用通俗易懂的方式讲解大模型:使用 LangChain 和大模型生成海报文案
最近看到某平台在推 LangChain 的课程,其中有个示例是让 LangChain 来生成图片的营销文案,我觉得这个示例挺有意思的,于是就想自己实现一下,顺便加深一下 LangChain 的学习。

今天就介绍一下如何使用 LangChain 来实现这个功能,并且介绍其中的实现细节,看完保证你也可以自己实现一个类似的功能。
学习目标
根据原示例的描述,是使用 LangChain 做一个可以将图片转换成文案的 Demo 程序,但这样功能可能比较简单,我们可以增加一些挑战,比如在输入参数中除了图片外,再增加一个主题的参数,生成的文案可以根据主题而变化,这样可以满足更多的需求。同时我们还可以做一个 WebUI,让用户可以通过浏览器来使用这个功能。目标如下:
-
使用 LangChain 实现图片转文案的功能
-
图片生成的文案可以根据主题而变化
-
可以通过一个 WebUI 页面来使用该功能
通俗易懂讲解大模型系列
- 用通俗易懂的方式讲解大模型:HugggingFace 推理 API、推理端点和推理空间使用详解
- 用通俗易懂的方式讲解大模型:使用 LangChain 封装自定义的 LLM,太棒了
- 用通俗易懂的方式讲解大模型:使用 FastChat 部署 LLM 的体验太爽了
- 用通俗易懂的方式讲解大模型:基于 Langchain 和 ChatChat 部署本地知识库问答系统
- 用通俗易懂的方式讲解大模型:使用 Docker 部署大模型的训练环境
- 用通俗易懂的方式讲解大模型:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
- 用通俗易懂的方式讲解大模型:Llama2 部署讲解及试用方式
- 用通俗易懂的方式讲解大模型:LangChain 知识库检索常见问题及解决方案
- 用通俗易懂的方式讲解大模型:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
- 用通俗易懂的方式讲解大模型:代码大模型盘点及优劣分析
- 用通俗易懂的方式讲解大模型:Prompt 提示词在开发中的使用
技术交流
建了大模型技术交流群! 想要学习、技术交流、获取如下原版资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

实现原理
海报文案生成的过程主要分两步:
-
先将图片转换成一段文字描述,这段文字可以精准描述图片中的内容
-
再将这段文字描述进行加工,生成简短、优雅且有吸引力的文案
这些操作都需要用到模型,将图片转成文字需要用到一些图生文模型,但一般的图生文模型都是基于英文的,所以生成出来的文字描述也是英文的,但没有关系,在后面的步骤中,我们可以用 LLM(大语言模型)将英文转换成中文,我们可以通过提示词工程技术来让 LLM 根据图片文字描述和主题来生成更有意境的中文文案。
图生文模型
首先我们需要让程序知道图片的内容是什么,我们可以用图生文的模型来获取图片描述。这里我们使用 Salesforce 的blip-image-captioning-base模型,该模型可以将图片转成一段简短的英文描述,它在 HuggingFace 上提供了免费的 API 供人们使用,我们可以调用它的免费 API 来进行图片转文字,示例代码如下:
import os
import requests
def image_to_text_by_file_path(image_path: str) -> str:
API_URL = "https://api-inference.huggingface.co/models/Salesforce/blip-image-captioning-base"
headers = {"Authorization": f"Bearer {os.getenv('HUGGING_FACE_API')}"} # 需要先设置 HuggingFace 上的 token
with open(image_path, "rb") as f:
data = f.read()
response = requests.post(API_URL, headers=headers, data=data)
img_desc = response.json()
return img_desc[0]["generated_text"]
代码中通过发送 post 请求来调用 API,请求参数是图片文件路径,调用 API 需要用到 HuggingFace 上的账号 token,请自行申请。这个 API 虽然是免费的,但有速率限制,你也可以在 HuggingFace 上基于这个模型部署自己的 API.
提示词工程
得到图片的文字描述之后,我们就可以用 LLM 来生成中文文案了,这一步的重点是提示词的构建,下面的代码示例中提供了一个可以满足需求的提示词模板,代码中调用 OpenAI 的 GPT3.5 模型来生成结果,示例代码如下:
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
def generate_chinese_desc(img_desc: str, theme: str) -> str:
chat = ChatOpenAI(temperature=1, model="gpt-3.5-turbo-0613")
prompt = f"""
You are a poster copywriting expert proficient in ancient Chinese classical literature.
You can redesign a textual description of an image into the style of classical Chinese,
producing 1 short yet profound classical Chinese copies, each not exceeding 10 words.
These copies should align with a theme described within the $$$ symbols.
The image's textual description is wrapped in ### symbols.
The final result should only contain the Chinese copy, without any additional information or the $ and # symbols.
Take a deep breath and think step by step.
image theme: $$${theme}$$$
image description: ###{img_desc}###
"""
messages = [HumanMessage(content=prompt)]
result = chat(messages)
return result.content
我们来了解下这段提示词:
-
我们的提示词是英文的,因为英文提示词在 GPT 中效果更好。
-
我们让 LLM 扮演一个精通中国古代文言文的海报文案专家,可以将一段图片的文字描述重新用文言文形式进行设计,因为我觉得古文的意境来做文案效果会更好。
-
图片和主题分别用不同的符号包裹以示区分。
-
提醒 LLM 输出结果不要包含额外的信息,特别是一些偶尔会在结果中出现的符号。
-
最后使用特殊的提示词关键字深呼吸和一步一步思考,来让 LLM 推理的效果更佳。
在示例代码中我们将 LLM 的 temperature 参数设为 1,这样可以让 LLM 生成的结果更具创造性。当然你也可以在这个提示词上再自行修改,看能否得到更好的效果,提示词构建本身就是一个不断优化迭代的过程。
LangChain Agent
有了图生文模型和提示词工程后,我们就可以实现图片转文案的功能了,首先我们使用 LangChain 的 Agent 模块来实现这个功能,在创建 Agent 之前我们需要先创建一个工具方法,这个工具方法会被 Agent 调用,示例代码如下:
from langchain.agents import tool
@tool()
def generate_poster_text(image_path: str, theme: str) -> str:
"""giva a image path and a theme to generate the copywriter in Chinese"""
img_desc = image_to_text_by_file_path(image_path)
result = generate_chinese_desc(img_desc, theme)
return result
我们用 LangChain 的@tool标签来创建一个工具方法,这个工具方法分别调用了之前示例代码中的 2 个方法,将图片转成文字描述和将图片描述转成中文文案。注意 LangChain 中的工具方法需要定义方法描述,就是方法名下面一行,Agent 会根据这个方法的描述来决定是否调用这个工具。
然后创建一个 Agent,示例代码如下:
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent, AgentType
def agent_output(promt: str) -> str:
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
tools = [multi_input_tool()]
agent = initialize_agent(
tools,
llm,
agent=AgentType.OPENAI_FUNCTIONS,
verbose=True,)
result = agent.run(promt)
return result
我们使用 initialize_agent方法来创建一个 Agent,这个方法接收一个工具列表和一个 LLM 模型,以及设置 Agent 的类型,这里我们使用的是AgentType.OPENAI_FUNCTIONS,更多的 Agent 类型可以查看 LangChain 的这个文档[2]。我们还将 Agent 中的verbose参数设置为 True,这样可以看到 Agent 内部的运行过程,方便调试。
最后运行一下这个 Agent,示例代码如下:
if __name__ == "__main__":
print(
agent_output(
"Use the generate_poster_text tool to generate the text content of the file 'img/flower.jpeg' and the theme is 'Love'"
)
)
在 Agent 的提示词中,我们要求 Agent 使用哪个工具,并且告诉它图片的路径和主题,运行结果如下:
> Entering new AgentExecutor chain...
Invoking: `generate_poster_text` with `{'tool_input': {'image_path': 'img/flower.jpeg', 'theme': 'Love'}}`
花束若相伴,万物皆独醉。The generated text content for the image 'img/flower.jpeg' with the theme 'Love' is: "花束若相伴,万物皆独醉。"
> Finished chain.
