极速开发扩充 Apache DolphinScheduler Task 类型 | 实用教程
点击蓝字 关注我们

背景简介
目前在大数据生态中,调度系统是不可或缺的一个重要组件。Apache DolphinScheduler 作为一个顶级的Apache 项目,其稳定性和易用性也可以说是名列前茅的。而对于一个调度系统来说,能够支持的可调度的任务类型同样是一个非常重要的因素,在调度、分布式、高可用、易用性解决了的情况下,随着业务的发展或者各种需求使用到的组件增多,用户自然而然会希望能够快速、方便、简洁地对 Apache Dolphinscheduler 可调度的任务类型进行扩充。本文便带大家了解如何方便、极速扩充一个 Apache DolphinScheduler Task。
作者简介

张柏强,大数据开发工程师,主要研究方向为实时计算、元数据治理、大数据基础组件。
1
什么是 SPI 服务发现(What is SPI)?
SPI 全称为 (Service Provider Interface) ,是 JDK 内置的一种服务提供发现机制。大多数人可能会很少用到它,因为它的定位主要是面向开发厂商的,在 java.util.ServiceLoader 的文档里有比较详细的介绍,其抽象的概念是指动态加载某个服务实现。
2
为什么要引入 SPI(Why did we introduce SPI)?
不同的企业可能会有自己的组件需要通过 task 去执行,大数据生态中最为常用数仓工具 Apache Hive 来举例,不同的企业使用 Hive 方法各有不同。有的企业通过 HiveServer2 执行任务,有的企业使用 HiveClient 执行任务,而 Apache DolphinScheduler 提供的开箱即用的 Task 中并没有支持 HiveClient 的 Task,所以大部分使用者都会通过 Shell 去执行。然而,Shell 哪有天然的TaskTemplate 好用呢?所以,Apache DolphinScheduler 为了使用户能够更好地根据企业需求定制不同的 Task,便支持了 TaskSPI 化。
我们首先要了解一下 Apache DolphinScheduler 的 Task 改版历程,在 DS 1.3.x 时,扩充一个 Task 需要重新编译整个 Apache DolphinScheduler,耦合严重,所以在 Apache DolphinScheduler 2.0.x 引入了 SPI。前面我们提到了 SPI 的抽象概念是动态加载某个服务的实现,这里我们具象一点,将 Apache DolphinScheduler 的 Task 看成一个执行服务,而我们需要根据使用者的选择去执行不同的服务,如果没有的服务,则需要我们自己扩充,相比于 1.3.x 我们只需要完成我们的 Task 具体实现逻辑,然后遵守 SPI 的规则,编译成 Jar 并上传到指定目录,即可使用我们自己编写的 Task。
3
谁在使用它(Who is using it)?
1、Apache DolphinScheduler
task
datasource
2、Apache Flink
flink sql connector,用户实现了一个flink-connector后,Flink也是通过SPI来动态加载的
3、Spring boot
spring boot spi
4、Jdbc
jdbc4。0以前, 开发人员还需要基于Class。forName("xxx")的方式来装载驱动,jdbc4也基于spi的机制来发现驱动提供商了,可以通过META-INF/services/java。sql。Driver文件里指定实现类的方式来暴露驱动提供者
5、更多
dubbo
common-logging
4
Apache DolphinScheduler SPI Process?
