进阶学习——Linux系统服务器硬件认识与RAID磁盘
目录
一、服务器知识补充
1.硬件
2.服务器常见故障
二、认识RAID
1.什么是RAID
2.RAID的优点
3.RAID的实现方式
三、RAID磁盘陈列
1.RAID 0 磁盘陈列介绍——RAID 0
2.RAID 1 磁盘陈列介绍——RAID 1
3.RAID 5 磁盘陈列介绍——RAID 5
4.RAID 6 磁盘陈列介绍——RAID 6
5.RAID 1+0 磁盘陈列介绍——RAID 1+0
6.总结对比
四、实现RAID——RAID模拟
(一)硬RAID
1.进入RAID卡
2.选择创建的RAID
3.修改RAID属性信息
4.初始化
5.删除RAID
6.查看RAID的详细信息
(二)热备盘
1.全局热备
2.局部热备
3.删除热备
五、实验——创建软RAID
1.搭建实验所需环境
2.建立RAID盘热备盘
3.实验流程
4.实验延伸——mdadm命令
一、服务器知识补充
1.硬件
- cpu
- 主板
- 内存
- 硬盘
- 网卡
- 电源
- raid卡
- 风扇
- 远程管理卡
2.服务器常见故障
系统不停重启进入不了系统
- 排查是否是硬件故障,系统盘是否损坏(硬盘灯红色,黄色,绿色)
- 查看系统第一启动项是那种方式(硬盘 网络网卡 光驱 U盘) bios
- 是否双系统?双系统
- 硬盘主板背板是否有问题
- 服务器开机较慢请耐心等待3分钟,不是起不来
- uefi和legacy
UEFI+GPT分区,只可安装win8/win10,开机快,效率高
Legacy+MBR分区,安装任何系统,开机慢,无法支持超过 2T 的硬盘

系统安装不上
- 该机器是否支持该系统
- 驱动是否合适或是否已打驱动官网 客服
- 系统镜像是否可用
- 使用的U盘,光驱是否正常?光驱 外接光驱
- 客服( 如已过保?)
一般进入阵列卡的快捷键
- ctrl+h
- ctrl+r
网络不通
- 注意服务器目前都是千兆网卡,不支持百兆网口
- 插错网口 管理口 NIC
- 网线是否正常
- 网卡是否正常
- 上行交换机是否正常
- 呼叫网管
硬盘不识别
- 重启服务器
- 系统中使用命令echo “- - -”
- 虚拟磁盘和直通硬盘不能混合使用
解决方法
- 单块磁盘做raid0
- 支持直通模式的阵列卡调成直通模式,可以混用 调用不多
二、认识RAID
磁盘、LVM分区、RAID磁盘陈列的区别
| 硬盘 | 连续空间 | 无法扩容 |
| LVM | 非连续空间 | 可以动态扩容 |
| RAID | 解决备份问题 | 提高读写性能 |
1.什么是RAID
"RAID"一词是由David Patterson, Garth A. Gibson, Randy Katz 于1987年在加州大学伯克利分校发明的。在1988年6月SIGMOD会议上提交的论文"A Case for Redundant Arrays of Inexpensive Disks”"中提出,当时性能最好的大型机不断增长的个人电脑市场开发的一系列廉价驱动器的性能所击败。尽管故障与驱动器数量的比例会上升,但通过配置冗余,阵列的可靠性可能远远超过任何大型单个驱动器的可靠性。
独立硬盘冗余阵列(RAID, Redundant Array of Independent Disks),旧称廉价磁盘冗余阵列(Redundant Array of Inexpensive Disks),简称磁盘阵列。利用虚拟化存储技术把多个硬盘组合起来,成为一个或多个硬盘阵列组,目的为提升性能或数据冗余,或是两者同时提升。RAID 层级不同,数据会以多种模式分散于各个硬盘,RAID 层级的命名会以 RAID 开头并带数字,例如:RAID 0、RAID 1、RAID 5、RAID 6、RAID 7、RAID 01、RAID 10(RAID1+0)、RAID 50、RAID 60。每种等级都有其理论上的优缺点,不同的等级在两个目标间获取平衡,分别是增加数据可靠性以及增加存储器群)读写性能。
简单来说,RAID把多个硬盘组合成为一个逻辑硬盘,因此,操作系统只会把它当作一个实体硬盘。RAID常被用在服务器电脑上,并且常使用完全相同的硬盘作为组合。由于硬盘价格的不断下降与RAID功能更加有效地与主板集成,它也成为普通用户的一个选择,特别是需要大容量存储空间的工作,如:视频与音频制作。
2.RAID的优点
- 提高IO能力
- 提高耐用性,
- 磁盘冗余备份
3.RAID的实现方式
- 外接式磁盘阵列:通过扩展卡提供适配能力
- 内接式RAID:主板集成RAID控制器,安装OS前在BIOS里配置
- 软件RAID:通过OS实现,比如:群晖的NAS存储
硬件方式:通过RAID卡;软件方式:通过RAID软件方式
三、RAID磁盘陈列
1.RAID 0 磁盘陈列介绍——RAID 0
- RAID 0 连续与以位或字节为单位分割数据,并行读/写多个磁盘上,因此具有很高的数据传输率,但它没有数据冗余
- RAID 0 只是单纯地提高性能,并没有为数据的可靠性提供保证,而且其中的一个磁盘失效将影响到所有数据
- RAID 0 不能应用于数据安全性要求高的场合

