初始C++(一)---命名空间、输入输出、缺省参数
目录
1.命名空间
定义命名空间
using 指令
命名空间的嵌套
2、C++输入输出
标准输出流(cout)
标准输入流(cin)
3.缺省参数
1.命名空间
定义命名空间
假设这样一种情况,当一个班上有两个名叫张三 的学生时,为了明确区分它们,我们在使用名字之外,不得不使用一些额外的信息,比如他们的家庭住址,或者他们父母的名字等等。
同样的情况也出现在 C++ 应用程序中。例如,您可能会写一个名为 rand() 的函数,在另一个可用的库中也存在一个相同的函数 rand()。这样,编译器就无法判断您所使用的是哪一个 rand() 函数。
因此,引入了命名空间这个概念,专门用于解决上面的问题,它可作为附加信息来区分不同库中相同名称的函数、类、变量等。使用了命名空间即定义了上下文。本质上,命名空间就是定义了一个范围。
我们举一个计算机系统中的例子,一个文件夹(目录)中可以包含多个文件夹,每个文件夹中不能有相同的文件名,但不同文件夹中的文件可以重名。
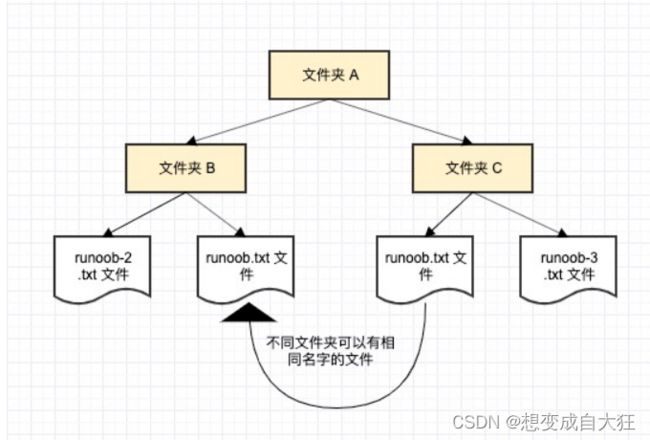
命名空间的定义使用关键字 namespace,后跟命名空间的名称
namespace namespace_name {
// 代码声明
}为了调用带有命名空间的函数或变量,需要在前面加上命名空间的名称
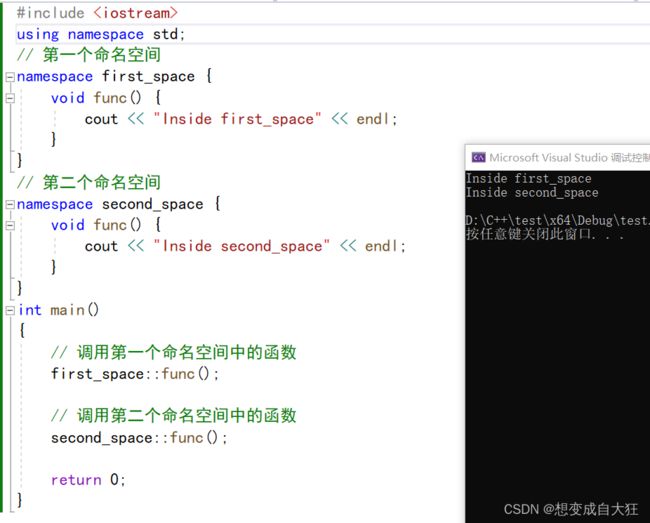
name::code; // code 可以是变量或函数#include
using namespace std;
// 第一个命名空间
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二个命名空间
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
int main ()
{
// 调用第一个命名空间中的函数
first_space::func();
// 调用第二个命名空间中的函数
second_space::func();
return 0;
} 
using 指令
你可以使用 using namespace 指令,这样在使用命名空间时就可以不用在前面加上命名空间的名称。这个指令会告诉编译器,后续的代码将使用指定的命名空间中的名称。
#include
using namespace std;
// 第一个命名空间
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二个命名空间
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
using namespace first_space;
int main ()
{
// 调用第一个命名空间中的函数
func();
return 0;
}  using 指令也可以用来指定命名空间中的特定项目。例如,如果你只打算使用 std 命名空间中的 cout 和endl(换行)部分,可以使用如下的语句:
using 指令也可以用来指定命名空间中的特定项目。例如,如果你只打算使用 std 命名空间中的 cout 和endl(换行)部分,可以使用如下的语句:
#include
//将常用的展开
using std::cout;
using std::endl;
int main()
{
cout << "Hello World" << endl;
return 0;
} 随后的代码中,在使用 cout 和endl时就可以不用加上命名空间名称作为前缀,但是 std 命名空间中的其他项目仍然需要加上命名空间名称作为前缀。
#includeusing namespace std; namespace A { int a = 100; namespace B //嵌套一个命名空间B { int a = 20; } } int a = 200;//定义一个全局变量 int main(int argc, char *argv[]) { cout << "A::a =" << A::a << endl; //A::a =100 cout << "A::B::a =" << A::B::a << endl; //A::B::a =20 cout << "a =" << a << endl; //a =200 cout << "::a =" << ::a << endl; //::a =200 using namespace A; cout << "a =" << a << endl; // Reference to 'a' is ambiguous // 命名空间冲突,编译期错误 cout << "::a =" << ::a << endl; //::a =200 int a = 30; cout << "a =" << a << endl; //a =30 cout << "::a =" << ::a << endl; //::a =200 //即:全局变量 a 表达为 ::a,用于当有同名的局部变量时来区别两者。 using namespace A; cout << "a =" << a << endl; // a =30 // 当有本地同名变量后,优先使用本地,冲突解除 cout << "::a =" << ::a << endl; //::a =200 return 0; }
命名空间的嵌套
命名空间可以嵌套,可以在一个命名空间中定义另一个命名空间
