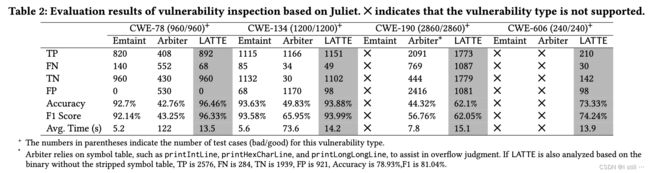
与Emtaint和Arbiter相比,Latte在accuracy和F1分数方面表现更好,并支持更多的漏洞类型。在CWE-190的情况下,Arbiter能检测到更多的true positive。然而,这是因为Arbiter依靠符号表进行检查,如果将此信息提供给Latte,Latte可以检测到2576个真阳性,从而超越Arbiter。
2.3.2.SSF和EIS识别(source-sink识别)准确度
Latte以平均78%的精度自动识别SSF和EIS。识别结果100%正确覆盖了测试目标场景中的SSF和EIS。
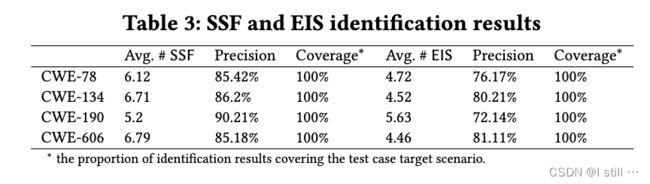
在一些情况下,GPT-4错误地认为 recv 是一个SSF (sink),导致了误报。Emtaint和Arbiter依赖于手工定义source和sink,但Latte的标识结果可以帮助这些技术减少人工工作量。通过提供更精确和自动化SSF和EIS标识,Latte有助于简化漏洞分析流程并提高其他技术的效率。
2.3.3.RQ3.Dangerous Flow提取精度
下图结果显示,Latte提取dangerous flow的准确率达到95%。

错误主要来源于两方面:
-
Ghidra反编译错误:在解析函数调用的参数时出现错误,导致无法追踪数据依赖。
-
纯虚函数调用:这些函数没有函数体,需要在子类具体实现。
2.3.4.RQ4.Real world漏洞检查
在Karonte的真实世界固件数据集上的评估中,Latte超过了Karonte、Emtaint和Arbiter,在49款固件上发现了119个独特的漏洞(包括CWE-78和CWE-120),并且覆盖了Karonte和Arbiter发现的所有漏洞。由于指针别名问题,Latte未能找到由Emtaint引发的16个漏洞。
Latte找到了37个以前未知的漏洞,7个被分配CVE编号。Latte的假阳性率和总分析时间为12.9% 和26.1小时,分别优于Karonte和Arbiter,但略逊于Emtaint。然而,Emtaint产生的警报和FP数量超过Latte,使得Latte更容易让分析师使用。此外,Latte提供了有价值的自然语言描述分析信息,帮助分析结果。
作者使用一个由Latte发现的真实漏洞作为例子来说明LLM污点分析的优势。不过由于页面限制,只放出了GPT-4的response。
函数语义描述:
The function FUN_0001bab0 takes a single parameter, a pointer to a char (char *param_1), and returns an undefined4 type value. The function appears to be checking the status of a process based on a file. The function can return three different values: 0, 0xffffffff, and 0xfffffffe. Here’s an analysis of the function: 1. If the input parameter (param_1) is NULL or an empty string, the function returns 0xffffffff. 2. If the parameter is not NULL or empty, the function attempts to open the file specified by the parameter
(param_1) in read-only mode (0). Omitted
漏洞分析结果
Based on the provided code snippet, there is a potential vulnerability related to CWE-120 (Buffer Copy without Checking Size of Input). The vulnerability arises from the following code block: memset(acStack_50,0,0x40); sVar2 = read(__fd,acStack_50,0x3f); Here, the buffer acStack_50 has a size of 68 bytes, and the code attempts to read up to 63 bytes from the file into the buffer. Omitted... To mitigate this vulnerability, you can add a null terminator explicitly after the read operation: sVar2 = read(__fd,acStack_50,0x3f); acStack_50[sVar2] = ’0’; By adding the null terminator, you ensure that string manipulation functions will not read past the buffer’s boundary, preventing potential buffer overflow issues.
从响应中,可以看到GPT-4不仅分析了 FUN_0001bab0 的数据流和控制流,还分析了调用者和被调用者、变量名和输出信息来理解函数的语义。根据对函数的理解,GPT-4通过污点分析进行漏洞检查。给出了漏洞触发路径和数据依赖项,还包括修复意见,这极大地帮助分析师识别和修复漏洞。
2.4.Discussion
虽然效果相比Emtaint等污点分析工具提升了,但Latte可能在处理诸如逻辑漏洞以及涉及复杂数学运算的竞争型漏洞(如时间窗口竞争)依旧存在问题。这些漏洞通常涉及复杂的嵌套和跳跃代码段,使得LLM难以有效地分析。另外,由于缺乏此类漏洞的公开信息,LLM在这方面的分析能力有限。
3.GPTScan
paper地址
这篇工作主要是将传统静态分析中一些需要形式化定义的规则利用GPT转换成通过自然语言描述。
3.1.Motivation
function deposit ( uint256 _amount ) external returns (uint256 ) {
uint256 _pool = balance();
uint256 _before = token.balanceOf(address(this));
token.safeTransferFrom(msg.sender, address(this), _amount);
uint256 _after = token.balanceOf(address(this));
_amount = _after.sub(_before); // Additional check for deflationary tokens
uint256 _shares = 0;
if (totalSupply() == 0) {
_shares = _amount;
} else {
_shares = (_amount.mul(totalSupply())).div(_pool);
}
_mint(msg.sender, _shares);
}
if (totalSupply() == 0) _shares = _amount; 这一句可能触发异常,static analysis tool会使用hard-coded patterns来检测 totalSupply() 逻辑。而这里有必要使用 GPT 来识别负责保管存款金额的变量 _amount 以及池中的总份额 _shares。但是GPT分析不出 totalSupply() == 0 和 _shares = _amount; 中的逻辑关系。
function transfer(address account, uint256 amount) external override notPaused returns(bool) {
require(msg.sender != account, Error.SELF_TRANSFER_NOT_ALLOWED);
require(balances[msg.sender] >= amount, Error.INSUFFICIENT_BALANCE );
// Initialize the ILiquidityPool pool variable
pool.handleLpTokenTransfer(msg.sender, account, amount);
balances[msg.sender] -= amount;
balances[account] += amount;
address lpGauge = currentAddresses[_LP_GAUGE];
if (lpGauge != address(0)) {
ILpGauge(lpGauge).userCheckpoint(msg.sender);
ILpGauge(lpGauge).userCheckpoint(account);
}
emit Transfer(msg.sender, account, amount);
return true;
}
ILpGauge(lpGauge).userCheckpoint(msg.sender); 应该在 balances[msg.sender] -= amount; 前执行。这里GPT有助于理解代码的语义。但是不能理解before这个概念。因此,需要static analysis来确认执行顺序。
3.2.Overview and Challenge
GPTScan的输入为一个智能合约project, 可能是一个solidity file或者 一个包含多个文件的framework-based 智能合约project。大致步骤为:
-
contract parsing + call graph analysis:计算function的可达性,过去获得candidate function set。
-
GPT-based Scenario and Property Matching:匹配candidate function与pre-abstracted scenarios以及相关漏洞类型。
-
Static Confirmation:识别matched function中的key variable以及statements。随后通过static analysis module进行验证。
需要解决的challenge包括:
-
C1:上下文长度限制-一个project可能包含若干solidity文件,一次输入GPT是不可能的。以及,没有非漏洞函数可能会影响GPT的检测能力。how to effectively narrow down the candidate functions for GPT matching becomes essential.
-
C2:现有GPT-based漏洞检测方法会输入一个high-level漏洞描述。这要么要求GPT具有好的推理能力,要么要求预训练好的漏洞知识。can we break down vulnerability types in a manner that allows GPT, as a generic and intelligent code understanding tool, to recognize them directly from code-level semantics?
-
C3:考虑到 GPT 可能产生不可靠的答案或无法识别类似功能的差异。further confirming the matched potential vulnerabilities becomes critical.
3.3.Function Matching & Static Confirmation
GPTScan 采用了一种不同的方法,将将漏洞类型分解为code-level场景和属性。
-
scenarios(场景)描述可能出现逻辑漏洞的代码功能
-
properties(属性)来描述的代码属性或操作
prompt trick:mimic-in-the-background
利用GPT识别出相关场景和属性有关的变量以及语句。再用static analysis来验证合法性,验证包括:
-
Static Data Flow Tracing (DF): 验证GPT提供的变量或者表达式是否具有数据依赖关系。
-
Value Comparison Check (VC):验证GPT提供的变量是否进行了比较。
-
Order Check (OC): 检查GPT提供的语句的执行先后顺序。
-
Function Call Argument Check (FA): 检查函数参数是否受外部控制。