《K8s 源码剖析及debug实战之 Kube-Scheduler(三):debug 到预选算法门口了》
文章目录
- 0. 引言
- 1. 调度算法代码入口
- 2. (g *genericScheduler) Schedule
- 3. findNodesThatFit
-
- 3.1 核心逻辑概览
- 3.2 参数 g.predicates 的来龙去脉
- 3.3 podFitsOnNode
- 4. 参考
0. 引言
欢迎关注本专栏,本专栏主要从 K8s 源码出发,深入理解 K8s 一些组件底层的代码逻辑,同时借助 debug Minikube 来进一步了解 K8s 底层的代码运行逻辑细节,帮助我们更好的了解不为人知的运行机制,让自己学会如何调试源码,玩转 K8s。
本专栏适合于运维、开发以及希望精进 K8s 细节的同学。同时本人水平有限,尽量将本人理解的内容最大程度的展现给大家~
前情提要:
《K8s 源码剖析及debug实战(一):Minikube 安装及源码准备》
《K8s 源码剖析及debug实战(二):debug K8s 源码》
《K8s 源码剖析及debug实战之 Kube-Scheduler(一):启动流程详解》
《K8s 源码剖析及debug实战之 Kube-Scheduler(二):终于找到了调度算法的代码入口》
文中采用的 K8s 版本是 v1.16。紧接上篇,本文主要介绍 K8s 的 Kube-Scheduler 源码的调度算法,主要是预选算法。
1. 调度算法代码入口
上篇我们总结了当前的调度算法的调用链路,如下图:

下面我们来详细介绍调度算法里面的内容。
2. (g *genericScheduler) Schedule
上篇介绍到,(g *genericScheduler) Schedule 里面的内容是对接口的实现,我将里面内容进行提炼下:
func (g *genericScheduler) Schedule(pod *v1.Pod, pluginContext *framework.PluginContext) (result ScheduleResult, err error) {
// 1. 检查pvc是否存在,不是很重要
if err := podPassesBasicChecks(pod, g.pvcLister);
// 2. 运行预过滤插件,一般不需要关注
preFilterStatus := g.framework.RunPreFilterPlugins(pluginContext, pod)
// 3. 更新node的信息,以最新的node缓存信息作为后续过滤、计算优先级的基础
if err := g.snapshot(); err != nil {
return result, err
}
// 4. 重要!!!关键方法,调度预选,predicate过滤不符合的node
filteredNodes, failedPredicateMap, filteredNodesStatuses, err := g.findNodesThatFit(pluginContext, pod)
// 5. 运行后置过滤插件,一般不需要关注
postfilterStatus := g.framework.RunPostFilterPlugins(pluginContext, pod, filteredNodes, filteredNodesStatuses)
// 6. 没找到一个符合要求的node,报错!
if len(filteredNodes) == 0 {}
// 7. 只找到一个符合要求的node,直接返回!
if len(filteredNodes) == 1 {}
// 8. 重要!!!上面如果找到多个node,那需要按照priority策略筛选
priorityList, err := PrioritizeNodes(pod, g.nodeInfoSnapshot.NodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders, g.framework, pluginContext)
// 9. 好了,最终选一个node吧!
host, err := g.selectHost(priorityList)
}
这里步骤里面,需要重点关注的是 findNodesThatFit,PrioritizeNodes,selectHost 这三个方法!下面来依次介绍!
3. findNodesThatFit
3.1 核心逻辑概览
先来介绍 findNodesThatFit 方法,实际执行的是调度的预选,即所谓的 predicate,我先把最核心逻辑的代码部分提炼出来:
func (g *genericScheduler) findNodesThatFit(pluginContext *framework.PluginContext, pod *v1.Pod) ([]*v1.Node, FailedPredicateMap, framework.NodeToStatusMap, error) {
// 定义一个方法,用来找到合适的node
checkNode := func(i int) {
...
// 用来找到合适node的方法
fits, failedPredicates, status, err := g.podFitsOnNode(
pluginContext,
pod,
meta,
g.nodeInfoSnapshot.NodeInfoMap[nodeName],
g.predicates,
g.schedulingQueue,
g.alwaysCheckAllPredicates,
)
...
