数据仓库基础理论
前端时间,使用阿里云MaxCompute做数据仓库,处理大数据的分析处理,整理一下数据仓库的基础理论。
BI(Business Intelligence 商业智能)的作用
操作性数据特点:细节化,分散化;
决策性数据:综合化,集成化;
企业对应用继承的需求:1,实时监控;2,决策支持;3,预测;
现有应用系统无法达到企业的要求:1,数据分散;2,数据不兼容;3,系统应用孤立;
BI:
1,通过集成实时与历史数据,将分析转换为执行力;
2,洞察力:获得对业务绩效、流程和客户的可见性和洞察力;更好的进行决策和执行决策,以快速应对机会和挑战;
3,协同一致:横跨多个业务和数据源,获得唯一的、一致的企业信息;在各业务层面中协同战略和执行;
BI技术集合:ETL、DW、OLAP、DM等环节。
数据仓库(Data warehouse)是一个 面向主题 的、集成的、相对稳定的、反映历史变化的数据集合,用于支撑管理决策。
面向主题:数据有维度;
集成:数据从各种系统,不同存储方式获取来,最后统一集成到一起;
相对稳定:一般只有录入和查询,录入后一般不修改和删除;
反映历史变化:操作性数据关注某一时间段内的数据;而决策性数据通常包含历史信息,系统记录了过去某一个时点到目前的各个阶段的信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
数据仓库理论
基本架构图
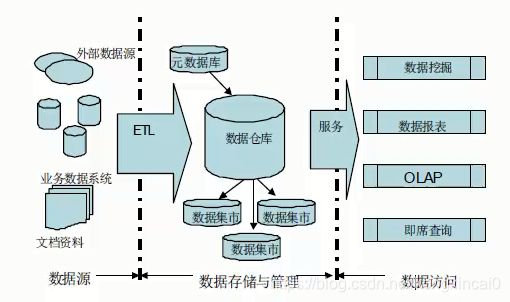
数据源:企业操作型数据库中的各种生产运营数据、办公管理数据和一些调查数据、市场信息等;主要是一些系统和文件数据;
数据存储与管理:数据仓库的存储主要由元数据的存储及数据的存储两部分组成。元数据是描述数据的数据,其内容主要包括数据仓库的数据字典、数据的定义、数据的抽取规则,数据的转换规则、数据的加载频率等信息。
数据的访问:由OLAP(联机分析处理)、数据挖掘、统计报表、即席查询等几部分组成。
相关概念
企业信息工厂:企业信息工厂主要包括:集成转换层(I&T)、操作数据存储(ODS)、企业级数据仓库(EDW)、探索仓库(EW)等部件。(流向方向)
集成转换层的目的是将来自操作性源系统的数据集成转换到数据仓库中,它通常由一组程序组成。集成转换层包括程序和数据,也称数据准备区(Data Staging Area),通常中等规模及以上的数据仓库都会简历准备区。
操作数据存储(ODS)是建立在数据准备区和数据仓库之间的一个部件,用来满足企业集成的、综合的操作型处理需要。可选部件,用来满足企业战术决策的需要。
企业级数据仓库是企业信息工厂的核心部件,用来保存企业的数据。一般,也称数据仓库,是用来满足企业战略决策的需要。数据仓库的数据来自数据准备区和操作数据存储。
数据集市是为了满足企业特定部门的分析需求而专门建立的数据的集合。数据集市的数据来源是数据仓库。企业信息工厂中的数据集市一般来说是非规范化的、定制的和汇总的。而多维体系架构中的数据集市分为两种,分别是原子数据集市和聚集数据集市。一般来说企业信息工厂中的数据集市相当于多维体系架构中的聚集数据集市。
探索仓库或数据挖掘仓库的建立主要是为了解决大型查询、提高数据仓库的效率,当有探索或挖掘需求时,会从数据仓库到处一部分数据提供给他们操作。
维:
https://blog.csdn.net/czmmiao/article/details/84406369?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