namespace namespace_name1 {
// 代码声明
namespace namespace_name2 {
// 代码声明
}
}
// 访问 namespace_name2 中的成员
using namespace namespace_name1::namespace_name2;
// 访问 namespace_name1 中的成员
using namespace namespace_name1;2、C++输入输出
C++ 的 I/O 发生在流中,流是字节序列。如果字节流是从设备(如键盘、磁盘驱动器、网络连接等)流向内存,这叫做输入操作。如果字节流是从内存流向设备(如显示屏、打印机、磁盘驱动器、网络连接等),这叫做输出操作。
标准输出流(cout)
预定义的对象 cout 是 iostream 类的一个实例。cout 对象"连接"到标准输出设备,通常是显示屏。cout 是与流插入运算符 << 结合使用的。
#include
using namespace std;
int main( )
{
char str[] = "Hello C++";
cout << "Value of str is : " << str << endl; 标准输入流(cin)
预定义的对象 cin 是 iostream 类的一个实例。cin 对象附属到标准输入设备,通常是键盘。cin 是与流提取运算符 >> 结合使用的。
#include
using namespace std;
int main( )
{
char value[50];
cout << "请输入: ";
cin >> value;
cout << "输入的值是: " << value<< endl;
} 1. 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件 以及按命名空间使用方法使用std。
2. cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含< iostream >头文件中。
3. <<是流插入运算符,>>是流提取运算符。
4. 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。 C++的输入输出可以自动识别变量类型。
3.缺省参数
c++中,定义函数的时候可以让最右边的连续若干个参数有缺省值,在调用函数的时候,如果不写相应位置的参数,则调用的参数就为缺省值。
void Func(int a = 0)
{
cout<全缺省参数 (缺省全部参数)
#include
using namespace std;
//全缺省
void Func(int a = 10, int b = 20, int c = 30)
{
cout <<"a=" << a << endl;
cout <<"b=" << b << endl;
cout <<"c="<< c << endl << endl;
}
int main()
{
Func();//a=10,b=20,c=30
Func(1);//a=1,b=20,c=30
Func(1,2);//a=1,b=2,c=30
Func(1,2,3);//a=1,b=2,c=3
return 0;
} 
半缺省参数 (缺省部分参数)
//半缺省---必须从右往左缺省,必须连续缺省
//void Func(int a, int b = 20, int c = 30) //缺省一个
void Func(int a, int b, int c = 30)//缺省两个
{
cout << "a=" << a << endl;
cout << "b=" << b << endl;
cout << "c=" << c << endl << endl;
}
int main()
{
Func(1,2);//a=1,b=2,c=30
Func(1,2,3);//a=1,b=2,c=3
return 0;
}1. 半缺省参数必须从右往左依次缺省
2. 缺省参数不能在函数声明和定义中同时出现
//a.h void Func(int a = 10);
// a.cpp void Func(int a = 20) {}
// 注意:如果生命与定义位置同时出现,恰巧两个位置提供的值不同,
那编译器就无法确定到底该用哪个缺省值。
3. 缺省值必须是常量或者全局变量
4. C语言不支持(编译器不支持)
缺省参数的应用
栈的初始化使用,提高效率
struct Stack
{
int* a;
int top;
int capacity;
};
void StackInit(struct Stack* ps,int capacity = 4)
{
ps->a=(int*)malloc(sizeof(int) * capacity);
ps->top = 0;
ps->capacity = capacity;
}
void StackPush(struct Stack* ps, int x)
{
//...
}
int main()
{
Stack st;
StackInit(&st);//不知道栈最多存多少个数据,用缺省参数
StackInit(&st,100);//知道栈最多存100个数据,显示传值,减少增容次数,提高效率
return 0;
}函数缺省参数的作用在于提高程序的可扩充性。比如某个以及写好的函数需要添加新的参数,而原先调用函数的的那些语句未必需要新增加的参数,为了避免对原来所有调用该函数的地方进行修改,就可以使用函数缺省参数了。