}
// 并行来调用checkNode,协程数:min(allNodes, 16)
workqueue.ParallelizeUntil(ctx, 16, int(allNodes), checkNode)
...
}
在正式看 podFitsOnNode 方法之前,先关注下这里传入的参数,其中有一个关键参数 g.predicates,这里实际就是预先设置好的预选方法。
3.2 参数 g.predicates 的来龙去脉
那么有一个问题,g.predicates 的设置是怎么传递的呢,又是在哪里初始化设置的呢?理清这里的来龙去脉,需要花费一些功夫,这里就显示了 debug 代码的重要性,我把 debug 的一些中间过程展示下,方便更好理解:
在参数设置中,其中有一个环节会调用 pkg/scheduler/factory/plugins.go 的 GetAlgorithmProvider 方法,通过 debug 的内容可以看到 algorithmProviderMap 变量就保存着默认的 predicate 以及 priority 方法,而后续 g.predicates 的内容就是从这里传递过去的。
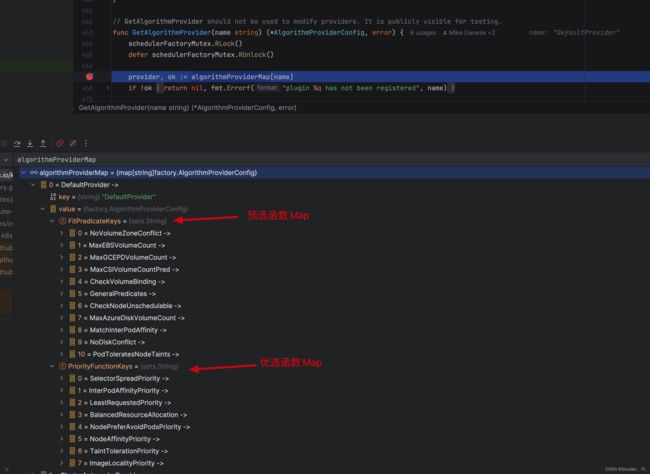
那么 algorithmProviderMap 变量的初始化又是在哪里呢?另外,上面的 name 又为什么是 DefaultProvider 呢?
先看第一个问题,algorithmProviderMap 变量的初始化。我沿着调用链路往上查找,最终发现在 pkg/scheduler/algorithmprovider/defaults.go 的 init() 方法中,就把 algorithmProviderMap 初始化了。
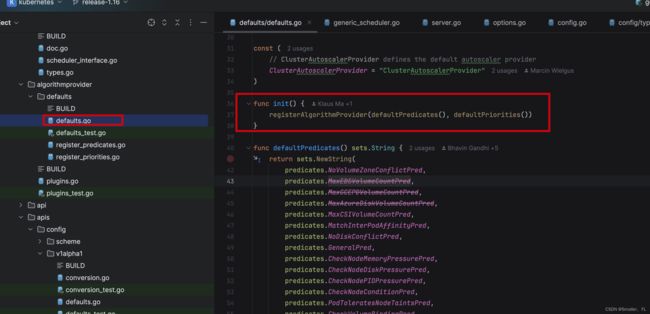
再看第二个问题,name 为什么是 DefaultProvider 。这个问题如果不是用 debug 的方法那就非常难查找。首先在设置 Config 参数过程中,先在 cmd/kube-scheduler/app/options/options.go 的 newDefaultComponentConfig 方法中进行一些缺省参数的设置。
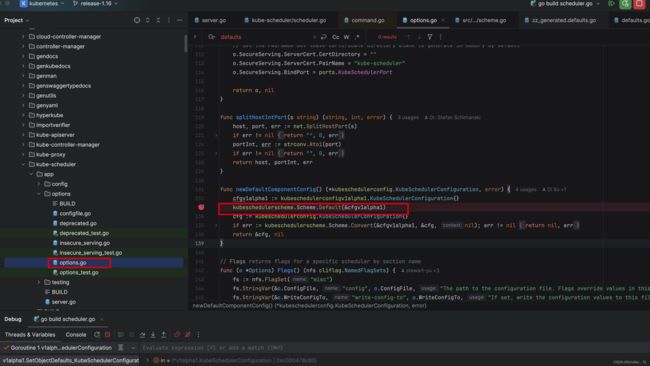
而 newDefaultComponentConfig 方法,实际调用了 zz_generated.defaults.go 方法的 SetDefaults_KubeSchedulerConfiguration 方法,就是在这里设置了 DefaultProvider 。熟悉 K8s Operator 编程 或者看过 K8s 源码的同志应该知道,这种 zz_generated.... 前缀的是自动用脚手架/工具生成的。通过把这个 func 内置到一个 defaulterFuncs Mapping 表中,遍历这个 defaulterFuncs Mapping 表去依次执行里面的方法,所以不用 debug 去深入看细节很难看清楚。
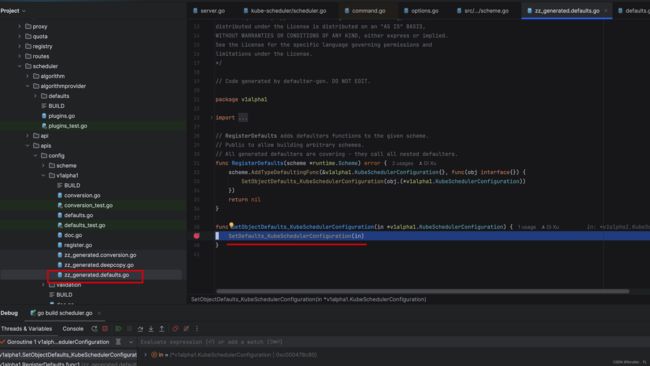
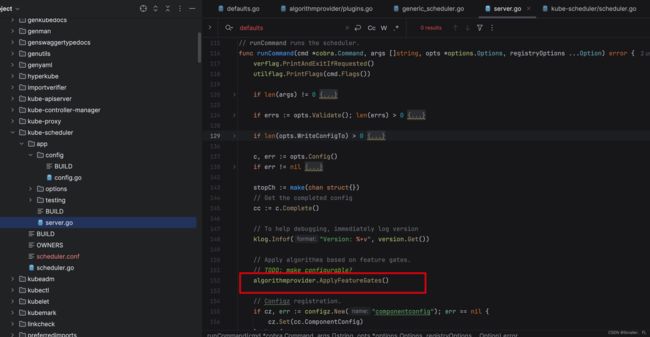
接下来就剩下最后一个问题了, pkg/scheduler/algorithmprovider/defaults.go 的 init() 方法是什么时候调用的呢?好吧,经过一番查找,其实是在开始的时候,在启动命令行 runCommand 方法中调用了 algorithmprovider.ApplyFeatureGates(),而这个方法引入了 pkg/scheduler/algorithmprovider 包,从而触发了 init() 方法,进而把algorithmProviderMap 初始化了!
3.3 podFitsOnNode
接下来看 podFitsOnNode,预选方法的逻辑,这里逻辑后续会展开讲,先看框架:
func (g *genericScheduler) podFitsOnNode(pluginContext *framework.PluginContext, pod *v1.Pod, meta predicates.PredicateMetadata, info *schedulernodeinfo.NodeInfo, predicateFuncs map[string]predicates.FitPredicate, queue internalqueue.SchedulingQueue, alwaysCheckAllPredicates bool) (bool, []predicates.PredicateFailureReason, *framework.Status, error) {
// 执行两次
for i := 0; i < 2; i++ {
if i == 0 {
// 第一次,特殊处理
podsAdded, metaToUse, nodeInfoToUse = addNominatedPods(pod, meta, info, queue)
} else if !podsAdded || len(failedPredicates) != 0 {
break
}
// 按照预设的predicate表依次执行
for _, predicateKey := range predicates.Ordering() {
// 真正执行 predicate
if predicate, exist := predicateFuncs[predicateKey]; exist {
fit, reasons, err = predicate(pod, metaToUse, nodeInfoToUse)
}
}
...
}
}
这期内容差不多了,下一节继续分析!
4. 参考
《K8s 源码剖析及debug实战(一):Minikube 安装及源码准备》
《K8s 源码剖析及debug实战(二):debug K8s 源码》
《K8s 源码剖析及debug实战之 Kube-Scheduler(一):启动流程详解》
《K8s 源码剖析及debug实战之 Kube-Scheduler(二):终于找到了调度算法的代码入口》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
也欢迎关注我的wx公众号:一个比特定乾坤