缓慢变化维(Slowly Changing Dimension):当某个维度基本固定,很少变化时,我们认为他为缓慢变化维。比如区域维度;
快速变化维(Rapidly Changing Dimension):当某个维度变化非常快的时候,我们认定他为快速变化维(具体要看实际的变化频率)。比如:客户的地址、联系电话等。
大维(Huge Dimension)和微型维(Mini-Dimesion):数据仓库中最有意思的维度是一些非常大的维度,比如客户,产品等等。一个大的企业客户维度往往有上百万记录,每条记录又有上百个字段。而大的个人客户维度则会超过千万条记录,这些个人客户维度有时也会有十多个字段,但是大多数时候比较少见的维度也只有不多的几个属性。
将分析频率比较高或者变化频率比较高的字段提取出来,建立一个单独的维度表。这个单独的维度表就是微型维度表。
退化维(Degenerate Dimension):退化维度一般都是事务的编号,如订单编号、发票编号等。这类编号需要保存到事实表中,不需要对应的维度表,所以称为退化维度。
事实表:
在维度建模的数据仓库中,事实表是指其中保存了大量业务度量数据的表。事实表中的度量值一般称为事实。在事实表中最有用的事实就是数字类型的事实和可加类型的事实。事实表的粒度决定了数据仓库中数据的详细程度。
一般来说,以粒度作为划分依据,主要有三种事实表,分别是:事务粒度事实表(Transaction Grain Fact Table),周期快照粒度事实表(Periodic Snapshot Grain Fact Table)和累计快照粒度事实表(Accumulating Snapshot Grain Fact Table);从用途的不同来说,事实表可以分为三类,分别是原子事实表,聚集事实表和合并事实表。
原子事实表(Atim Fact Table):是保存最细粒度数据的事实表,也是数据仓库中保存原子信息的场所。
聚集事实表(Aggregated Fact Table):是原子事实表上的汇总数据,也称为汇总事实表。(按时间、按区域、按部门等)。即新建立一个事实表,它的维度表是比原维度表要少,或者某些维度表是原维度表的子集;事实数据是相应事实的汇总,即求和或求平均值等;在做数据迁移时,当相关的维度数据和事实数据发生变化时,聚集事实表需要做相应的刷新。合并事实表是将处于不同事实表中,处于相同粒度的事实进行组合建模而成的一种事实表。(宽表)
旋转事实表(pivoted fact table)是将一条记录中的多个事实字段转化为多条记录,其中每条记录保存一个事实字段的一种建模方式;或者发过来,也可以由多条记录转化为一条记录。
预连接聚聚表(pre-joined aggregated table)是通过对事实表和维度表的联合查询而生成的一类汇总表。在预连接聚集表中,保存有维度表中的描述信息和事实表中的事实值。(提高性能,避免查询时RDBMS的连接操作)
切片事实表(sliced fact table):字段结构与相应的基础表完全相同,差别在于存储的记录的范围。切片事实表中保存记录的是相应基础表中记录的子集,记录数通常与某个维度记录数相同。
蜈蚣事实表(Centipede fact table):指那些一张事实表中有太多维度的事实表,连接在事实表两边的维度过多,看起来像蜈蚣一样。一般来说,事实表相关的维度在15个以下为正常,如果维度数据超过25个,就出现维度过多的蜈蚣事实表。
一致性事实(Conformed Fact):一致性事实是Kimball的多维体系结构(MD)中的三个关键性概念之一,另两个是总线架构(Bus Architecture)和一致性维度(Conformed Dimension)
