HBase内存配置及JVM优化
前言
本文从HBase的内存布局说起,先充分了解HBase的内存区的使用与分配,随后给出了不同业务场景下的读写内存分配规划,并指导如何分析业务的内存使用情况,以及在使用当中写内存Memstore及读内存扩展bucketcache的一些注意事项,最后为了保障集群的稳定性,减少和降低gc对于集群稳定性的影响,研究及分享了一些关于HBase JVM配置的一些关键参数机器作用和范例。
HBase的内存布局
一台region server的内存使用(如图)主要分为两个部分:
1、jvm内存即我们通常俗称的堆内内存,这块内存区域的大小分配在HBase的环境脚本中设置,在堆内内存中主要有三块内存区域。
- 20%分配给hbase + regionserver rpc请求队列及一些其他操作
- 80%分配给memstore + blockcache
2、java direct memory 即堆外内存
- 其中一部分内存用于HDFS SCR/NIO 操作
- 另一部分用于堆外内存 bucket cache ,其内存大小的分配同样在hbase的环境变量脚本中实心

读写内存规划
- 写多读少型规划
在详细说明具体的容量规划前,首先要明确on heap 模式下的内存分布图。
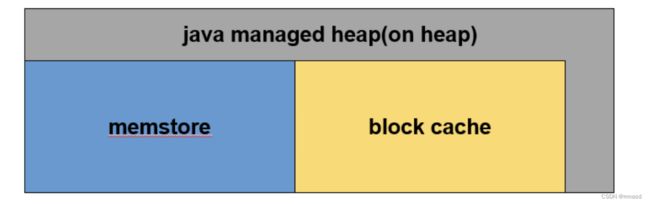
如图,整个RegionServer内存就是JVM所管理的内存,BlockCache用于读缓存,MemStore用于写流程,缓存用户写入KeyValue数据,还有部分用于RegionServer正常RPC请求运行所必须的内存。
| 步骤 | 原理 | 计算 | 值 |
| jvm_heap | 系统总内存的2/3 | 128G/3*2 | 80G |
| blockcache | 读缓存 | 80G*30% | 24G |
| memstore | 写缓存 | 80G*45% | 36G |
hbase-site.xml
hbase.regionserver.global.memstore.size
0.45
hfile.block.cache.size
0.3
- 读多写少型规划
与 on heap模式相比,读多写少型需要更多的读缓存,在对读请求响应时间没有太严苛的情况下,会开启off heap即启用堆外内存中的bucket cache作为读缓存的补充,如图
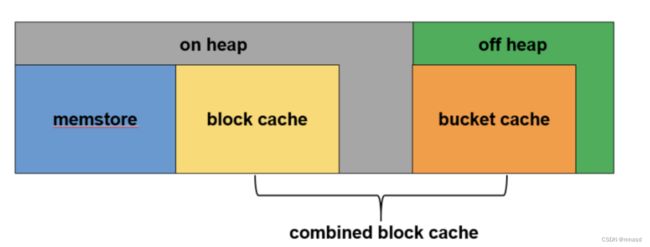
整个RegionServer内存分为两个部分:JVM内存和堆外内存。其中JVM内存中BlockCache和堆外内存BucketCache一起构成了读缓存CombinedBlockCache,用于缓存读到的Block数据,其中BlockCache用于缓存Index Block和Bloom Block,BucketCache用于缓存实际用户数据Data Block。
| 步骤 | 原理 | 计算 | 值 |
|---|---|---|---|
| RS总内存 | 系统总内存的 2/3 | 128G/3*2 | 80G |
| combinedBlockCache | 读缓存设置为整个RS内存的70% | 80G*70% | 56G |
| blockcache | 主要缓存数据块元数据,数据量相对较小。设置为整个读缓存的10% | 56G*10% | 6G |
| bucketcache | 主要缓存用户数据块,数据量相对较大。设置为整个读缓存的90% | 56G*90% | 50G |
| memstore | 写缓存设置为jvm_heap的60% | 30G*60% | 18G |
| jvm_heap | rs总内存-堆外内存 | 80G-50G | 30G |
hbase.bucketcache.combinedcache.enabled
true
hbase.bucketcache.ioengine
offheap #同时作为master的rs要用heap
hbase.bucketcache.size
50176 #单位MB。这个值至少要比bucketcache小1G,作为master的rs用heap,那么这里要填<1的值作为从heap中分配给bucketcache的百分比
hbase.regionserver.global.memstore.size
0.60 #heap减小了,那么heap中用于memstore的百分比要增大才能保证用于memstore的内存和原来一样
hfile.block.cache.size
0.20 #使用了bucketcache作为blockcache的一部分,那么heap中用于blockcache的百分比可以减小
hbase-env.sh
export HBASE_REGIONSERVER_OPTS="-XX:+UseG1GC -Xms30g –Xmx30g -XX:MaxDirectMemorySize=50g"
读写内存的使用情况
在HBase集群运行的过程中,我们需要了解HBase实际情况下的读写内存使用,才能最大化的对配置做出最佳的调整,接下来说下如何查询HBase运行中读写内存使用情况

