论文:VRKitchen: an Interactive 3D Virtual Environment for Task-oriented Learning
摘要
介绍
一个真正智能的Agent应该能够通过适应未知的环境来解决物理世界中大量复杂的任务,并通过规划长序列的动作来达到预期的目标,这仍然超出了现有机器模型的能力。 这就产生了推进任务型学习研究的必要性。 特别是,我们对以下三个面向任务的学习问题感兴趣。
学习动态环境的视觉表现
在动态环境中解决一个任务的过程中,同一对象的外观可能会因为动作的结果而发生剧烈的变化。为了捕捉对象外观的这种变化,需要智能体对环境动态有一个更好的可视化表示。 例如,智能体应该可以识别西红柿,即使它被切成碎片并放入容器。 要获得这样的视觉知识,重要的是智能体从物理交互中学习,并对对象状态变化的潜在因果关系进行推理。 在实验室环境中实现基于交互的学习已经有了一些工作,但是有限的场景极大地限制了先前工作的可扩展性和可重复性。 相反,我们认为建立一个仿真平台是一个很好的选择,因为i)不同算法的性能可以很容易地评估和基准测试,ii)大量不同的和现实的环境和任务可以被设计和定制。
学习为复杂任务生成长期计划
一个复杂的任务往往由各种子任务组成,每个子任务都有自己的子目标。 因此,智能体需要采取一系列很长的动作来完成任务。 样本空间中的大量可能行动和极其稀疏的奖励使得很难将策略导向正确的方向。 近年来,许多研究者关注简单域中的分层策略学习。在这项工作中,我们提供了一个现实的环境,在这个环境中,智能体可以学习为人类在现实世界中遇到的日常生活任务制定长期计划。
从人类演示到引导智能体模型的学习
在复杂环境中从头开始训练一个智能体是极其困难的。 为了引导训练,通常让智能体通过观看人类演示来模仿人类专家。 以往的研究表明,从演示中学习(或模仿学习)显著提高了学习效率,取得了比强化学习更高的性能。 然而,高质量地收集多样的人类演示既昂贵又耗时。 我们相信虚拟现实游戏可以为我们提供一个理想的媒介,让我们从广泛的用户那里聚集源演示。

在这项工作中,我们重点在一个虚拟厨房环境VRKitchen中模拟烹饪活动和两组烹饪任务(使用常用工具和准备菜肴)。 在图1所示的示例中,我们说明了该系统如何解决三个面向任务的学习问题的出现的需求,其中一个Agent在我们系统中创建的厨房中的一个厨房里做了一个三明治。
该环境允许智能体与不同的工具和成分交互,并模拟各种对象的变化。 例如,面包在烤箱里加热时会改变颜色,西红柿切开后会变成薄片。 Agent在执行烹饪任务时与物理世界的交互将导致对象的外观和物理性质发生较大的变化和时间变化,这就需要一种面向任务的视觉表示方法。
要做一个三明治,智能体需要执行一系列的动作,包括从冰箱里取出配料,把奶酪和火腿放在面包上,烤面包,加一些番茄片,在面包上放一些酱汁。为了快速、成功地达到最终目标,必须使智能体具备进行长期规划的能力。
我们构建了两个界面,让人工智能算法和用户分别控制内置智能体,这样人类可以在世界任何地方使用VR设备进行演示,而人工智能算法可以从这些演示中学习,在相同的虚拟环境中执行相同的任务。
本文贡献
一种可配置的虚拟厨房环境,具有逼真的三维物理模拟,使烹饪任务具有丰富的对象状态变化和组成目标;
