RSIS 系列 Rotated Multi-Scale Interaction Network for Referring Remote Sensing Image Segmentation 论文阅读
RSIS 系列 Rotated Multi-Scale Interaction Network for Referring Remote Sensing Image Segmentation 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- Referring Image Detection and Segmentation
- Remote Sensing Referring Image Detection and Segmentation
- 四、RRSIS-D
- 五、RMSIN
-
- 5.1 总览
- 5.2 Compounded Scale Interaction Encoder (CSIE)
-
- 5.2.1 尺度内交互模块
-
- 各种感知分支
- 跨模态对齐分支
- 5.2.2 跨尺度交互模块
-
- 多尺度特征组合
- 多尺度注意力层
- 尺度感知门
- 5.3 方向感知解码器
-
- 5.3.1 自适应旋转卷积
- 六、实验
-
- 6.1 实施细节
-
- 实验设置
- 指标
- 6.2 与 SOTA 的 RIS 方法比较
- 6.3 消融研究
-
- IIM 和 CIM 的有效性
- CIM 的深度设计
- 解码器的设计
- ARC 的设计
- 6.4 可视化
-
- 6.4.1 定量分析
- 6.4.2 编码器特征可视化
- 七、结论
写在前面
同样是一篇比较新的论文挂在 Arxiv 上面,拿来读一读。看标题应该是提出了新的 RIS 数据集与方法,用于遥感目标检测的。
- 论文地址:Rotated Multi-Scale Interaction Network for Referring Remote Sensing Image Segmentation
- 代码地址:https://github.com/Lsan2401/RMSIN
- 预计提交于:CVPR 2024
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 6 千粉丝有你的参与呦~
一、Abstract
首先指出 Referring Remote Sensing Image Segmentation (RRSIS) 指代遥感目标分割的粗略含义,与 RIS 一致,但是需要在航空图像中实现。于是本文引入一种旋转的多尺度交互网络 Rotated Multi-Scale Interaction Network (RMSIN),其整合了一种内部尺度交互模块 Intra-scale Interaction Module (IIM) 来解决多尺度且细粒度的细节信息,以及一种跨尺度交互模块 Cross-scale Interaction Module (CIM) 用于整合这些细节。此外,RMSIN 利用自适应旋转卷积 Adaptive Rotated Convolution (ARC) 考虑那些不同方向的目标。为评估 RMSIN 的性能,建立了一个可拓展的数据集,包含 17420 个“图像-字幕-mask” 三元组。实验效果很好。
二、引言
Referring Remote Sensing Image Segmentation (RRSIS) 的定义,应用。缺陷在于:这一领域数据集尺度有限,且模型精度有限。于是本文引入一种可拓展的数据集,名为 RRSSIS-D,用于提升 RRSIS 任务。此数据集主要利用 Segment Anything Model (SAM) 模型,采用一个半自动化标注流程,因此耗时较短,同时标注精度较高。其设计源于最初的 Bounding box prompts 生成的分割 masks,然后进一步精炼来确保航空图像的高保真度。于是生成了一个包含 17502 个遥感“图像-字幕-masks”三元组。
此外,现有的 RIS 方法在应对遥感图像时效果不咋地。如下图所示:

航空图像的挑战在于不仅包含了传统的数据,还有一些尺度多变的图像以及多个方向的图像。当前的 RIS 方法在面对这些航空图像时效果确实不行。