一致性事实和一致性维度有些不同,一致性维度是由专人维护在后台(Back Room),发生修改时同步复制到每个数据集市,而事实表一般不会在多个数据集市间复制。需要查询多个数据集市中的事实时,一般通过交叉探查(drill across)来实现。
为了能在多个数据集市间进行交叉探查,一致性事实主要需要保证两点。第一个是KPI的定义及计算方法要一致,第二个是事实的单位要一致。如果业务要求或事实上就不能保持一致的话,建议不同单位的事实分开建立字段保存。
这样,一致性维度将多个数据集市结合在一起,一致性事实保证不同数据集市间的事实数据可以交叉探查,一个分布式的数据仓库就建成了。
数据集市:
数据集市(Data mart)也叫做“小数据仓库”。如果说数据仓库是建立在企业级的数据模型之上的话,那么数据集市就是企业级数据仓库的一个子集,主要面向部门级业务,并且只面向某个特定的主题。数据集市可以在一定程度上缓解访问数据仓库的瓶颈。
即席查询(Ad hoc queries):是指那些用户在使用系统时,根据子集当时的需求定义的查询。
**特点:**即席查询与批处理脚本/普通应用查询最大的不同是普通的应用查询是定制开发的(即查询语句是预先写好的,不会临时变化),而即席查询是由用户自定义查询条件的。
即席查询与普通查询从SQL语句上来说,并没有本质的差别。它们之间的差别在于,普通查询在系统设计和实施时是已知的,所有可以在系统实施时通过建立索引、分区等技术来优化这些查询,使这些查询的效率很高。而即席查询是用户在使用时临时生产的,无法人工预先优化这些查询,需要数据库内部实时自动优化,所以即席查询也是评估数据仓库的一个重要指标。在一个数据仓库系统中,即席查询使用的越多,对数据仓库的要求就越高,对数据模型的对称性的要求也越高。
ODS:
元数据:
元数据是关于数据的数据。元数据可以看作是数据仓库系统的数据字典,但不再仅仅表示数据的类型、名称、值等信息,它进一步描述了数据的上下文描述信息,比如数据所属区域、取值范围、数据间的关系、业务规则、甚至数据的来源信息等。可以帮助数据仓库管理员和数据仓库的开发人员非常方便的找到他们锁关心的数据;并可以回答最终用户数据仓库中有那些数据,这些数据从哪里来等重要的问题。
按用途不同分为两类:技术元数据(Technical Metadata)和业务/商业元数据(Business Metadata)。
技术元数据:技术元数据是存储关于数据仓库系统技术细节的数据,是用于开发和管理数据仓库使用的数据,主要包括一下数据:
1)数据仓库结构的描述,包括仓库模式、视图、维、层次结构和导出数据的定义,以及数据集市的位置和内容;
2)业务系统、数据仓库和数据集市的体系结构和模式;
3)汇总用的算法,包括度量和维定义算法,数据粒度、主题领域、聚集、汇总、预定的查询与报告;
4)由操作环境到数据仓库环境的映射,包括元数据和它们的内容,数据分割、数据提取、清理、转换规则和数据刷新规则、安全(用户授权和存取控制)。
业务/商业元数据:从业务角度描述了数据仓库中的数据,它提供了介于使用者和实际系统之间的语义层,使得不懂计算机技术的业务人员也能够读懂数据仓库中的数据。主要包括以下信息:使用者的业务术语所表达的数据模型、对象名和属性名;访问数据的原则和数据的来源;系统所提供的分析方法以及公式和报表的信息;具体包括以下信息:
1)企业概念/逻辑模型:这是业务/商业元数据所有应提供的重要的信息,它表示企业数据模型的高层信息、整个企业的业务概念和相互关系。以这个企业模型为基础,不懂数据库技术和sql语句的业务人员对数据仓库中的数据也能做到心中有数。
