竞赛保研 基于机器视觉的12306验证码识别
文章目录
- 0 简介
- 1 数据收集
- 2 识别过程
- 3 网络构建
- 4 数据读取
- 5 模型训练
- 6 加入Dropout层
- 7 数据增强
- 8 迁移学习
- 9 结果
- 9 最后
0 简介
优质竞赛项目系列,今天要分享的是
基于机器视觉的12306验证码识别
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 数据收集
12306的验证码是从8个图片中找到要求的物体,如图所示。

学长统计了1000个样本,发现12306的类别数其实只有80类,它们的类别以及对应的统计个数如下表

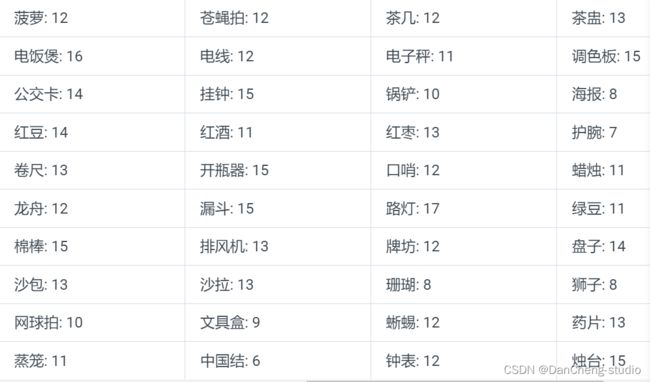
从上面的统计中我们可以看出,12306的验证码的破解工作可以转换成一个80类的分类问题。
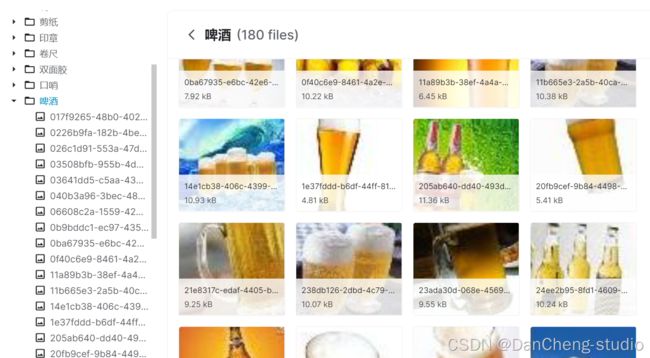
数据集预览

