机器学习----AndrewNg视频笔记记录08
如何构建神经网络密集负载(Neural Network intensive loads)

现在我们无需手动地将数据输入给第一层,然后第一层的激活值传给第二层.....我们只需告诉TensorFlow把这两层串在一起,这就是顺序函数密集流(sequential function intensive flow)的作用,在这里就会把layer1和layer2顺序连起来

如果你想训练这个神经网络,你需要利用一些参数去调用model.compile,然后你需要调用model.fit(x,y),它告诉TensorFlow去在这个利用sequential function构建的顺序密集的神经网络上对x和y进行训练
此外当你有一个新的训练样本Xnew(x,y)时,不需要你自己做前向传播一次一次的做计算,只需要对这个样本Xnew调用model.predict,就可以输出对应的a2,这里的model.predict会自动地使用我们利用sequential function构建的顺序函数密集流(sequential function intensive flow)
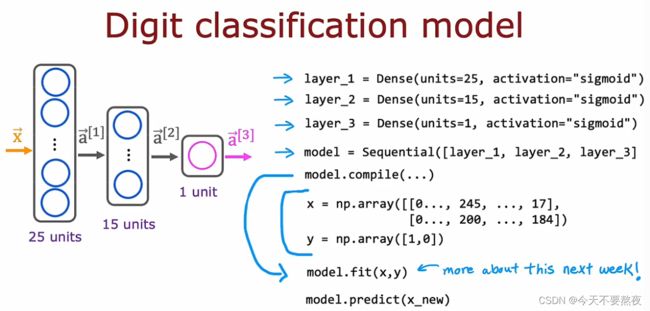
有时我们不单独将layer_1设定为dense型并指出其中的隐藏单元和激活函数,而是直接在Sequential里面体现

深入了解你的code在做什么
在这里的Python实现中我们将使用一维数组,这也是为什么这里np.array()里面是一个[],而不是两个[[]]表示的是二维矩阵

在计算出a1_1、a1_2和a1_3之后利用np.array组合到一起得到a1,那么a2的计算也同理
简化实现forward prop使其用于更通用的神经网络且无需为每个神经元编码
这里我们使用for循环去实现前向传播,在定义dense的时候,W.shape[1]得到的是二维矩阵的列也即这里的3,表示的是隐藏单元的数量,W.shape[0]指的是矩阵的行,即这里的2

np.zeros(units)就是初始化,把每个值都设为0,由于units=3,所以得到的是[0 0 0]
在for循环中的W[:,j ]求的是W的每一列,所以依次得到的是列向量[1 2]、[-3 4]、[5 -6]
然后把每个列向量利用np.dot进行点积计算以及plus,这里的g是激活函数,你可以选择不同的激活函数进行计算
对于shape[]的用法:
对于图像来说:
image.shape[0]——图片高
image.shape[1]——图片长
image.shape[2]——图片通道数
而对于矩阵来说:
shape[0]:表示矩阵的行数
shape[1]:表示矩阵的列数
注意的是有可能会出现的shape[-1]:-1代表的是最后一个,故而shape[-1]表示的是最后一个维度,如在二维张量里,shape[-1]表示列数
注意一下:大写字母指的是矩阵matrix,小写字母指的是向量和标量,所以这里的大写W指的是矩阵
对于前向传播引入向量化
神经网络可以向量化是使得神经网络规模越来越大的主要原因

对于X、W和B都写成矩阵的形式,所以这里都是两个[]得到二维数组
之后利用np.matmul对矩阵进行乘法运算,所以最后结果得到的也是一个行向量(1x3的矩阵)
matmul的实现原理
原理就是矩阵乘法,注意矩阵乘法的要点即可(前一个矩阵的列数=后一个矩阵的行数才可相乘)
矩阵乘法matmul的代码

其中@是调用matmul函数的另一种方式,但是np.matmul的方式更加清晰所以我们often使用matmul
并且对于矩阵的转置,Numpy提供了一种方式即:A.T
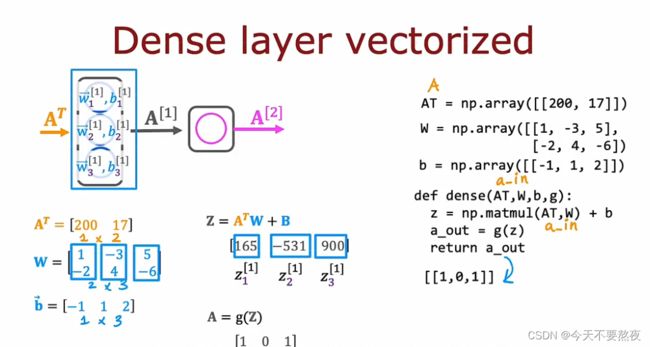
以上是在TensorFlow的实现方式
matmul利用了硬件进行并行计算所以计算的速度大幅提高