于是本文提出 Rotated Multi-Scale Interaction Network (RMSIN) 用于解决 RRSIS 问题。首先引入了一种尺度内交互模块 Intra-scale Interaction Module (IIM),在单个层内提取出详细的特征信息;引入一种跨尺度交互模块 Cross-scale Interaction Module (CIM) 来促进全面的特征融合。此外,整合一种自适应旋转卷积 Adaptive Rotated Convolution (ARC) 到解码器中,使得模型能够解决目标的旋转问题。本文贡献总结如下:
- 引入 RRSiS-D,一种新的数据集用于指代遥感图像分割 Referring Remote Sensing Image Segmentation (RRSIS)。其利用 SAM 的分割能力再结合手动校准,在目标尺度和方向上有很大变动;
- 提出旋转多尺度交互网络 Rotated Multi-Scale Interaction Network (RMSIN) 用于解决航空图像中多种空间尺度和方向变化的问题;
- 提出 IIM 和 CIM 用于解决不同尺度下的细粒度信息问题,设计了 ARC 用于增强模型对于任意旋转目标的鲁棒性问题;
- 大量的实验表明本文提出的 RMSIN 实现了 SOTA 的性能。
三、相关工作
Referring Image Detection and Segmentation
讲一下 RID 和 RIS 的定义,现有的方法。然而由于航空图像的特殊属性,这些方法很难在遥感领域发挥作用。有一些方法引入了尺度交互模块用于增强特征提取,但是自然图像和航空图像间的语义鸿沟仍然存在,使得性能达不到最优结果。
Remote Sensing Referring Image Detection and Segmentation
RSRID 和 RSRIS 任务比较新,目前研究还很少。而最近基于 Transformer 的方法 RSVG 利用视觉 Transformer 和 BERT 作为 Backbone,整合了多层次跨模态特征学习来解决航空图像中的多尺度变换问题。而 RSRIS 也是处于萌芽期,于是本文提出一种可拓展的、复杂的 RRSIS-D 数据集,以及一种新的模型 RMSIN。
四、RRSIS-D

提出了一个RRSIS-D 数据集,用于RRSIS 任务。上图为数据集中的词云表示。基于 Segment Anything Model (SAM),采用了一种半自动化标注方法,利用 bouding boxes 和 SAM 上生成像素级别的 masks,从而在标注过程节约成本。具体来说,采用下列步骤为语言标注生成逐像素标注:
- 步骤一:利用 SAM 为 RSVGD 数据集中的 Bounding box prompts 生成 masks,然而由于 SAM 可能在精度方面存在变化(主要是航空图像和自然图像存在领域鸿沟导致),于是有了下一步。
- 采取一个手动提炼过程用于那些可能存在问题的航空图像 mask,具体来说,对数据集进行全面检查,鉴别那些有问题的数据,手动标注其 masks。
- RRSIS-D 数据集的标注全部转化为与 RefCOOC 数据集相同的格式。
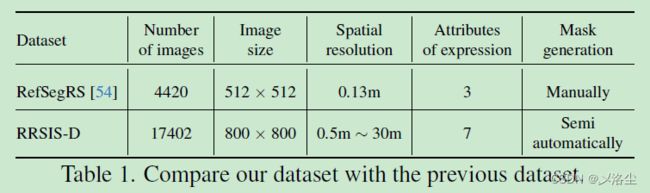
数据集的统计情况如上表所示,类别分布如下图所示:

生成 Maks 的统计情况如下图所示:

需要注意的是生成的 masks 非常小的比例占据了数据集中的绝大部分。但同时也有一些大像素,例如超过 40 0000 的。
五、RMSIN
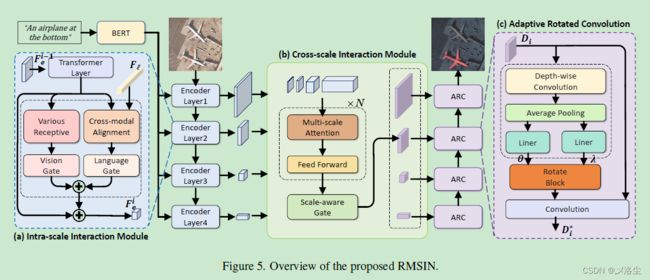
5.1 总览
给定输入图像 I ∈ R H × W × 3 I\in \mathbb{R}^{H\times W\times 3} I∈RH×W×3,语言表达式 E = { ω i } , i ∈ { 0 , … , N } E=\{\omega_i\},i\in\{0,\ldots,N\} E={ωi},i∈{0,…,N},其中 H H H 和 W W W 分别表示图像的高、宽。 N N N 为表达式的长度。输入表达式通过 backbone f l f_l fl 转化到特征空间 F l ∈ R N × C F_l\in \mathbb{R}^{N\times C} Fl∈RN×C。
接下来是复合的尺度交互编码器 Compounded Scale Interaction Encoder (CSIE),其由一个尺度内交互模块 Intra-scale Interaction Module (IIM) 和跨尺度交互模块 Cross-scale Interaction Module (CIM) 组成,用于在不同阶段生成融合的特征。最后,基于方向感知解码器 Oriented-Aware Decoder (OAD),提出一种自适应旋转卷积 Adaptive Rotated Convolution (ARC) 生成 masks。
5.2 Compounded Scale Interaction Encoder (CSIE)
给定语言特征 F l F_l Fl 和输入的图像 I ∈ R H × W × 3 I\in \mathbb{R}^{H\times W\times 3} I∈RH×W×3,复合的尺度交互编码器 Compounded Scale Interaction Encoder (CSIE) 以多阶段的方式在内部和外部视角进行视觉语言的跨模态融合。CSIE 由两个组成部分:尺度内交互模块 Intra-scale Interaction Module (IIM) 和跨尺度交互模块 Cross-scale Interaction Module (CIM)。
5.2.1 尺度内交互模块
CSIE 内每个阶段的第一部分,即尺度内交互模块 Intra-scale Interaction Module (IIM) 用于提取每个尺度下的信息,并促进视觉语言模态的交互。根据级联的 4 个阶段,IIM 可以表示为 { ϕ i } i ∈ { 1 , 2 , 3 , 4 } \{\phi_i\}_{i\in\{1,2,3,4\}} {ϕi}i∈{1,2,3,4}。通过文本 Backbone 得到语言特征 F l ∈ R N × C F_l\in \mathbb{R}^{N\times C} Fl∈RN×C,其中 C C C 表示通道的数量,IIM 每个阶段的输出特征 F e i F_e^{i} Fei可表示为:
F e i = ϕ i ( F e i − 1 , F ℓ ) F_{e}^{i}=\phi_{i}(F_{e}^{i-1},F_{\ell}) Fei=ϕi(Fei−1,Fℓ)其中 F e 0 F_e^0 Fe0 利用视觉 Backbone f v f_v fv 和输入 I I I 得到。具体来说,在阶段 i i i 中,输入的特征 F e i − 1 F^{i-1}_e Fei−1 经过一个下采样和 MLP 减少其尺度,并统一其维度到特征 F ^ e i − 1 \hat F^{i-1}_e F^ei−1。然后 F ^ e i − 1 \hat F^{i-1}_e F^ei−1 送入到两个分支中用于增强视觉先验以及融合跨模态信息。
各种感知分支
特征 F ^ e i − 1 \hat F^{i-1}_e F^ei−1 送入到多个不同卷积核大小的分支,生成不同感受野大小的特征图:
ω i = σ ( ∑ j = 0 J ( 1 C ∑ C k j i ∗ F ^ e i − 1 ) ) \omega^i=\sigma\left(\sum_{j=0}^J\left(\frac1C\sum^Ck_j^i*\hat{F}_e^{i-1}\right)\right) ωi=σ(j=0∑J(C1∑Ckji∗F^ei−1))其中 k j i k_j^i kji 表示第 j j j 个卷积分支, σ \sigma σ 为 Sigmoid 函数。 ω i ∈ ( 0 , 1 ) H × W \omega^i\in {(0,1)}^{H \times W} ωi∈(0,1)H×W 为平衡不同分支的权重:
F ^ e 1 i − 1 = ω i ⊗ F ^ e i − 1 \hat{F}_{e1}^{i-1}=\omega^i\otimes\hat{F}_{e}^{i-1} F^e1i−1=ωi⊗F^ei−1
此外,其输出通过一个视觉门进行归一化,添加在原始图像特征上作为局部细节信息的补充。这一过程实施如下:
α = T a n h ( L N ( R e L U ( L N ( F ^ e 1 i − 1 ) ) ) ) \alpha=\mathrm{Tanh}(\mathrm{LN}(\mathrm{ReLU}(\mathrm{LN}(\hat{F}_{e1}^{i-1})))) α=Tanh(LN(ReLU(LN(F^e1i−1))))其中 L N ( ⋅ ) \mathrm{LN}(\cdot) LN(⋅) 表示一个 1 × 1 1\times1 1×1 卷积, T a n h ( ⋅ ) \mathrm{Tanh}(\cdot) Tanh(⋅) 和 R e L U ( ⋅ ) \mathrm{ReLU}(\cdot) ReLU(⋅) 表示激活函数。
跨模态对齐分支