2)多维数据模型:这是企业概念模型的重要组成部分,它告诉业务分析人员在数据集市当中有那些维、维的类别、数据立方体以及数据集市中的聚合规则。这里的数据立方体表示某主题领域业务事实表和维表的多维组织形式。
3)业务概念模型和物理数之间的映射、依赖:以上提到的业务/商业元数据只是表示出了数据的业务视图,这些业务视图与实际的数据仓库或数据库、多维数据库中的表、字段、维、层次等之间的对应关系也应该在元数据知识库中有所体现。
可能采用元数据管理系统,或者通过git等来管理,或者通过excel等来记录相关信息;
ETL:
ETL是将业务系统的数据经过抽取(Extract)、清洗转换(Transform)之后加载(Load)到数据仓库的过程。目的是将企业中的分散、零乱、标准不一的数据整合到一起,为企业的决策提供分析依据。ETL是BI项目重要的一个环节。通常情况下,在BI项目中ETL会花掉整个项目的1/3的时间,ETL设计的好坏直接关系到BI项目的成败。
需要补充。
OLAP:
OLAP(联机分析处理,On-Line Analytical Processing):用户的决策分析需要对关系数据库进行大量计算才能得到结果,而查询结果并不能满足决策者提出的需求。因此,E.F.Cdd1993年提出了多维数据库和多维分析的概念,即OLAP。OLAP是使分析人员、管理人员或执行人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映企业维特性的信息进行快速、一致、交互的存取,从而获得对数据的更深入的了解的一类软件技术。
OLAP的目标:是满足决策支持或多维环境特定的查询和报表需求,它的技术核心是“维”这个概念,因此OLAP也可以说是多维数据分析工具的集合。
OLTP与OLAP的不同点:
| OLTP数据 | OLAP数据 |
|---|---|
| 原始数据 | 导出数据 |
| 细节性数据 | 综合性和提炼性数据 |
| 当前值数据 | 历史数据 |
| 一次性处理的数据量小 | 一次性处理的数据量大 |
| 可更新 | 不可更新,但周期性刷新 |
| 面向应用,事务驱动 | 面向分析,分析驱动 |
| 面向操作人员,支持日常操作 | 面向决策人员,支持管理需要 |
维:是人们观察数据的特定角度,是考虑问题时的一类属性,属性集合构成一个维(时间维、地理维等)
维的层次:人们观察数据的某个特定角度(即某个维)还可以存在细节程度不同的各个描述方面(时间维:日期、月份、季度、年)。
维的成员:维的一个取值。是数据项在某个位置的描述。(“2020-11-11”是在时间维上位置的描述)
多维数组:维和变量的组合表示。一个多维数据可以表示为:(维1,维2,…,维n,变量)。(时间、地区、产品,销售额)
数据单元(单元格):多维数据的取值。(2020-11-11、武汉、笔记本,$1000000)
OLAP的特性:
快速性:用户对OLAP的快速反映能力有很高的要求。系统应能在5秒内对用户的大部分分析要求做出反应。(专门的数据存储格式、大量的事先运算、特别的硬件设计等)
可分析性:OLAP系统应能处理与应用有关的任何逻辑分析和统计分析。尽管系统需要事先编程,但并不意味着系统已定义好了所有的应用。用户无需编程就可以定义新的专门的计算,将其作为分析的一部分,并以用户立项的方式给出报告。用户可以在OLAP平台上进行数据分析,也可以连接到其他外部分析工具上。
多维性:多维性是OLAP的关键属性。系统必须提供对数据的多维视图和分析,包括对层次维和多重层次维的完全支持。
信息性:不论数据量有多大,也不管数据存储在何处,OLAP系统应能及时获得信息,并且管理大容量信息。这里有许多因素需要考虑,如数据的可复制性、可利用的磁盘空间、OLAP产品的性能与数据仓库的结合度等。
OLAP多维数据结构:超立方结构(Hyper cube)和多立方结构(Multi cube)
超立方结构:超立方结构是指用三维或者更多的纬数来描述一个对象,每个维彼此垂直。数据的测量值发生在维的交叉点上,数据空间的各个部分都有相同的维属性。
多立方结构:即将超立方结构变为子立方结构。面向某一特定应用对维进行分割,它具有很强的灵活性,提高了数据(特别是稀疏数据)的分析效率。
一般来说,多立方结构灵活性较大,但超立方结构更易于理解。
许多产品结合了上述两种结构,它们的数据物理结构是多立方结构,但却利用超立方结构来进行计算,结合了超立方结构的简化性和多立方结构的旋转存储特性。
OLAP多维数据分析:切片和切块(slice and Dice)、钻取(Drill)、旋转(Rotate)/转轴(Pivot);
切片和切块:多维数据结构中,在一部分维上选定值后,关心度量数据在剩余维上的分布,如果剩余的维只有两个,则是切片;如果有三个,则是切块。如在“城市、产品、时间”三维立方体中进行切片到各个城市、各产品的销售情况。
钻取:它是改变维的层次,变换分析的粒度。钻取包括向下钻取(Drill-down)和向上钻取(Drill-up)/上卷(Roll-up)操作,roll up是在某一维上将低层次的细节数据概括到高层次的汇总数据,或者减少纬数;而drill down则相反,它从汇总数据深入到细节数据进行观察或者增加新维。
旋转/转轴:旋转是变换维的方向,即在表格中重新安排维的方式(例如行列互换),通过旋转可以得到不同视角的数据。
OLAP的多种实现方法,根据存储数据的方式不同分为:ROLAP、MOLAP、HOLAP;
ROLAP表示基于关系数据库的OLAP实现(Relational OLAP)。以关系数据库为核心,以关系型结构进行多维数据的表示和存储。ROLAP将多维数据库的多维结构划分为两类表:一类是事实表,用来存储数据和维关键字;另一类是维表,即对每个维至少使用一个表来存放维的层次、成员类别等维的描述信息。维表和事实表通过主关键字和外关键字联系在一起,形成了“星型模型”。对于复杂的维,为了避免荣誉数据占用过大的存储空间,可以使用多个表来描述,这种星型模型扩展称为“雪花模型”。(星型模型数据冗余多,但查询时关联的表少,性能优于雪花模型)
MOLAP表示基于多维数据组织的OLAP实现(Multidimensional OLAP),以多维数据组织方式为核心,也就是说,MOLAP使用多维数组存储数据。多维数据在存储中将形成“立方块(Cube)”的结构,在MOLAP中对立方块的“旋转”、“切片”、“切块”是产生多维数据报表的主要技术。(性能好)(占用大量空间)
HOLAP表示基于混合数据组织的OLAP实现(Hybrid OLAP)。如底层是关系型的,高层是多维矩阵型的。这种方式具有更好的灵活性。
多维数据库(Multi Dimesional Database,MDD)可以简单理解维:将数据存放在一个n维数组中,而不是像关系数据库那样以记录的形式存放。
流行的OLAP工具:Hyperion Essbase、Oracle Express、IBM DB2 OLAP Server、Microsoft analysis services、Brio、Cognos、Business Object、MicroStrategy。
维度建模基础理论
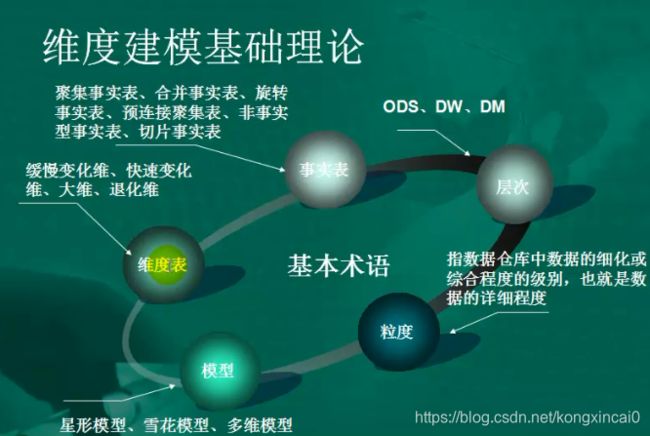
维度表:维度表可以看作是用户分析数据的窗口,维度表中包含事实数据表中事实记录的特性,有些特性提供描述性信息,有些特性指定如何汇总事实数据表数据,以便为分析者提供有用的信息。
