python统计分析——单变量描述统计
资料来源于:用Python动手学统计学
1、求和
numpy.sum():要求求和的对象为数组格式。
也可以使用python的标准函数sum()。
2、平均数
numpy.mean()
3、计数
len()
4、方差
np.var();
注意ddof的参数设置。ddof即Delta Degrees of Freedom,表示自由度与样本容量年的差值。默认ddof=0,即自由度为n,此时np.var()相当于excel中的函数var.p(),计算结果为总体方差;当ddof=1时,代表自由度为n-1,此时np.var()相当于excel中的函数var.s(),计算结果为样本的无偏方差。
data_set=np.array([2,3,3,4,4,4,4,5,5,6])
var_p=np.var(data_set)
var_s=np.var(data_set,ddof=1)
print(var_p)
print(var_s)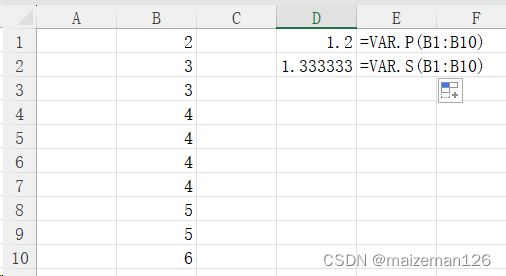
5、标准差
numpy.std()
ddof参数设置同numpy.var()。
data_set=np.array([2,3,3,4,4,4,4,5,5,6])
stdev_p=np.std(data_set)
stdev_s=np.std(data_set,ddof=1)
print(stdev_p)
print(stdev_s)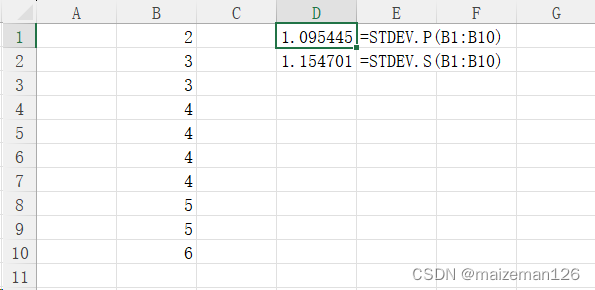
6、最大值和最小值
最大值:numpy.amax(),也可以使用python的标准函数max()。
最小值:numpy.amin(),也可以使用python的标准函数min()。
7、中位数
numpy.median()
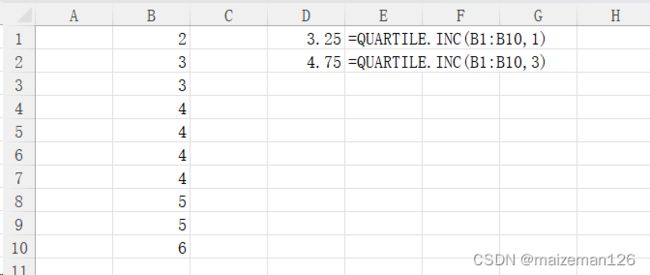
8、四分位数
下四分位数:scipy.stats.scoreatpercentile(dataset,25)
上四分位数:scipy.stats.scoreatpercentile(dataset,75)
import scipy as sp
data_set=np.array([2,3,3,4,4,4,4,5,5,6])
quartile_l=sp.stats.scoreatpercentile(data_set,25)
quartile_u=sp.stats.scoreatpercentile(data_set,75)
print(quartile_l)
print(quartile_u)对应excel中的函数为: