数据合并--Pandas
1. 键匹配合并:merge()函数
1.1 函数功能
合并DataFrame或者命名的Series,命名的Series被视为单列的DataFrame
1.2 函数语法
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=None, indicator=False, validate=None)
1.3 函数参数
| 参数 | 含义 |
|---|---|
| left | DataFrame或者命名的Series |
| right | DataFrame或者命名的Series |
| how | 合并方式:left:左合并;right:右合并;outer:并集;inner:取交集;cross:两个DataFrame的笛卡尔积;默认为:inner方式 |
| on | 合并的键,当两个DataFrame中均存在该键时使用 |
| left_on | 指定左边DataFrame中的键 |
| right_on | 指定右边DataFrame中的键 |
| left_index | 布尔型,默认取值为False,不清楚具体用法 |
| right_index | 布尔型,默认取值为False,不清楚具体用法 |
| sort | 布尔型,默认为True,不太理解 |
| suffixes | 合并两个DataFrame时,除键外还包含相同的列,如何对列进行命名,默认为(_x,_y),可以自己定义:长度为2的字符串序列 |
| copy | 默认取值为True,结果DataFrame为新的DataFrame |
| indicator | 是否新增一列表名数据来源的列,数据来源:left_only:左边DataFrame;right_only右边DataFrame;both:两个DataFrame |
| validate | ,字符串,可选参数,判定是否是指定的合并类型:“one_to_one” or “1:1”;“one_to_many” or “1:m”;“many_to_one” or “m:1”;“many_to_many” or “m:m” |
1.3.1 数据合并:默认合并方式
默认合并方式为:inner,两个DataFrame均有的数据将会被保留下来。可以观察到两个df中的键有相同的列名:cust_ID,因此,此时不需要单独指定left_on与right_on,可以直接使用on后面跟共同的列名
import pandas as pd
import numpy as np
cust = pd.read_csv('C:\\Users\\changyanhua\\Desktop\\customer.csv',encoding='gbk')
cred = pd.read_csv('C:\\Users\\changyanhua\\Desktop\\credit.csv',encoding='gbk')
print(cust)
print(cred)
data1 = pd.merge(cust, cred, on='cust_ID')
print(data1)

1.3.2 左/右合并
左合并,以左侧df的数据框为主,将右侧df的内容连接到左侧,左侧df的内容全部保留,右侧有无对应内容以空值填充。同理,可理解右合并。
data2 = pd.merge(cust, cred, on='cust_ID',how='left')
print(data2)
data3 = pd.merge(cust, cred, on='cust_ID',how='right')
print(data3)
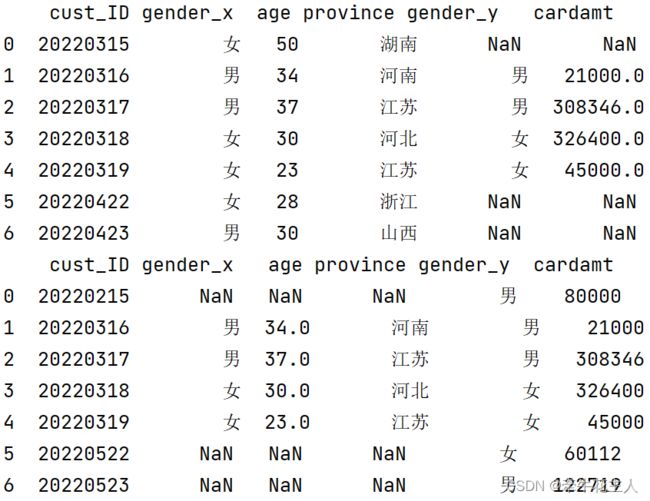
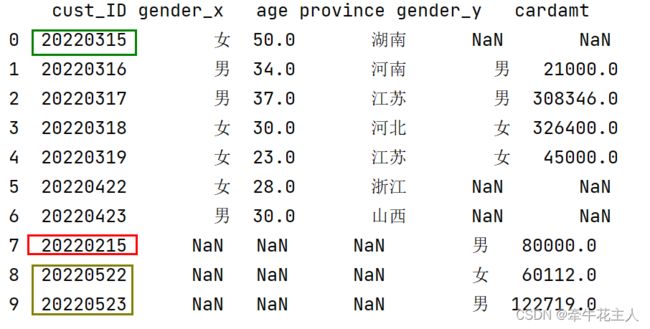
1.3.3 外连接
左右两边的内容均会出现在结果中,对应内容的内容以空值填充
data4 = pd.merge(cust, cred, on='cust_ID',how='outer')
print(data4)
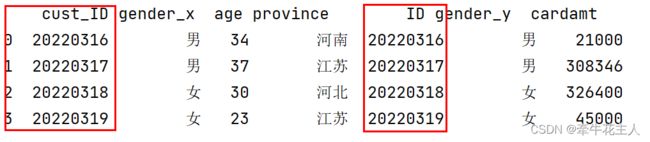
1.3.4 left_on与right_on
当两个df中的键列名不同时,需要分别指定两个df中的键
cred.rename(columns={'cust_ID':'ID'},inplace=True)
print(cred)
data5 = pd.merge(cust, cred, left_on='cust_ID',right_on='ID')
print(data5)
1.3.5 指定重复列的名称
cust = pd.read_csv('C:\\Users\\changyanhua\\Desktop\\customer.csv',encoding='gbk')
cred = pd.read_csv('C:\\Users\\changyanhua\\Desktop\\credit.csv',encoding='gbk')
print(cust)
print(cred)
data6=pd.merge(cust, cred, on='cust_ID',suffixes=['_cust','_cred'])
print(data6)