粒度:粒度是指数据仓库中数据的细化或综合程度的级别,也就是数据的详细程度。粒度越小,数据量越大,存储空间越大,查询性能越慢,反之亦然。
模型种类:
ROLAP表示基于关系数据库的OLAP实现(Relational OLAP)。以关系数据库为核心,以关系型结构进行多维数据的表示和存储。ROLAP将多维数据库的多维结构划分为两类表:一类是事实表,用来存储数据和维关键字;另一类是维表,即对每个维至少使用一个表来存放维的层次、成员类别等维的描述信息。维表和事实表通过主关键字和外关键字联系在一起,形成了“星型模型”。对于复杂的维,为了避免荣誉数据占用过大的存储空间,可以使用多个表来描述,这种星型模型扩展称为“雪花模型”。
在数据仓库分层分析处理的过程中,底层可以直接把原本有层级的维度导入过来,然后在较高层上面,做维度退化处理,将雪花模型变为星型模型,以提升查询效率。
建模的一般过程:
选择需要建模的业务过程,如:库存管理业务
1、确定该业务过程每个事实表的粒度:在建模之前最先考虑的问题;确定详细数据的粒度级别;比较典型的粒度是单独的,基于时间的或聚集在一个常用的维度的事务。基于业务的;
2、确定维度的属性:确定是否需要同时存储编号和描述,或者只编号,或者只是描述;确定那些字段的值需要被筛选掉或者需要存在。基于业务判断;
3、确定维度的层次:对于时间维度,我们需要确定的是年,季度,月,周,日等不同层次;对于产品维度,我们需要确定的是产品大类,产品小类,产品等不同的层次;需要注意的是比如在销售中,地理位置的层次可能和现实中的地理位置的层次会有不同。
4、确定每个事实所需要关联的维度:通常的维度包括时间,产品,客户和地理等常见对象;创建的维度需要和与其连接的事实的粒度保持一致;
5、确定数字型事实,包括预先计算的:需要根据业务来确定事实及其量度;对于每个聚合事实需要在应用(ETL)过程中进行计算;包括对于一些需要计算的事实,确定其量度,计算事实。
6、确定缓慢变化维:根据需求,对缓慢变化维进行相应的处理;比如:对于一个需求为不保留历史的客户维度,我们使用第一种类型的缓慢变化维来处理;(第一种就是直接覆盖原值);对于一个需求为需要保留历史的产品维度,我们需要使用第二种类型的缓慢变化维来处理;(第二种就是保留历史维度数据)
常见数据仓库分层
ODS层:
原始数据层,存放原始数据,直接加载原始数据,数据保持原貌不做处理;
DWD层:
明细数据层,主要是对原始数据进行拆分,形成维度表和原始事实表;并对数据进行清洗(去除空值,脏数据,超过极限范围的数据)
DWS层:
服务数据层,以明细数据为基础,进行轻度汇总,形成一些宽表等,方便后续统计;
ADS层:
数据应用层,从业务的角度,在DWS层的数据上进行查询统计,生成的表,为各种统计报表等提供数据。
数据仓库分层的好处:
1,化繁为简:所有分层结构都存在的好处:复杂的任务拆分后分步完成,每一层处理每一层的任务,化繁为简;
2,减少重复开发:避免了所有针对业务的数据都从原始数据开始一步步处理,每一层在上一层的基础上完成。
3,隔离原始数据:由于分层隐藏了原始数据,使得应用数据与原始数据解耦,屏蔽了敏感数据,也避免原始数据被破坏。
在阿里云数据仓库里面,这4层应该都在MaxCompute(原名ODPS)里面计算和处理分析。
小结
以上整理了基础的数据仓库知识,在实际使用阿里云MaxCompute时比对着去做。对阿里云maxCompute想要进一步了解的可以看看帮助文档:https://help.aliyun.com/product/27797.html