一个工具包,包括一个基于虚拟现实的用户界面,用于收集人类演示,以及一个Python API,用于在虚拟环境中训练和测试不同的AI算法;
提出了一个新的挑战--VR Chef挑战,为不同方法在复杂三维环境中的学习效率提供标准化的评估;
一个新的各种烹饪任务的人类演示数据集--UCLA VR厨师数据集。
VR-Kitchen环境
框架结构
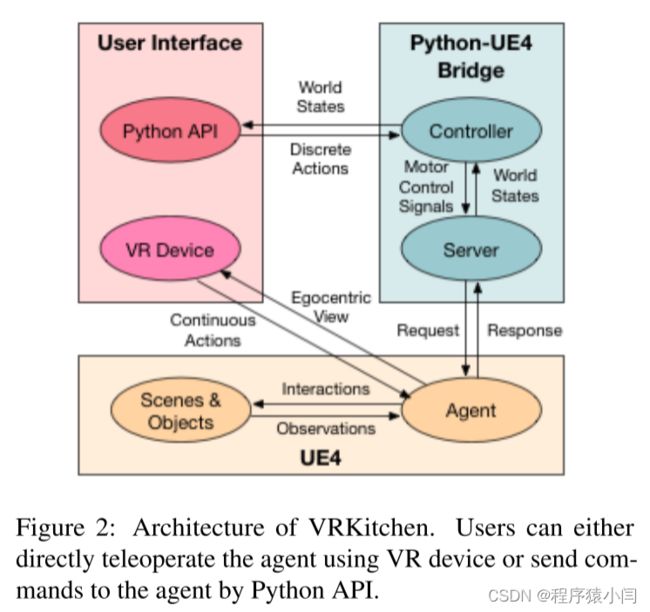
图2给出了VRKitchen体系结构的概述。 具体来说,我们的系统由三个模块组成:(1)物理引擎和真实感渲染模块由多个仿人智能体和厨房场景组成,每个智能体和场景中都有一些执行烹饪活动所必需的食材和工具;(2)用户界面模块,允许用户或算法通过虚拟现实设备或Python API执行任务;(3)一个Python-UE4桥接器,它将高层命令传输到电机控制信号并发送给智能体。
物理引擎与真实感渲染
UE4作为一个流行的游戏引擎,提供了物理模拟和照片真实感渲染,这对创建真实感环境至关重要。在此基础上,我们设计人形智能体、场景、对象状态变化和细粒度动作,如下所示。
人形智能体
Agent的动画可以分解为不同的状态,如行走、空闲。 每个智能体都被一个用于碰撞检测的胶囊包围:当它行走时,如果它与场景中的任何物体碰撞,它将无法导航到新的位置。 当Agent处于空闲状态时,它可以自由地与身体一定范围内的物体进行交互。
场景

VRKitchen由16个完全交互的厨房场景组成,如图4所示。 智能体可以与场景中的大多数对象进行交互,包括各种工具、容器和配料。 每个厨房都是基于常见的家庭设置手工设计和创建的。 厨房中家具和用具的3D模型首先从SUNCG数据集中获得。 一些模型被分解以创建必要的对象交互,例如,我们重新组装门和橱柜来创建打开和关闭门的效果。在场景中有了基本的家具和用具后,我们再添加烹饪材料和工具。 我们不是随机取样,而是根据物品的用途来放置物品,例如,工具放在橱柜上,而水果和蔬菜等易腐食材放在冰箱里。 平均一个场景中有55个交互对象。
对象状态变化

VRKitchen的一个关键因素是模拟对象状态变化的能力。 VRKitchen不是只显示动作的前置条件和后置效果,而是模拟动作引起的物体的连续几何和拓扑变化。 这导致了大量可用的烹饪活动,如烤、去皮、舀、倒、混合、榨汁等。总体而言,VRKitchen有18种可供选择的烹饪活动。 图5显示了一些对象交互和状态更改的示例。
细粒度动作
在以前的平台中,对象通常被视为一个整体。 然而,在现实世界中,人们对物体的不同部位采取不同的行动。 例如。 要从咖啡机里取咖啡,人们可以先按电源按钮打开机器,然后按冲泡按钮冲泡咖啡。 因此,我们以组合的方式设计系统中的对象,即一个对象有多个组件,每个组件都有自己的功能。这将现有系统中的典型操作空间扩展到更大的细粒度操作集合,并使智能体能够学习与对象相关的因果关系和常识。
用户界面
通过一个详细的人类具身表示,可以获得多层次的人-对象-交互。 特别是,用户提供此类演示的方法有两种:

用户可以直接控制智能体的头和手。 在遥操作期间,使用一套现成的VR设备记录动作,在我们的例子中,是一个Oculus Rift头戴式显示器(HMD)和一对Oculus触摸控制器。 两个Oculus传感器用于跟踪耳机和控制器在三维空间中的变化。 然后,我们将数据应用到虚拟环境中的人类化身:化身的头部和手部运动与人类用户的相对应,而其身体的其他部分通过内置的逆运动学求解器(向前和向后到达逆运动学,或Fabrik)进行动画。 人类用户可以使用拇指在空间中自由导航,并使用控制器上的触发器按钮抓取物体。 图6给出了为连续动作收集演示的示例。 用户可以通过在VRKitchen中做任务来提供演示。这些数据可以用来初始化虚拟Agent的策略,并通过与虚拟环境的交互来改进策略。
Python API提供了一种从用户获取离散操作序列的方法。 特别地,它提供世界状态并接收离散的动作序列。 世界状态由附近对象的位置和当前状态以及Agent第一人称视图的RGB/Depth图像组成。 图8和图9显示了从第三人视图中记录的任务、披萨和烤肉的人类演示示例。
Python-UE4桥接器
Python-UE4桥包含一个通信模块和一个控制器。Python服务器与游戏引擎通信,从环境接收数据并向智能体发送请求。它通过socket与engine相连。为了执行一个操作,服务器向UE4发送一个命令并等待响应。游戏引擎中的客户端解析命令并将相应的动画应用于智能体。包含附近对象状态的有效负载、Agent的第一人称摄像机视图(根据RGB、深度和对象实例分段)以及其他与任务相关的信息被发送回Python服务器。 该过程重复进行,直到到达终端状态。
该控制器既能实现低电平电机控制,又能实现高电平命令。 低级控制改变智能体的身体、头部和手的局部平移和旋转,而其他身体部分使用Fabrik动画。 高级命令执行原子操作,如获取或放置对象,通过利用低级控制器进一步实现。 例如,为了用刀切胡萝卜,高级控制器迭代地更新手的位置,直到刀到达胡萝卜。
性能
一个典型的交互,包括发送命令、执行操作、呈现框架和获取响应,对于一个线程来说大约需要0.066秒(每秒15个操作)。RGB、深度和对象分割图像的分辨率默认为84×84。
VR挑战
在本文中,我们提出了由两组烹饪任务组成的VR厨师挑战:(a)工具使用,其中学习运动控制是主要挑战;和(b)准备菜肴,其中涉及到组成目标,并且存在隐藏的任务依赖关系(例如,需要按照一定的顺序准备食材)。 第一组任务要求Agent不断地控制它的手来使用一个工具。 在第二组任务中,智能体必须按照正确的顺序执行一系列原子动作以实现最终目标。
工具使用
根据环境中的可用动作和状态变化(如图5所示),我们设计了5个工具使用任务:切割、剥离、开罐、倒罐和取水。 这些任务在烹饪中很常见,需要精确控制Agent的手来改变物体的状态。 一旦它采取正确的工具和每次对象的状态被改变,智能体将获得奖励。 这些任务的定义显示如下:
切:用刀把一根胡萝卜切成四块。 智能体从得到刀和每一次切割中获得报酬。
削皮:用削皮器将猕猴桃削皮。智能体从获得削皮器和每个削皮的皮肤中获得奖励。 注意,只有当削皮器在一定的旋转范围内接触皮肤时,皮肤才会被削皮。 如果剥下足够多的皮,任务就完成了。
开罐:用开罐器开罐。在盖子的周围,有四个侧面。盖子的一侧如果与刀片重叠就会破裂。智能体从拿开瓶器和打破盖子的每一面中获得奖励。
倒水:取一个装满水的杯子,将水倒入空杯子。 该智能体获得奖励,以采取完整的杯子和每一个额外数量的水添加到空杯子。 只有当杯子装满50%以上时,任务才算完成。
取水:拿一个空杯子,从水龙头里取水。智能体拿着杯子,每往里面加一杯水,就会得到奖励。 只有当杯子装满50%以上时,任务才算完成。