2 识别过程
物体分类的代码可以简单分成三个部分:
- 网络搭建;
- 数据读取;
- 模型训练。
但是在上面的三步中每一步都存在一些超参数,怎么设置这些超参数是一个有经验的算法工程师必须掌握的技能。我们会在下面的章节中介绍每一步的细节,并给出我自己的经验和优化策略。
3 网络构建
搭建一个分类网络时,可以使用上面几篇文章中介绍的经典的网络结构,也可以自行搭建。当自行搭建分类网络时,可以使用下面几步:
- 堆积卷积操作(Conv2D)和最大池化操作(MaxPooling2D),第一层需要指定输入图像的尺寸和通道数;
- Flatten()用于将Feature Map展开成特征向量;
- 之后接全连接层和激活层,注意多分类应该使用softmax激活函数。
自行搭建网络时,学长有几个经验:
- 1 通道数的数量取2^n;
- 2 每次MaxPooling之后通道数乘2;
- 3 最后一层Feature Map的尺寸不宜太大也不宜太小(7-20之间是个不错的选择);
- 4 输出层和Flatten()层往往需要加最少一个隐层用于过渡特征;
- 5 根据计算Flatten()层的节点数量设计隐层节点的个数。
下面代码是学长搭建的一个分类网络
model_simple = models.Sequential()
model_simple.add(layers.Conv2D(32, (3,3), padding=‘same’, activation=‘relu’, input_shape = (66,66,3)))
model_simple.add(layers.MaxPooling2D((2,2)))
model_simple.add(layers.Conv2D(64, (3,3), padding=‘same’, activation=‘relu’))
model_simple.add(layers.MaxPooling2D((2,2)))
model_simple.add(layers.Conv2D(128, (3,3), padding=‘same’, activation=‘relu’))
model_simple.add(layers.MaxPooling2D((2,2)))
model_simple.add(layers.Flatten())
model_simple.add(layers.Dense(1024, activation=‘relu’))
model_simple.add(layers.Dense(80, activation=‘softmax’))
在上面代码中VGG16()函数用于调用Keras自带的VGG-16网络,weights参数指定网络是否使用迁移学习模型,值为None时表示随机初始化,值为ImageNet时表示使用ImageNet数据集训练得到的模型。
include_top参数表示是否使用后面的输出层,我们确定了只使用表示层,所以取值为False。input_shape表示输入图片的尺寸,由于VGG-16会进行5次降采样,所以我们使用它的默认输入尺寸224
224 3,所以输入之前会将输入图片放大。
4 数据读取
Keras提供了多种读取数据的方法,我们推荐使用生成器的方式。在生成器中,Keras在训练模型的同时把下一批要训练的数据预先读取到内存中,这样会节约内存,有利于大规模数据的训练。Keras的生成器的初始化是ImageDataGenerator类,它有一些自带的数据增强的方法。
在这个项目中学长将不同的分类置于不同的目录之下,因此读取数据时使用的是flow_from_directory()函数,训练数据读取代码如下(验证和测试相同):
train_data_gen = ImageDataGenerator(rescale=1./255)
train_generator = train_data_gen.flow_from_directory(train_folder,
target_size=(66, 66),
batch_size=128,
class_mode=‘categorical’)
我们已近确定了是分类任务,所以class_mode的值取categorical。
5 模型训练
当我们训练模型时首先我们要确定的优化策略和损失函数,这里我们选择了Adagrad作为优化策略,损失函数选择多分类交叉熵categorical_crossentropy。由于我们使用了生成器读取数据,所以要使用fit_generator来向模型喂数据,代码如下。
model_simple.compile(loss=‘categorical_crossentropy’, optimizer=optimizers.Adagrad(lr=0.01), metrics=[‘acc’])
history_simple = model_simple.fit_generator(train_generator,
steps_per_epoch=128,
epochs=20,
validation_data=val_generator)
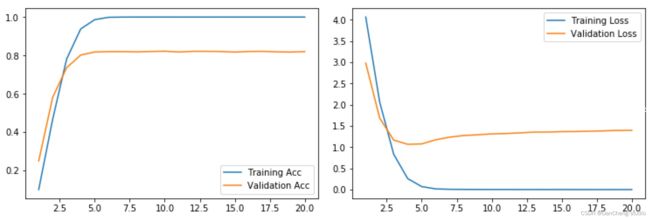
经过20个Epoch之后,模型会趋于收敛,损失值曲线和精度曲线见图,此时的测试集的准确率是0.8275。从收敛情况我们可以分析到模型此时已经过拟合,需要一些策略来解决这个问题。
6 加入Dropout层
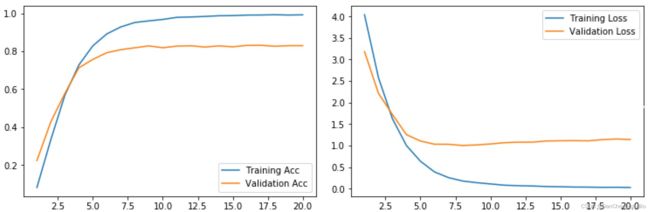
Dropout一直是解决过拟合非常有效的策略。在使用dropout时丢失率的设置是一个技术活,丢失率太小的话Dropout不能发挥其作用,丢失率太大的话模型会不容易收敛,甚至会一直震荡。在这里我在后面的全连接层和最后一层卷积层各加一个丢失率为0.25的Dropout。收敛曲线和精度曲线见下图,可以看出过拟合问题依旧存在,但是略有减轻,此时得到的测试集准确率是0.83375
7 数据增强
Keras提供在调用ImageDataGenerator类的时候根据它的参数添加数据增强策略,在进行数据扩充时,学长有几点建议:
- 1 扩充策略的设置要建立在对数据集充分的观测和理解上;
- 2 正确的扩充策略能增加样本数量,大幅减轻过拟合的问题;
- 3 错误的扩充策略很有可能导致模型不好收敛,更严重的问题是使训练集和测试集的分布更加不一致,加剧过拟合的问题;
- 4 往往开发者需要根据业务场景自行实现扩充策略。
下面代码是我使用的数据增强的几个策略。
train_data_gen_aug = ImageDataGenerator(rescale=1./255,
horizontal_flip = True,
zoom_range = 0.1,
width_shift_range= 0.1,
height_shift_range=0.1,
shear_range=0.1,
rotation_range=5)
train_generator_aug = train_data_gen_aug.flow_from_directory(train_folder,
target_size=(66, 66),
batch_size=128,
class_mode=‘categorical’)
其中rescale=1./255参数的作用是对图像做归一化,归一化是一个在几乎所有图像问题上均有用的策略;horizontal_flip =
True,增加了水平翻转,这个是适用于当前数据集的,但是在OCR等方向水平翻转是不能用的;其它的包括缩放,平移,旋转等都是常见的数据增强的策略,此处不再赘述。
结合Dropout,数据扩充可以进一步减轻过拟合的问题,它的收敛曲线和精度曲线见图4,此时得到的测试集准确率是0.84875。