输入为 F ^ e i − 1 \hat F^{i-1}_e F^ei−1 和语言特征 F l F_l Fl,这一模块首先应用尺度点乘注意力, F ^ e i − 1 \hat F^{i-1}_e F^ei−1 作为 query, F l F_l Fl 为 key 和 value 得到多模态特征:
A i = attention ( F ^ e i − 1 W q i , F ℓ W k i , F ℓ W v i ) A^i=\text{attention}(\hat{F}_e^{i-1}W_q^i,F_\ell W_k^i,F_\ell W_v^i) Ai=attention(F^ei−1Wqi,FℓWki,FℓWvi)其中 W q i W_q^i Wqi、 W k i W_k^i Wki、 W v i W_v^i Wvi 为线性投影矩阵。接下来,注意力 A i A^i Ai 联合 F ^ e i − 1 \hat{F}_e^{i-1} F^ei−1 一起得到语言引导的图像特征:
F ^ e 2 i − 1 = P r o j ( A i W w i ⊗ F ^ e i − 1 W m i ) \hat{F}_{e2}^{i-1}=\mathrm{Proj}(A^iW_w^i\otimes\hat{F}_e^{i-1}W_m^i) F^e2i−1=Proj(AiWwi⊗F^ei−1Wmi)其中 W w i W_w^i Wwi、 W m i W_m^i Wmi 为投影矩阵, ⊗ \otimes ⊗ 表示逐元素乘法。得到的结果通过 1 × 1 1\times1 1×1 卷积 Proj ( ⋅ ) \text{Proj}(\cdot) Proj(⋅) 产生最终的输出。
与其它在输出 F ^ e i − 1 \hat{F}_e^{i-1} F^ei−1 上执行的操作类似,其结果通过共享的语言门 β \beta β 来归一化。而视觉门同样添加到原始图像特征上,补充语言特征。于是 IIM 在阶段 i i i 的整体输出特征表示如下:
F e i = F ^ e i − 1 + α F ^ e 1 i − 1 + β F ^ e 2 i − 1 F_{e}^i=\hat{F}_{e}^{i-1}+\alpha\hat{F}_{e1}^{i-1}+\beta\hat{F}_{e2}^{i-1} Fei=F^ei−1+αF^e1i−1+βF^e2i−1
5.2.2 跨尺度交互模块
IIM 充分提取出由语言特征引导的多尺度定位信息,此外设计了一种跨尺度交互模块 Cross-scale Interaction Module (CIM),进一步增强粗糙和细腻阶段的特征交互。具体来说,模块收集 IIM 每个阶段的输出,即 F e i , i ∈ { 1 , 2 , 3 , 4 } F_e^{i},i\in\{1,2,3,4\} Fei,i∈{1,2,3,4},执行多阶段交互。
多尺度特征组合
输入为特征 F e i , i ∈ { 1 , 2 , 3 , 4 } F_e^{i},i\in\{1,2,3,4\} Fei,i∈{1,2,3,4},下采样到同一尺寸后沿着通道维度进行拼接:
F d i = downsample ( F e i ) i ∈ { 1 , 2 , 3 , 4 } , F c ∗ = concat ( F d 1 , F d 2 , F d 3 , F e 4 ) \begin{aligned}F_d^i&=\text{downsample}(F_e^i)\quad i\in\{1,2,3,4\},\\F_c^*&=\text{concat}(F_d^1,F_d^2,F_d^3,F_e^4)\end{aligned} FdiFc∗=downsample(Fei)i∈{1,2,3,4},=concat(Fd1,Fd2,Fd3,Fe4)其中 F d i F_d^i Fdi 为下采样后的特征, F c ∗ F_c^* Fc∗ 表示沿着通道维度拼接后的多阶段特征。通过平均池化进行下采样操作。
多尺度注意力层
设计不同的感受野用于拼接后的特征 F c ∗ F_c^* Fc∗,从而实现多尺度交互。 F c ∗ F_c^* Fc∗ 在不同的深度卷积核的作用下调整为不同的尺度:
F c m = concat c ( k m ∗ F c ∗ ) W m h m = ⌊ h − 1 m + 1 ⌋ , w m = ⌊ w − 1 m + 1 ⌋ \begin{aligned} &F_c^m=\underset{c}{\operatorname*{concat}}(k^m*F_c^*)W^m\\ &h^m=\lfloor\frac{h-1}m+1\rfloor,w^m=\lfloor\frac{w-1}m+1\rfloor \end{aligned} Fcm=cconcat(km∗Fc∗)Wmhm=⌊mh−1+1⌋,wm=⌊mw−1+1⌋其中 m ∈ { 1 , … , M } m\in\{1,\ldots,M\} m∈{1,…,M}, M M M 为调整尺度的数量。 k m k_m km 为第 m m m 个深度卷积核的参数。 h m h_m hm 和 w m w_m wm 分别为 F c m F_c^m Fcm 的高和宽。在得到特征集合 { F c m ∣ m ∈ { 1 , … , M } } \{F_c^m|m\in \{1,\ldots,M\}\} {Fcm∣m∈{1,…,M}} 后,将所有元素在尺寸维度展平,并进行拼接作为序列特征 F ^ c ∗ ∈ R ( ∑ 1 M h m × w m ) × C ) \hat F_c^*\in \mathbb{R}^{(\sum_{1}^{M}h^{m}\times w^{m})\times C)} F^c∗∈R(∑1Mhm×wm)×C)。与经典的注意力类似,将原始特征 F c ∗ F_c^* Fc∗ 作为 query,多尺度感知特征 F ^ c ∗ \hat F_c^* F^c∗ 为 key 和 value,执行跨尺度交互:
F ~ c ∗ = s o f t m a x ( F c ∗ W q ⋅ F ^ c ∗ W k T C ) ⋅ F ^ c ∗ W v \tilde{F}_{c}^{*}=\mathrm{softmax}(\frac{F_{c}^{*}W_{q}\cdot\hat{F}_{c}^{*}W_{k}^{T}}{\sqrt{C}})\cdot\hat{F}_{c}^{*}W_{v} F~c∗=softmax(CFc∗Wq⋅F^c∗WkT)⋅F^c∗Wv接下来采用局部关系表示,称之为 LRC 的模块,归一化多尺注意力的输出。于是,多尺度注意力层的最终输出表示为:
F c = F ~ c ∗ + DWConv ( Hardswish ( F c ∗ ) ) F_c=\widetilde{F}_c^*+\text{DWConv}(\text{Hardswish}(F_c^*)) Fc=F c∗+DWConv(Hardswish(Fc∗))其中 DWConv ( ⋅ ) \text{DWConv}(\cdot) DWConv(⋅) 表示深度卷积, Hardswish ( ⋅ ) \text{Hardswish}(\cdot) Hardswish(⋅) 为激活函数,旨在增强多尺度局部信息。
之后将 F c F_c Fc 划分为 4 个部分,通过上采样恢复到 F e i F_e^i Fei 的原始尺寸后送入尺度感知门,从而得到最终的输出。
尺度感知门
对于 F c F_c Fc 中每个部分,从 F e F_e Fe 中取出对应的部分,从而衡量跨尺度交互的权重。这一权重以辅助残差的方式叠加在 IIM 特征之上,表示如下:
F o i = sigmoid ( F e i W 1 ) ⊗ F c i W 2 + F e i W 3 F_o^i=\text{sigmoid}(F_e^iW_1)\otimes F_c^iW_2+F_e^iW_3 Foi=sigmoid(FeiW1)⊗FciW2+FeiW3其中 i ∈ { 1 , 2 , 3 , 4 } i\in\{1,2,3,4\} i∈{1,2,3,4}。尺度感知门的输出用于下一解码器,从而生成最终的 mask 预测。
5.3 方向感知解码器
来自 CSIE 的特征集合 { F o i ∣ i ∈ { 1 , 2 , 3 , 4 } } \{F_o^i|i\in\{1,2,3,4\}\} {Foi∣i∈{1,2,3,4}} 用于生成 mask。将自适应旋转卷积 Adaptive Rotated Convolution (ARC) 整合进分割解码器用于 RRSIS 任务。
5.3.1 自适应旋转卷积
首先提取方向特征,基于输入来预测 n n n 个角度。对于输入 X X X,预测 θ \theta θ 和 λ \lambda λ 如下:
θ , λ = Routing ( X ) \theta,\lambda=\operatorname{Routing}(X) θ,λ=Routing(X)其中 Routing 块的结构如下图所示:

其中静态卷积核权重可以视为从 2 维核空间采样出的点。因此卷积的方向选择为旋转重采样的过程。具体来说,卷积核 W i W_i Wi 根据预测的角度重参数化为:
Y i ′ = M − 1 ( θ i ) Y i W i ′ = i n t e r p o l a t i o n ( W i , Y i ′ ) \begin{aligned} &Y_{i}^{'}=M^{-1}(\theta_{i})Y_{i}\\ &W_{i}^{'}=\mathrm{interpolation}(W_{i},Y_{i}^{'}) \end{aligned} Yi′=M−1(θi)YiWi′=interpolation(Wi,Yi′)其中 Y i Y_i Yi 为原始采样点的坐标, M − 1 ( θ i ) M^{-1}(\theta_{i}) M−1(θi) 为旋转矩阵的逆矩阵,用于仿射变换 θ \theta θ 度。 i n t e r p o l a t i o n \mathrm{interpolation} interpolation 通过双线性插值实现。最终,特征通过获得的卷积核过滤,之后进行一个权重求和操作来生成方向感知的特征:
X ∗ = X ∗ ∑ i = 1 n λ i W i ′ X^*=X*\sum_{i=1}^n\lambda_iW_i^{'} X∗=X∗i=1∑nλiWi′
Mask 预测的整体自顶向下过程描述如下:
D 4 = F o 4 D i = S e g ( A R C ( [ D i + 1 ; F o i ] ) ) , i ∈ { 1 , 2 , 3 } D 0 = P r o j ( D 1 ) \begin{aligned} &D_{4}=F_{o}^{4} \\ &\begin{aligned}D_i=\mathrm{Seg}(\mathrm{ARC}([D_{i+1};F_o^i])),\quad i\in\{1,2,3\}\end{aligned} \\ &D_{0}=\mathrm{Proj}(D_{1}) \end{aligned} D4=Fo4Di=Seg(ARC([Di+1;Foi])),i∈{1,2,3}D0=Proj(D1)其中 S e g \mathrm{Seg} Seg 表示一个非线性块,由一个 3 × 3 3\times3 3×3 卷积层,一个 batch normalization 层,一个 ReLU 激活函数组成。 P r o j \mathrm{Proj} Proj 是一个线性投影函数,将最终的特征 D 1 D_1 D1 投影为两个类别得分。需要注意的是一半的卷积层由 ARC 代替,从而利用上特征空间的方向信息。
六、实验
6.1 实施细节
实验设置
视觉 Backbone 采用 Swin Transformer,预训练在 ImageNet22K 上,语言 Backbone 采用 BERT 模型。训练 40 个 epochs,AdamW 优化器,权重衰减 0.01,初始学习率 5 e − 4 5e-4 5e−4,根据 polynomial 衰减。输入图像尺寸 480 × 480 480\times480 480×480。
指标
Overall Intersection-over-Union (oIoU)、Mean Intersection-over-Union (mIoU)、Precision@X (P@X)。
6.2 与 SOTA 的 RIS 方法比较

6.3 消融研究
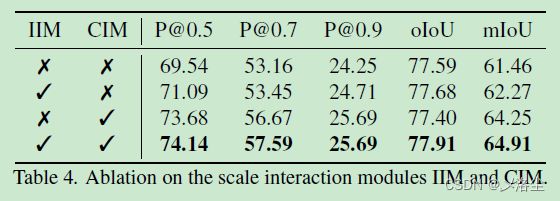
IIM 和 CIM 的有效性
CIM 的深度设计

解码器的设计

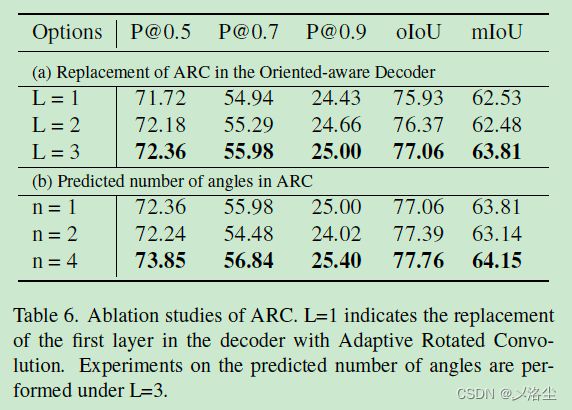
ARC 的设计
6.4 可视化
6.4.1 定量分析

6.4.2 编码器特征可视化

七、结论
本文引入一个旋转多尺度交互网络 Rotated Multi-Scale Interaction Network (RMSIN),用于解决 RRSIS 中复杂的空间尺度和方向问题。尺度内交互模块 Intra-scale Interaction Module 和 RMSIN 中的跨尺度交互模块 Cross-scale Interaction Module 解决了航空图像中不同空间尺度的问题。此外,自适应旋转卷积的引入解决了航空图像中不同的方向分布问题。在 RRSIS-D 数据集上的实验表明 RMSIN 的方法达到了 SOTA 的性能。
写在后面
这篇论文工作量其实蛮大的,比上一篇好很多。这个论文应该稳中,但是评分的话也不是那么顶高。毕竟涉及到了多个模块的组合。还是要吐槽下论文的写作,咋说呢,感觉不是那么完美。