一般不会使用一块盘做RAID 0;直通盘不能和RAID盘混用;系统中要不然都做RAID,要不然都不做RAID
因为读写时都可以并行处理,所以在所有的级别中,RAID 0 的速度是最快的。但是RAID 0 既没有冗余功能,也不具备容错能力,如果一个磁盘(物理)损坏,所有数据都会丢失。
2.RAID 1 磁盘陈列介绍——RAID 1
- 通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据
- 当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID 1 可以提高读取性能
- RAID 1 是磁盘阵列中单位成本最高的,但提供了很高的数据安全性和可用性。当一个磁盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据

RAID 1 也称为镜像,两组以上的N个磁盘相互作为镜像,在一些多线程操作系统中能有很好的读取速度,理论上读取速度等于硬盘数量的倍数,与RAID 0 相同。另外写入速度有微小的降低。
3.RAID 5 磁盘陈列介绍——RAID 5
- N(N≥3)块盘组成阵列,一份数据产生N-1个条带,同时还有1份校验数据,共N份数据在N块盘上循环均衡存储
- N块盘同时读写,读性能很高,但由于有校验机制的问题,写性能相对不高
- (N-1)/N磁盘利用率
- 可靠性高,允许坏1块盘,不影响所有数据

4.RAID 6 磁盘陈列介绍——RAID 6
N(N≥4)块盘组成阵列,(N-2)/N磁盘利用率
与RAID 5相比,RAID 6增加了第二个独立的奇偶校验信息块
两个独立的奇偶系统使用不同的算法,即使两块磁盘同时失效也不会影响数据的使用
相对于RAID 5有更大的“写损失”因此写性能较差