剖析一下上面这张图,我给 Apache DolphinScheduler 分为逻辑 Task 以及物理 Task,逻辑 Task 指 DependTask,SwitchTask 这种逻辑上的 Task;物理 Task 是指 ShellTask,SQLTask 这种执行任务的 Task。而在 Apache DolphinScheduler中,我们一般扩充的都是物理 Task,而物理 Task 都是交由 Worker 去执行,所以我们要明白的是,当我们在有多台 Worker 的情况下,要将自定义的 Task 分发到每一台有 Worker 的机器上,当我们启动 Worker 服务时,worker 会去启动一个 ClassLoader 来加载相应的实现了规则的 Task lib,可以看到 HiveClient 和 SeatunnelTask 都是用户自定义的,但是只有 HiveTask 被 Apache DolphinScheduler TaskPluginManage 加载了,原因是 SeatunnelTask 并没有去遵守 SPI 的规则。SPI 的规则图上也有赘述,也可以参考 java.util.ServiceLoader 这个类,下面有一个简单的参考(摘出的一部分代码,具体可以自己去看看)
public final class ServiceLoader implements Iterable {
//scanning dir prefix
private static final String PREFIX = "META-INF/services/";
//The class or interface representing the service being loaded
private final Class service;
//The class loader used to locate, load, and instantiate providers
private final ClassLoader loader;
//Private inner class implementing fully-lazy provider lookup
private class LazyIterator implements Iterator {
Class service;
ClassLoader loader;
Enumeration configs = null;
String nextName = null;
//......
private boolean hasNextService() {
if (configs == null) {
try {
//get dir all class
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
//......
}
//......
}
}
}
} 5
如何扩展一个 data sourceTask or DataSource (How to extend a task or datasource)?
5.1
创建 Maven 项目
mvn archetype:generate \
-DarchetypeGroupId=org.apache.dolphinscheduler \
-DarchetypeArtifactId=dolphinscheduler-hive-client-task \
-DarchetypeVersion=1.10.0 \
-DgroupId=org.apache.dolphinscheduler \
-DartifactId=dolphinscheduler-hive-client-task \
-Dversion=0.1 \
-Dpackage=org.apache.dolphinscheduler \
-DinteractiveMode=false5.2
Maven 依赖
org.apache.dolphinscheduler
dolphinscheduler-spi
${dolphinscheduler.lib.version}
${common.lib.scope}
org.apache.dolphinscheduler
dolphinscheduler-task-api
${dolphinscheduler.lib.version}
${common.lib.scope}
5.3
创建 Task 通道工厂(TaskChannelFactory)
首先我们需要创建任务服务的工厂,其主要作用是帮助构建 TaskChannel 以及 TaskPlugin 参数,同时给出该任务的唯一标识,ChannelFactory 在 Apache DolphinScheduler 的 Task 服务组中,其作用属于是在任务组中的承上启下,交互前后端以及帮助 Worker 构建 TaskChannel。
package org.apache.dolphinscheduler.plugin.task.hive;
import org.apache.dolphinscheduler.spi.params.base.PluginParams;
import org.apache.dolphinscheduler.spi.task.TaskChannel;
import org.apache.dolphinscheduler.spi.task.TaskChannelFactory;
import java.util.List;
public class HiveClientTaskChannelFactory implements TaskChannelFactory {
/**
* 创建任务通道,基于该通道执行任务
* @return 任务通道
*/
@Override
public TaskChannel create() {
return new HiveClientTaskChannel();
}
/**
* 返回当前任务的全局唯一标识
* @return 任务类型名称
*/
@Override
public String getName() {
return "HIVE CLIENT";
}
/**
* 前端页面需要用到的渲染,主要分为
* @return
*/
@Override
public List getParams() {
List pluginParams = new ArrayList<>();
InputParam nodeName = InputParam.newBuilder("name", "$t('Node name')")
.addValidate(Validate.newBuilder()
.setRequired(true)
.build())
.build();
PluginParams runFlag = RadioParam.newBuilder("runFlag", "RUN_FLAG")
.addParamsOptions(new ParamsOptions("NORMAL", "NORMAL", false))
.addParamsOptions(new ParamsOptions("FORBIDDEN", "FORBIDDEN", false))
.build();
PluginParams build = CheckboxParam.newBuilder("Hive SQL", "Test HiveSQL")
.setDisplay(true)
.setValue("-- author: \n --desc:")
.build();
pluginParams.add(nodeName);
pluginParams.add(runFlag);
pluginParams.add(build);
return pluginParams;
}
} 5.4
创建 TaskChannel
有了工厂之后,我们会根据工厂创建出 TaskChannel,TaskChannel 包含如下两个方法,一个是取消,一个是创建,目前不需要关注取消,主要关注创建任务。
void cancelApplication(boolean status);
/**
* 构建可执行任务
*/
AbstractTask createTask(TaskRequest taskRequest);public class HiveClientTaskChannel implements TaskChannel {
@Override
public void cancelApplication(boolean b) {
//do nothing
}
@Override
public AbstractTask createTask(TaskRequest taskRequest) {
return new HiveClientTask(taskRequest);
}
}5.5
构建 Task 实现
通过 TaskChannel 我们得到了可执行的物理 Task,但是我们需要给当前 Task 添加相应的实现,才能够让Apache DolphinScheduler 去执行你的任务,首先在编写 Task 之前我们需要先了解一下 Task 之间的关系:
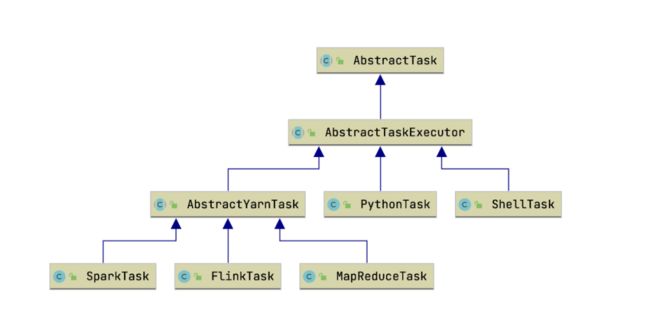
通过上图我们可以看到,基于 Yarn 执行任务的 Task 都会去继承 AbstractYarnTask,不需要经过 Yarn 执行的都会去直接继承 AbstractTaskExecutor,主要是包含一个 AppID,以及 CanalApplication setMainJar 之类的方法,想知道的小伙伴可以自己去深入研究一下,如上可知我们实现的 HiveClient 就需要继承 AbstractYarnTask,在构建 Task 之前,我们需要构建一下适配 HiveClient 的 Parameters 对象用来反序列化JsonParam。
package com.jegger.dolphinscheduler.plugin.task.hive;
import org.apache.dolphinscheduler.spi.task.AbstractParameters;
import org.apache.dolphinscheduler.spi.task.ResourceInfo;
import java.util.List;
public class HiveClientParameters extends AbstractParameters {
/**
* 用HiveClient执行,最简单的方式就是将所有SQL全部贴进去即可,所以我们只需要一个SQL参数
*/
private String sql;
public String getSql() {
return sql;
}
public void setSql(String sql) {
this.sql = sql;
}
@Override
public boolean checkParameters() {
return sql != null;
}
@Override
public List getResourceFilesList() {
return null;
}
} 实现了 Parameters 对象之后,我们具体实现 Task,例子中的实现比较简单,就是将用户的参数写入到文件中,通过 Hive -f 去执行任务。
package org.apache.dolphinscheduler.plugin.task.hive;
import org.apache.dolphinscheduler.plugin.task.api.AbstractYarnTask;
import org.apache.dolphinscheduler.spi.task.AbstractParameters;
import org.apache.dolphinscheduler.spi.task.request.TaskRequest;
import org.apache.dolphinscheduler.spi.utils.JSONUtils;
import java.io.BufferedWriter;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class HiveClientTask extends AbstractYarnTask {
/**
* hive client parameters
*/
private HiveClientParameters hiveClientParameters;
/**
* taskExecutionContext
*/
private final TaskRequest taskExecutionContext;
public HiveClientTask(TaskRequest taskRequest) {
super(taskRequest);
this.taskExecutionContext = taskRequest;
}
/**
* task init method
*/
@Override
public void init() {
logger.info("hive client task param is {}", JSONUtils.toJsonString(taskExecutionContext));
this.hiveClientParameters = JSONUtils.parseObject(taskExecutionContext.getTaskParams(), HiveClientParameters.class);
if (this.hiveClientParameters != null && !hiveClientParameters.checkParameters()) {
throw new RuntimeException("hive client task params is not valid");
}
}
/**
* build task execution command
*
* @return task execution command or null
*/
@Override
protected String buildCommand() {
String filePath = getFilePath();
if (writeExecutionContentToFile(filePath)) {
return "hive -f " + filePath;
}
return null;
}
/**
* get hive sql write path
*
* @return file write path
*/
private String getFilePath() {
return String.format("%s/hive-%s-%s.sql", this.taskExecutionContext.getExecutePath(), this.taskExecutionContext.getTaskName(), this.taskExecutionContext.getTaskInstanceId());
}
@Override
protected void setMainJarName() {
//do nothing
}
/**
* write hive sql to filepath
*
* @param filePath file path
* @return write success?
*/
private boolean writeExecutionContentToFile(String filePath) {
Path path = Paths.get(filePath);
try (BufferedWriter writer = Files.newBufferedWriter(path, StandardCharsets.UTF_8)) {
writer.write(this.hiveClientParameters.getSql());
logger.info("file:" + filePath + "write success.");
return true;
} catch (IOException e) {
logger.error("file:" + filePath + "write failed.please path auth.");
e.printStackTrace();
return false;
}
}
@Override
public AbstractParameters getParameters() {
return this.hiveClientParameters;
}
}5.6
遵守 SPI 规则
# 1,Resource下创建META-INF/services文件夹,创建接口全类名相同的文件
zhang@xiaozhang resources % tree ./
./
└── META-INF
└── services
└── org.apache.dolphinscheduler.spi.task.TaskChannelFactory
# 2,在文件中写入实现类的全限定类名
zhang@xiaozhang resources % more META-INF/services/org.apache.dolphinscheduler.spi.task.TaskChannelFactory
org.apache.dolphinscheduler.plugin.task.hive.HiveClientTaskChannelFactory5.7
打包和部署
## 1,打包
mvn clean install
## 2,部署
cp ./target/dolphinscheduler-task-hiveclient-1.0.jar $DOLPHINSCHEDULER_HOME/lib/
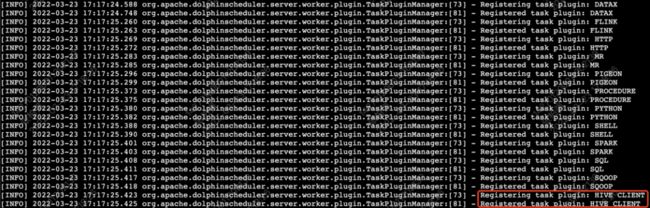
## 3,restart dolphinscheduler server以上操作完成后,我们查看 worker 日志 tail -200f $Apache DolphinScheduler_HOME/log/Apache DolphinScheduler-worker.log
Apache DolphinScheduler 的插件开发就到此完成~涉及到前端的修改可以参考:
Apache DolphinScheduler-ui/src/js/conf/home/pages/dag/_source/formModel/
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
![]()
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
![]()
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。

☞Apache SeaTunnel (Incubating) 2.1.0 发布,内核重构、全面支持 Flink
☞全面拥抱 K8s,ApacheDolphinScheduler 应用与支持 K8s 任务的探索
☞杭州思科对 Apache DolphinScheduler Alert 模块的改造
☞日均处理 10000+ 工作流实例,Apache DolphinScheduler 在 360 数科的实践
☞Apache DolphinScheduler 2.0.5 发布,Worker 容错流程优化
☞Apache DolphinScheduler 版本控制核心原理揭
☞喜讯 | Apache DolphinScheduler PMC Chair 代立冬,PMC 郭强获邀成为 ASF Member
☞途家大数据平台基于 Apache DolphinScheduler 的探
索与
实践
点击阅读原文,参与开源!