The generated text content for the image 'img/flower.jpeg' with the theme 'Love' is: "花束若相伴,万物皆独醉。"
可以看到最终 Agent 生成的文案是:花束若相伴,万物皆独醉,看起来效果还不错。
LangChain 多参数工具
刚才我们定义了工具方法后,其实还需要将这个工具方法形成一个工具,创建工具的示例代码如下:
from langchain.agents import Tool
def create_tool():
return Tool(
name="generate_poster_text",
func=generate_poster_text.run,
description="giva a image path and a theme to generate the copywriter in Chinese.",
)
但通过这个方式创建的工具只能接收一个参数,多参数的话运行方法会报错,在我们的示例中我们需要传递图片路径和主题 2 个参数。好在 LangChain 提供了 2 种方法来解决这个问题。
格式化参数方法
这种方法的核心思想就是将多个参数合并成一个参数,然后用分隔符来分隔,比如我们示例中的图片路径和主题参数,可以用img/flower.jpeg,Love这样的格式来表示,然后在工具方法中再将这个参数拆分成多个参数,示例代码如下:
@tool()
def generate_poster_text_string_format(input: str) -> str:
"""giva a image path and a theme to generate the copywriter in Chinese"""
[image_path, theme] = input.split(",")
img_desc = image_to_text_by_file_path(image_path)
result = generate_chinese_desc(img_desc, theme)
return result
我们重新定义了一个工具方法,这个方法只接受一个参数,然后在方法内部我们将方法参数拆分成多个参数,再调用之前的方法来实现图片转文案的功能。这种方式需要我们在工具的描述中写明参数的组成方式,示例代码如下:
def string_format_tool():
return Tool(
name="generate_poster_text",
func=generate_poster_text_string_format.run,
description="giva a image and a theme to generate the copywriter in Chinese. The input to this tool should be a comma separated list of "
"strings of length two. The first one is the value of image_path and the second one is the value of theme. "
"For example, `cats.png,Love` would be the input if you want to get value of image_path to cats.png and value of theme to Love",
)
在工具的描述字段中,我们写明了参数的有几个,参数名称是什么,以及用什么分隔符来连接,最后还给了一个示例,这样 LLM 在解析工具的时候就可以根据这个描述将多个参数整合成一个参数,然后再调用工具方法。
另外使用格式化参数方法,我们还需要将 Agent 的类型换成ZERO_SHOT_REACT_DESCRIPTION,示例代码如下:
-agent=AgentType.OPENAI_FUNCTIONS,
+agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
最终 Agent 的运行结果如下:
> Entering new AgentExecutor chain...
I should use the generate_poster_text tool to generate the text content for the given image and theme.
Action: generate_poster_text
Action Input: flower.jpeg,Love
Observation: 花开如水,爱在静谧。
Thought:The generated text content for the image 'flower.jpeg' and the theme 'Love' is "花开如水,爱在静谧。"
Final Answer: 花开如水,爱在静谧。
> Finished chain.
花开如水,爱在静谧。
多输入参数方法
另外一种方法是使用StructuredTool来创建工具,这样创建出来的工具就可以支持多参数了,示例代码如下:
from langchain.tools import StructuredTool
def multi_input_tool():
return StructuredTool.from_function(
name="generate_poster_text",
func=generate_poster_text.run,
args_schema=GeneratePosterTextInput,
description="giva a image path and a theme to generate the copywriter in Chinese.",
)
这里我们不用添加过多的工具描述,但需要我们定义好工具方法中的参数结构,上面的代码中我们定义了一个GeneratePosterTextInput类,示例代码如下:
from langchain.pydantic_v1 import BaseModel, Field
class GeneratePosterTextToolInput(BaseModel):
image_path: str = Field(..., description="the image path")
theme: str = Field(..., description="the theme name")
class GeneratePosterTextInput(BaseModel):
tool_input: GeneratePosterTextToolInput
我们定义了一个GeneratePosterTextToolInput类,这个类中定义了 2 个参数,分别是图片路径和主题,然后我们再定义一个GeneratePosterTextInput类,这个类中定义了一个tool_input参数,这个参数的类型就是GeneratePosterTextToolInput,这样就定义好了工具方法的参数结构。所有的多参数都必须包含在tool_input这个属性中,这样 Agent 才能正确的调用工具方法,否则 Agent 会报参数不匹配的错误。
如果没有定义参数的数据结构,Agent 就会自行给参数取名,一旦参数名称和方法参数名称不一致,也会导致报错。
使用多输入参数方法,需要使用 OPENAI_FUNCTIONS或STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION的 Agent 类型,运行效果之前已经演示过了,这里就不再重复演示。
关于 LangChain 工具的多参数方法信息,可以参考这里[3]。
WebUI
这个功能虽然可以使用 Agent 来实现,但实际上有点多余,其实核心方法就是generate_poster_text,我们可以直接调用这个方法来实现图片转文案的功能,我们可以用 Gradio 来写一个 WebUI 页面,在页面中调用这个方法,实现后的效果如下图所示:
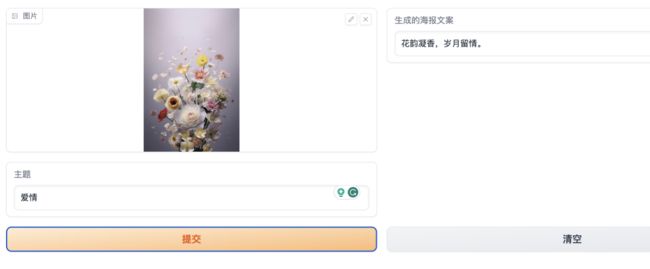
WebUI 在实现中与 Agent 不同的地方是,Agent 是通过图片路径来找到对应的图片,而在 WebUI 中是通过浏览器来上传图片,在 WebUI 中我们需要将上传的图片转成二进制数据,然后再调用图生文模型的方法,示例代码如下:
import os
import io
import requests
from PIL import Image
def image_to_bytes(img: Image.Image, format: str = "JPEG"):
# 创建一个BytesIO对象
buffered = io.BytesIO()
# 使用save方法将图片保存到BytesIO对象
img.save(buffered, format=format)
# 获取BytesIO对象的二进制内容
img_byte = buffered.getvalue()
return img_byte
def image_to_text_by_file(img: Image.Image) -> str:
API_URL = "https://api-inference.huggingface.co/models/Salesforce/blip-image-captioning-base"
headers = {"Authorization": f"Bearer {os.getenv('HUGGING_FACE_API')}"}
data = image_to_bytes(img)
response = requests.post(API_URL, headers=headers, data=data)
img_desc = response.json()
return img_desc[0]["generated_text"]
图片在 WebUI 上传上来后是一个PIL.Image.Image对象,我们使用image_to_bytes方法将其转成二进制数据,然后再调用图生文模型的 API,得到图片的文字描述。
小技巧
我们这个程序需要用到 OpenAI 的 API,但国内是无法直接访问的,所以需要在终端开启代理,但 Gradio 在代理模式下启动服务就会报错,错误信息如下:
ValueError: When localhost is not accessible, a shareable link must be created. Please set share=True or check your proxy settings to allow access to localhost.
这个问题要怎么解决呢?一种方法是调用 Azure 的 OpenAI API,这个 API 可以在国内访问,并且返回结果和 OpenAI 的 API 是一样的
另外有一种更简单的方法,就是设置一个no_proxy的环境变量,这样代理在访问这个环境变量下的地址时就不会启用代理,示例代码如下:
export no_proxy="localhost, 127.0.0.1, ::1"
这样在终端下,既可以开启代理,又能启动 Gradio 服务,我们的 WebUI 就可以正常启动了。
总结
本文介绍了如何使用 LangChain 来实现海报文案生成的功能,同时还介绍了其中的一些技术细节,文中的所有源码放在了这个仓库[5],感兴趣的同学可以去看看(顺便点个start),希望本文对你学习 LangChain 有所帮助。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
参考:
[2]这个文档: https://python.langchain.com/docs/modules/agents/agent_types/
[3]这里: https://python.langchain.com/docs/modules/agents/tools/multi_input_tool
[5]这个仓库: https://github.com/zhaozhiming/poster-copywriter-generator