5.RAID 1+0 磁盘陈列介绍——RAID 1+0
N(偶数,N≥4)块盘两两镜像后,再组合成一个RAID 0
N/2磁盘利用率
N/2块盘同时写入,N块盘同时读取
性能高,可靠性高
6.总结对比
| 磁盘阵列 | 读 | 写 | 使用磁盘情况 | 有无备份效果 | 利用率 |
| RAID 0 | 提高 | 提高 | 至少一块盘可以做RAID 一块盘无效果,有效果至少两块及以上 |
无 | 100% |
| RAID 1 | 提高2倍 | 较低 | 至少两块盘,一定是二的倍数 (至多可以坏一块盘) |
有 | 50% |
| RAID 5 | 提高 | 降低 | 至少三块及以上n-1 (至多可以坏一块盘) |
有 | n-1 |
| RAID 1+0 | 提高 | 提高 | 至少有四+偶数块盘 (至多可以坏两块盘,但不能坏同一个RAID组里的,有三分之一的概率掉数据) |
有 | 50% |
四、实现RAID——RAID模拟
(一)硬RAID
1.进入RAID卡
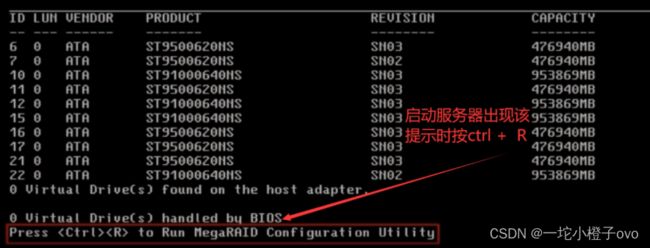
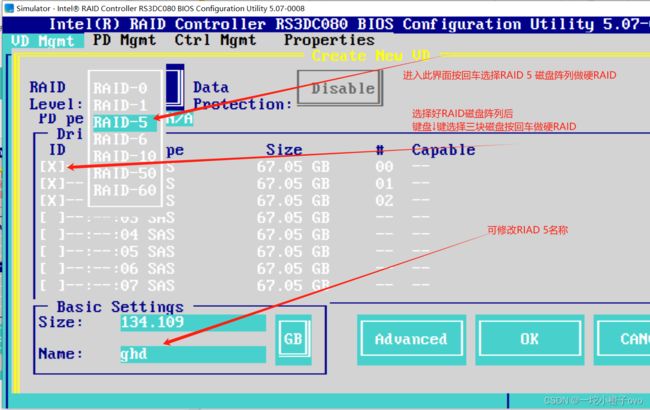
2.选择创建的RAID
Ctrl + N 下一页
Ctrl + P 上一页

3.修改RAID属性信息


4.初始化

5.删除RAID
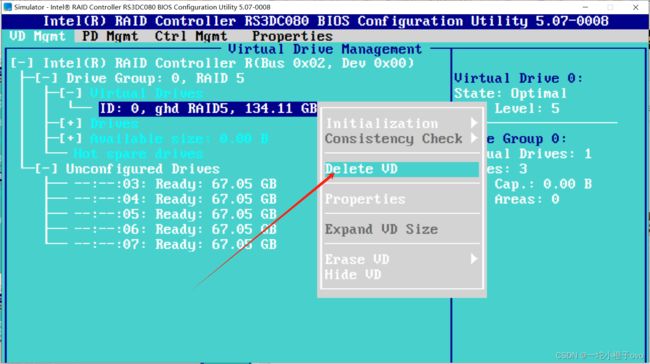
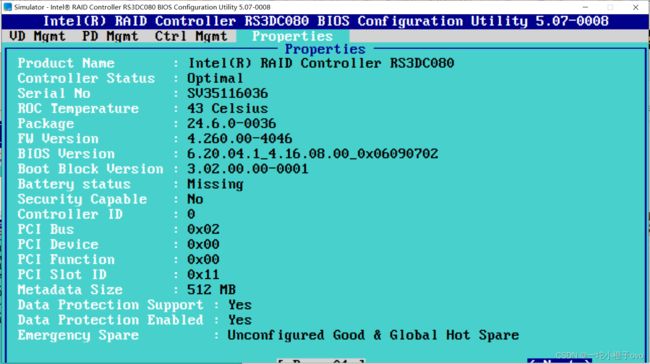
6.查看RAID的详细信息
(二)热备盘
热备盘(Hot Spare)是RAID)技术中的一种策略,用于提高存储系统的容错性和可用性。在RAID配置中,一个或多个硬盘被设置为热备状态,它并不直接参与日常的数据读写操作,而是作为备用资源待命。
1.全局热备