memStoreSize代表RegionServer中所有HRegion中的memstore大小的总和,单位是Byte。该值的变化,可以反应出一个RegionServer上写请求的负载状况,可以观察memstoreSize的变化率,如果在单位时间内变化比较抖动,可以近似认为写操作频繁。
blockCacheFree代表block cache中空闲的内存大小。计算方法为:getMaxSize() – getCurrentSize(),单位是Byte,该值反映出当前BlockCache中还有多少空间可以被利用。
blockCacheSize代表当前使用的blockCache的大小。BlockCache. getCurrentSize(),单位是Byte,该值反映出BlockCache的使用状况。
以单台region server配置为例
| 配置项 | 配置值 | 内存分配值 | 实际使用量 |
|---|---|---|---|
| HBASE_REGIONSERVER_OPTS | -Xms75g –Xmx75g | 75g | 75g |
| hbase.regionserver.global.memstore.size | 0.22 | 80g*0.22 = 17.6g | 10800044400/1024/1024/1024 ≈ 10G |
| hfile.block.cache.size | 0.22 | 80g*0.22 = 17.6g | 16763937528 /1024/1024/1024 ≈ 15.6G 952802568 /1024/1024/1024 ≈ 0.9G |
结合单台regionserver 的配置来看,读写缓存都有一定空闲空间,这种情况下可以降低heap size来减少gc的次数和时长,然后我们还需要以群集所有region server的数据来判断该集群的配置是否合理,如果存在读写不均衡和热点情况都会影响不同region间的缓存大小。
Memstore深度解析
- memstore简介
一张数据表由一个或者多个region组成,在单个region中每个columnfamily组成一个store,在每个store中由一个memstore和多个storefile组成。

HBase是基于LSM-Tree数据结构的,为了提升写入性能,所有数据写入操作都会先写入memstore(同时会顺序写入WAL),达到指定大小后会对memstore中的数据做次排序后在批量flush磁盘中,此外新写入的数据有较大概率被读取到,因此HBase在读取数据时首先检查memstore中是否有数据缓存,未命中的情况下再去找读缓存,可见memstore无论对于HBase的写入和读取性能都至关重要,而其中memstore flush操作又是memstore最核心的操作。
- memstore flush操作
从memstore flush的动作来看,对业务影响最大是regionserver级别的flush操作,假设每个memstore大小为256mb,每个region有两个cf,整个regionserver上有100个region,根据计算可知,总消耗内存 = 256mb2100 = 51.2g >> 0.40*80g = 32g ,很显然这样的设置情况下,很容易触发region server级别的flush操作,对用户影响较大。
根据如上分析,memstore的设置大小不仅取决于读写的比例,也要根据业务的region数量合理分配memstore大小,同样的我们对每台regionserver上region的数量及每张表cf的数量上的控制也能达到理想的效果。
- 堆外内存注意事项
BucketCache的三种工作模式:
- heap
heap模式分配内存会调用byteBuffer.allocate方法,从JVM提供的heap区分配。
内存分配时heap模式需要首先从操作系统分配内存再拷贝到JVM heap,相比offheap直接从操作系统分配内存更耗时,但反之读取缓存时heap模式可以从JVM heap中直接读取比较快。
- offheap
offheap模式会调用byteBuffer.allocateDirect方法,直接从操作系统分配,因为内存属于操作系统,所以基本不会产生CMS GC,也就在任何情况下都不会因为内存碎片导致触发Full GC。
内存分配时offheap直接从操作系统分配内存比较快,但反之读取时offheap模式需要首先从操作系统拷贝到JVM heap再读取,比较费时。
- file
file使用Fussion-IO或者SSD等作为存储介质,相比昂贵的内存,这样可以提供更大的存储容量。
堆外内存的优势
使用堆外内存,可以将大部分BlockCache读缓存迁入BucketCache,减少jvm heap的size,可以减少GC发生的频次及每次GC时的耗时
BucketCache没有使用JVM 内存管理算法来管理缓存,而是自己对内存进行管理,因此其本身不会因为出现大量碎片导致Full GC的情况发生。
堆外内存的缺陷
读取data block时,需要将off heap的内存块拷贝到jvm heap在读取,比较费时,对读性能敏感用户不太合适。
堆外内存使用总结
对于读多写少且对读性能要求不高的业务场景,offheap模式能够有效的减少gc带来的影响,线上的vac集群在开启offheap模式后,GC频次和耗时都能有效降低,但是因为bucketcache 读的性能的问题达不到要求而回退到heap模式。
JVM配置优化及详解
Hbase服务是基于JVM的,其中对服务可用性最大的挑战是jvm执行full gc操作,此时会导致jvm暂停服务,这个时候,hbase上面所有的读写操作将会被客户端归入队列中排队,一直等到jvm完成gc操作, 服务在遇到full gc操作时会有如下影响
- hbase服务长时间暂停会导致客户端操作超时,操作请求处理异常。
- 服务端超时会导致region信息上报异常丢失心跳,会被zk标记为宕机,导致regionserver即便响应恢复之后,也会因为查询zk上自己的状态后自杀,此时hmaster 会将该regionserver上的所有region移动到其他regionserver上
如何避免和预防GC超时的不良影响,我们需要对JVM的参数进行优化