【深度学习】第二章:数据
深度学习:DNN
一、环境搭建
本来是打算从数据讲起的,但开讲前不搭建环境也说不过去,所以简单顺一下环境。
下面我们的深度学习都是基于pytorch框架的,所以第一步就是你要有pytorch模块。先安装anaconda,然后conda install pytorch torchvision torchaudio cpuonly ,这是cpu版本的pytorch。这个步骤是极其顺利的情况下的步骤,你如果遇到坑,就临时百度吧,都是可以解决的。GPU版本更麻烦一些。
此外, 以后我们在学习的过程中还会遇到一些其他第三方库,到时候就随时遇到随时讲解怎么安装和使用。
二、数据
学习一个算法或者一个架构之前,一定要先弄清楚这个算法或者架构适用的数据。
1、数据维度
下面的数据集是我们前面学机器学习算法时,遇到的第一个数据集:鸢尾花数据集。类似这种数据集的数据,我们一般称为二维表格数据,就是有行有列的的二维数据,其中行是一条一条的样本,列是样本的特征,样本和样本之间没有什么关联。DNN适用的数据就是这种类型的数据。就是你的数据要用DNN来跑,你要保证数据是一个二维的,行表示的是样本,列表示的是特征,还得带标签,行和行之间没有关系,这样才能用DNN来跑。
下面用鸢尾花数据集引入几个概念:样本、特征、标签、分类、回归、监督学习、无监督学习等,这些概念同样适用于深度学习。

目前公认的是小规模数据用机器学习模型就可以达到满意的效果;而对于超大规模数据得用深度学习模型才会达到期望的效果。
如何界定小规模和大规模?一般几万的样本量,或者说10万以内的样本量都属于小规模数据。而像图片数据、视频数据、文字数据、音频数据等数据一般都是大规模数据,因为比如一张图片,即使是最小的黑白手写数字图片也有28x28=784个特征,像这类数据都是大规模数据,此时用传统的机器学习算法是完全不行,就得用神经网络模型,才会有期望的效果。
2、数据类型
数据类型计算机存储、组织数据的方式,不同的数据处理框架都有自己对应的底层数据组织结构。下面就是鸢尾花数据集的各种数据不同的数据结构:
其中,1的字典结构是python的原生基本数据结构,2是numpy的array类型,3是pandas的dataframe数据类型。我们学DNN用的是pytorch框架,所以喂入DNN的数据就一定得是4,tensor类型的数据。也可见转化的时候也非常简单,用torch.tensor()就转了。
3、读取数据
并不是数据转化成tensor类型就万事大吉了,还得把数据的特征和标签打包到一起,然后再分训练集和测试集,然后再分小批次batch,才能一个一个batch地喂入DNN。
为什么这么繁琐?因为深度学习中的数据一般都是海量的,就是样本量非常多,比如10万以上的样本量。训练过程也不像机器学习中的算法模型一样,先把数据全部加载到内存,然后学习出一个模型。深度学习都是分批次batch加载数据的,分批次batch学习和迭代的,也正是这种机制才使得深度学习可以处理海量数据而避免内存不足的限制。
这个过程你可以自己手写函数进行打包-分训练集和测试集-分小批次,但是这里重点展示一下pytorch提供的函数:
使用TensorDataset对样本的特征和标签进行打包--使用random_split对打包好的样本分训练集和测试集--使用DataLoader对训练集和测试集进行分小批次。全过程就是下图的3、4、5这三个步骤:
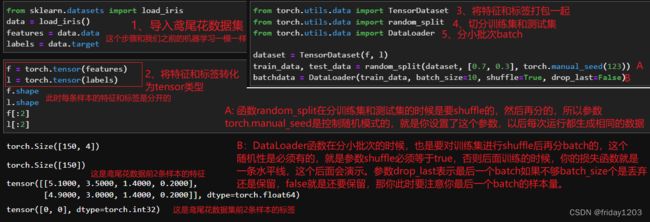
此时的batchdata对象就可以喂入DNN进行训练和学习了。但是我们还没讲架构,所以也不演示了,到架构章节再演示。下面我们再深入看看这几个对象:

其实上面的实现功能,你也可以不调包,自己手写一个打包函数和切分小批次的函数,也一样可以实现,这里只是要提醒你,在写切分函数和分batch函数时,一定一定要记得必须shuffle,否则你后面就无法学习和训练,出来的损失函数就是一条水平线。
另外要说的是,自己手动写的做法也仅适用于小型数据集。深度学习的数据量往往是非常大,并且一般都是分布式存储的,你手动打包数据,再shuffle数据后切分小批次,这个过程是需要大量的存储空间和计算资源支撑的。所以不建议自己手动实现。
说明:pytorch在对数据进行生成、打包、shuffle、切分、分小批次,以及数据预处理(比如转化数据类型、数据归一化)等操作,pytorch都是仅仅存储着数据转化的逻辑关系,不是真正的去新生成一些数据转化结果数据,而是生成一些映射式或者迭代式的对象,在使用的时候也是迭代查询或者递归查询这些对象,这种底层的巧妙设计机制主要就是为了适应海量数据而设计的。
4、更普适的数据读取方式
现实中,我们获取的数据往往是各种各样,除了数据类型外,数据的存储方式也是各异,比如特征和标签是两个文件存储的。所以pytorch还给我们提供了一个Dataset的类来封装数据,把数据封装成pytorch可以识别的数据结构,我们可以通过继承nn.Dataset这个类来读取我们自己的数据,这样读出来的数据还继承了nn.Dataset这个父类的、已经给我们封装好了的方法和属性,以后我们就可以直接使用,就非常方便了。这种方法其实在学DNN还不太用得到,以后学cnn了,数据集就会变得非常复杂,这个类就显得非常有用了,到时候也会有案例展示。这里先用鸢尾花数据集给大家演示一下继承nn.Dataset类读取数据的大致流程: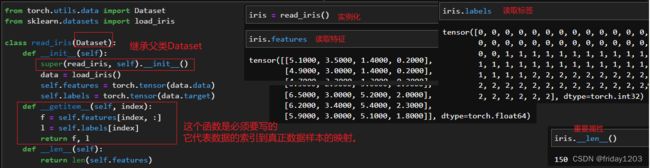
说明:我们在写这个类的时候,其中__getitem__方法是必须要写的,因为该方法是根据索引值获取每一个样本的特征和标签的,就是建立和实际数据直接的映射的,所以必须得写。像其他的方法,比如__len__方法,都是可有可无的,当然你可以根据你的需要,添加更多的方法。
当你通过这种方法读取数据后,就可以打包特征和标签--分训练集和测试集--分小批次--循环训练模型了。
总结:本部分是讲解DNN适用的数据,以及如何读取、打包、分隔、分batch这几个流程和步骤。
DNN适用的数据是二维表格数据,其中行表示样本,列表示特征;DNN是有监督学习算法,所以数据得带标签;样本和样本之间最好是没有关系,如果是时间序列的二维表格数据、或者是有语义的自然语义二维数据,DNN是学不出样本和样本之间的关系的。DNN学的是特征和特征之间的关系。
由于DNN是深度学习的入门,太简单了,所以数据也不复杂。所以数据读取和机器学习中的方式一样,数据类型转化-打包-分训练集和测试集-分小批次的过程也都不难,你可以自己手写实现这个过程也可以调包实现,具体的调包函数都有展示,大家对号取用即可。