2. 拼接函数:cancat()
2.1 函数功能
沿着指定轴拼接对象
2.2 函数语法
pandas.concat(objs, *, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=None)
2.3 函数参数
| 参数 | 含义 |
|---|---|
| objs | 拼接的对象,可以是 |
| axis | 沿着哪个轴拼接:0或“index":按行合并;1或”columns":按列合并,默认按行 |
| join | 合并的时候axis外的索引对其方式: ‘inner’, ‘outer’,默认outer:取并集 |
| ignore_index | 布尔值,默认为False:保留原来对象的索引值;True:按照0,…n-1重新编排索引 |
| keys | 添加一级索引,以区分不同的合并对象,默认为None |
| levels | 构建多层索引,默认为None |
| names | 给层次索引添加标题,默认None |
| vertify_intergrity | 布尔值,检验连接后的轴是否存在重复值,默认False:不检查 |
| sort | 布尔值,默认False,对非拼接方向的索引进行排序 |
| copy | 默认值True |
2.3.1 默认参数拼接
此时拼接的结果按行拼接,列的对其方式是:outer,只有一个df中存在的列进行保留,索引值不会重新排列,保留原来的索引,不添加高一级的层级标题等内容,不对索引值是否重复进行校验。
cust1 = pd.read_csv('C:\\Users\\changyanhua\\Desktop\\cust1.csv',encoding='gbk')
cust2 = pd.read_csv('C:\\Users\\changyanhua\\Desktop\\cust2.csv',encoding='gbk')
print(cust1)
print(cust2)
cus1 = pd.concat([cust1,cust2])
print(cus1)

2.3.2 拼接只保留共同的列:join=inner
cus1 = pd.concat([cust1,cust2],join='inner')
print(cus1)

2.3.3 对合并方向的索引列重新标注索引
cus1 = pd.concat([cust1,cust2],join='inner',ignore_index=True)
print(cus1)

2.3.4 对非拼接方向的索引排序
cus1 = pd.concat([cust1,cust2],join='outer',ignore_index=True,sort=True)
print(cus1)
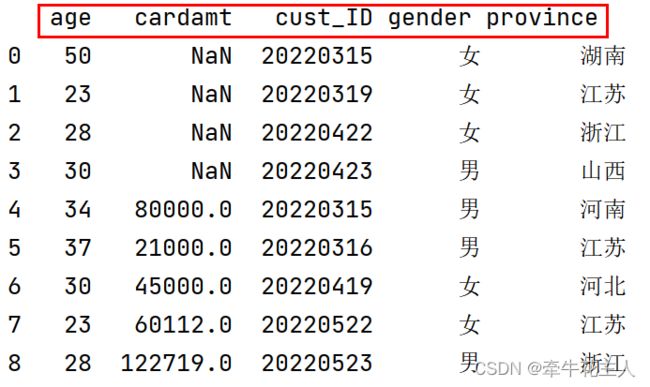
2.3.5 纵向拼接:axis=1
cust1 = pd.read_csv('C:\\Users\\changyanhua\\Desktop\\cust1.csv',encoding='gbk')
cust2 = pd.read_csv('C:\\Users\\changyanhua\\Desktop\\cust2.csv',encoding='gbk')
print(cust1)
print(cust2)
cus1 = pd.concat([cust1,cust2],join='outer',axis=1)
print(cus1)

cus1 = pd.concat([cust1,cust2],join='outer',axis=1,ignore_index=True)
print(cus1)
可以看到此时对索引进行重新标注是没有意义的,ignore_index=True适用于索引没有实际意义的情况。