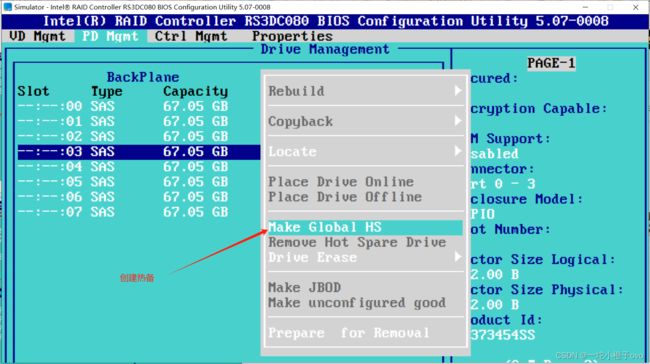

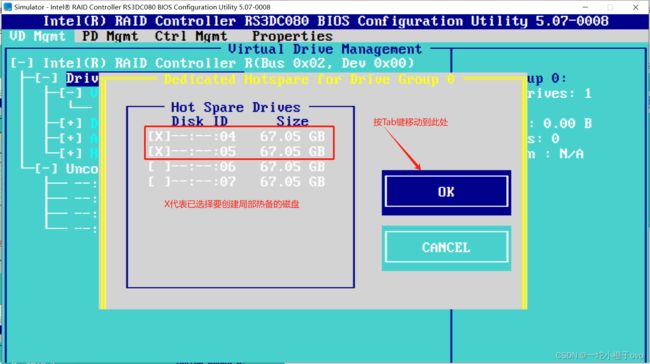
2.局部热备
专门分配给某一个特定的RAID组,仅当这个RAID组内的硬盘出现故障时才启用


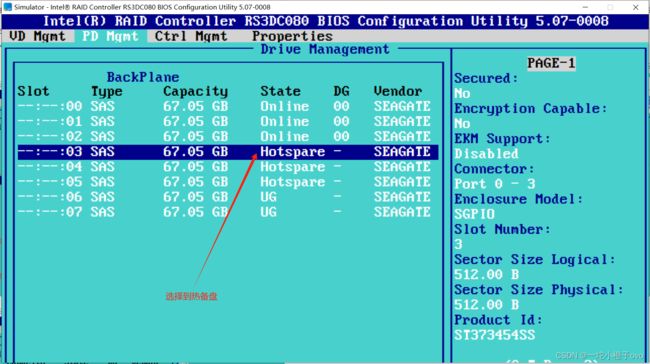
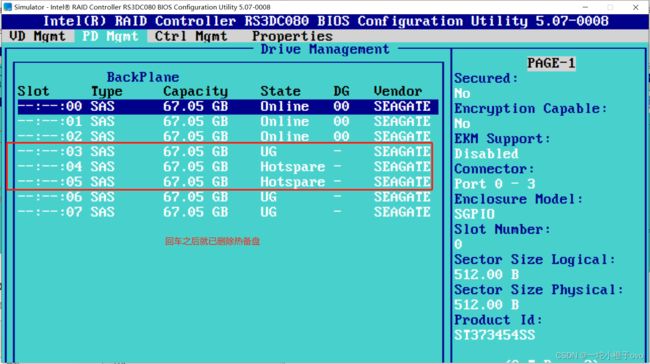
3.删除热备

五、实验——创建软RAID
1.搭建实验所需环境

2.建立RAID盘热备盘

![]()
3.实验流程
[root@localhost ~]#lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
├─sda1 8:1 0 5G 0 part /boot
└─sda2 8:2 0 54G 0 part
├─centos-root 253:0 0 50G 0 lvm /
└─centos-swap 253:1 0 4G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk
sdc 8:32 0 20G 0 disk
sdd 8:48 0 20G 0 disk
sde 8:64 0 20G 0 disk
sdf 8:80 0 20G 0 disk
sdg 8:96 0 20G 0 disk
sr0 11:0 1 4.2G 0 rom /run/media/root/CentOS 7 x86_64
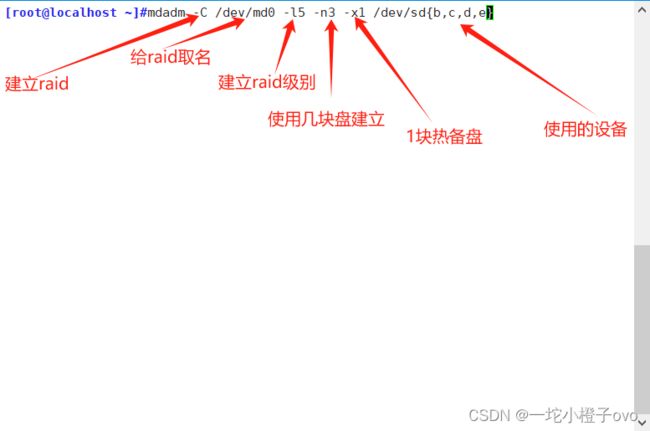
[root@localhost ~]#mdadm -C /dev/md0 -l5 -n3 -x1 /dev/sd{b,c,d,e}
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]#cat /proc/mdstat
#查看raid建立金过程
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdd[4] sde[3](S) sdc[1] sdb[0]
41910272 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [UU_]
[==========>..........] recovery = 52.2% (10946584/20955136) finish=0.8min speed=204468K/sec
unused devices:
[root@localhost ~]#cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdd[4] sde[3](S) sdc[1] sdb[0]
41910272 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
unused devices:
[root@localhost ~]#mkfs.xfs /dev/md0
#建文件系统
meta-data=/dev/md0 isize=512 agcount=16, agsize=654720 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=10475520, imaxpct=25
= sunit=128 swidth=256 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=5120, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@localhost ~]#mount /dev/md0 /mnt
#挂载
[root@localhost ~]#df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 50G 4.6G 46G 10% /
devtmpfs 897M 0 897M 0% /dev
tmpfs 912M 0 912M 0% /dev/shm
tmpfs 912M 9.2M 903M 1% /run
tmpfs 912M 0 912M 0% /sys/fs/cgroup
/dev/sda1 5.0G 179M 4.9G 4% /boot
tmpfs 183M 4.0K 183M 1% /run/user/42
tmpfs 183M 32K 183M 1% /run/user/0
/dev/sr0 4.3G 4.3G 0 100% /run/media/root/CentOS 7 x86_64
/dev/md0 40G 33M 40G 1% /mnt
[root@localhost ~]#cd /mnt
[root@localhost mnt]#cp /etc/passwd /etc/shadow /etc/fstab .
#拷贝etc下的文件到mnt下
[root@localhost mnt]#mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat Dec 30 18:26:28 2023
Raid Level : raid5
Array Size : 41910272 (39.97 GiB 42.92 GB)
Used Dev Size : 20955136 (19.98 GiB 21.46 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sat Dec 30 18:31:48 2023
State : clean
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 5d287ef0:dfa2a97d:3549c571:06cc0438
Events : 18
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
3 8 64 - spare /dev/sde
[root@localhost mnt]#mdadm /dev/md0 -f /dev/sdb
#模拟破坏sdb磁盘
mdadm: set /dev/sdb faulty in /dev/md0
[root@localhost mnt]#mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Sat Dec 30 18:26:28 2023
Raid Level : raid5
Array Size : 41910272 (39.97 GiB 42.92 GB)
Used Dev Size : 20955136 (19.98 GiB 21.46 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sat Dec 30 18:32:59 2023
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 1
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 31% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 5d287ef0:dfa2a97d:3549c571:06cc0438
Events : 27
Number Major Minor RaidDevice State
3 8 64 0 spare rebuilding /dev/sde
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
0 8 16 - faulty /dev/sdb
#sdb磁盘被破坏 热备盘sdc sdd顶替工作
[root@localhost mnt]#mdadm /dev/md0 -r /dev/sdb
#删除坏盘sdb
mdadm: hot removed /dev/sdb from /dev/md0
[root@localhost mnt]#mdadm -D /dev/md0
#再次查看磁盘信息
/dev/md0:
Version : 1.2
Creation Time : Sat Dec 30 18:26:28 2023
Raid Level : raid5
Array Size : 41910272 (39.97 GiB 42.92 GB)
Used Dev Size : 20955136 (19.98 GiB 21.46 GB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Sat Dec 30 18:33:12 2023
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 48% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 5d287ef0:dfa2a97d:3549c571:06cc0438
Events : 30
Number Major Minor RaidDevice State
3 8 64 0 spare rebuilding /dev/sde
1 8 32 1 active sync /dev/sdc
4 8 48 2 active sync /dev/sdd
#此时已经没有sdb磁盘了
[root@localhost mnt]#ls /mnt
fstab passwd shadow
#再次查看mnt下的文件信息 因为热备盘顶替被干掉的sdb磁盘进行工作所以信息还在,没有被损坏
4.实验延伸——mdadm命令
| 选项 | 含义 |
| -a | 检测设备名称 |
| -n | 指定设备数量 |
| -l | 指定 raid 级别 |
| -C | 建立raid |
| -v | 显示过程 |
| -f | 模拟设备损坏 |
| -r | 移除设备 |
| -S | 停止阵列 |
| -Q | 查看摘要信息 |
| -D | 查看详细信息 |