8 迁移学习
除了我们自己构建网络以外,我们还可以使用现成的网络预训练模型做迁移学习,能使用的网络结构有:
- Xception
- VGG16
- VGG19
- ResNet50
- InceptionV3
- InceptionResNetV2
- MobileNet
- DenseNet
- NASNet
使用经典模型往往和迁移学习配合使用效果更好,所谓迁移学习是将训练好的任务A(最常用的是ImageNet)的模型用于当前任务的网络的初始化,然后在自己的数据上进行微调。该方法在数据集比较小的任务上往往效果很好。Keras提供用户自定义迁移学习时哪些层可以微调,哪些层不需要微调,通过layer.trainable设置。Keras使用迁移学习提供的模型往往比较深,容易产生梯度消失或者梯度爆炸的问题,建议添加BN层。最好的策略是选择好适合自己任务的网络后自己使用
以VGG-16为例,其使用迁移学习的代码如下。第一次运行这段代码时需要下载供迁移学习的模型,因此速度会比较慢,请耐心等待。
model_trans_VGG16 = models.Sequential()
trans_VGG16 = VGG16(weights=‘imagenet’, include_top=False, input_shape=(224,224,3))
model_trans_VGG16.add(trans_VGG16)
model_trans_VGG16.add(layers.Flatten())
model_trans_VGG16.add(layers.Dense(1024, activation=‘relu’))
model_trans_VGG16.add(layers.BatchNormalization())
model_trans_VGG16.add(layers.Dropout(0.25))
model_trans_VGG16.add(layers.Dense(80, activation=‘softmax’))
model_trans_VGG16.summary()
它的收敛曲线和精度曲线见图5,此时得到的测试集准确率是0.774375,此时迁移学习的效果反而不如我们前面随便搭建的网络。在这个问题上导致迁移学习模型表现效果不好的原因有两个:
- VGG-16的网络过深,在12306验证码这种简单的验证码上容易过拟合;
- 由于include_top的值为False,所以网络的全连接层是随机初始化的,导致开始训练时损失值过大,带偏已经训练好的表示层。

为了防止表示层被带偏,我们可以将Keras中的层的trainable值设为False来达到此目的。结合之前
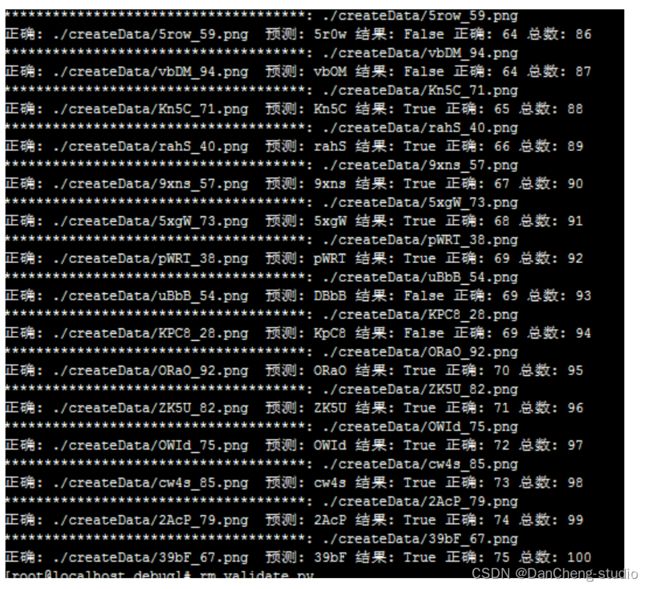
9 结果
我将12306网站验证码的破解工作转换成了一个经典的多分类问题,并通过深度学习和一些trick将识别率提高到了91.625%。
训练测试结果:
9 最后
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate