从零开始写项目第四篇【搭建Linux环境】
使用SSH连接Linux环境
经过十多天的时间,我的网站备案终于完成了…接下来我就收到了阿里云的邮件。它让我在网站首页的尾部添加备案号,貌似还需要去公安网站中再备案什么资料的。
2017年11月20日19:06:26在图书馆并没有带身份证、于是就得放一下了。
接下来,我就是要把我写的东西放在Linux下了。首先,我得连接Linux系统,通过阿里云的远程服务可以连接得到。
密码可以在阿里云中设置,用户名是root,开始的时候我并不知道用户名是root,看了一下子文档才知道…
然后阿里云文档中还说了可是使用ssh来连接,可是我根据它的教程怎么都连不上,我还以为是什么地方错误了。
后来在ping一下公网的时候,发现根本ping不通…原来在使用SSH连接Linux的时候还需要配置安全组!
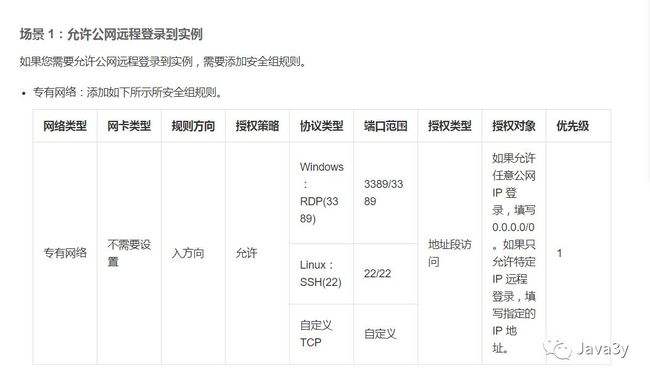
不得不说,我的linux还真是不熟练,以此机会多接触一下linux才行。
配置完安全组以后,我就可以带putty中使用SSH连接Linux了。
2017年11月21日10:15:18 花了点时间去回顾了一下Linux的命令了,现在来搭建JavaEE环境了
下载开发环境用到的tar包
下载JDK
去oracle官网找了一下,我的开发环境使用的是JDK1.7版本的,但是oracle官网找jdk1.7起来有点麻烦,我找到了教程:
https://jingyan.baidu.com/album/9989c746064d46f648ecfe9a.html?picindex=5
于是我就在http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html中找到了链接下载
直接复制那个链接到迅雷下载就行了,那么就不用登陆了。
我是下载了tar包..
下载Mysql
同样是在oracle官网中需找,找到对应的链接:https://dev.mysql.com/downloads/mysql/5.6.html#downloads

下载Tomcat
对于Tomcat下载就非常方便了,可以直接找到我开发环境使用的Tomcat7
https://tomcat.apache.org/download-70.cgi
也是同样下载tar包
下载Elasticsearch
Elasticserach的下载还是非常方便的,提供搜索来进行下载。这里我就不贴链接了。直接去官网找就行了。或者去我的Elasticsearch学习记录中找。
下载了2.3.3版本,因为我在windows开发的时候也是下载2.3.3版本的,就为了保持一致吧。
解压并配置环境
安装Java
安装Java还是顺利的
tar -zxvf jdk1.7.tar.gz 编辑配置文件 vim /etc/profile 在配置文件后添加下面的内容 export JAVA_HOME="/opt/jdk1.7.0_80" export PATH="$JAVA_HOME/bin:$PATH" 刷新配置文件 source /etc/profile
vim /etc/profile
在配置文件后添加下面的内容
export JAVA_HOME="/opt/jdk1.7.0_80"
export PATH="$JAVA_HOME/bin:$PATH"
刷新配置文件
source /etc/profile
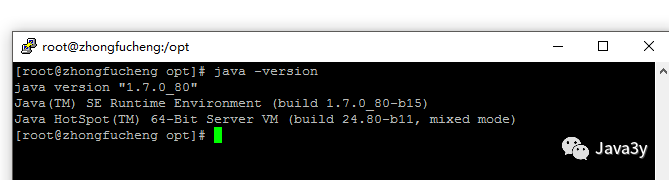
测试:
java -version
安装Tomcat
Tomcat版本是7
安装Tomcat也是非常方便的,也是直接解压。
在其中遇到了一个问题,启动tomcat时,一直卡在Deploying web application directory
最后找到了解决方案:http://www.cnblogs.com/jtlgb/p/7063863.html
开启和关闭Tomcat
./startup.sh ./shutdown.sh
查看Tomcat是否开启了的方法
启动linux进入到tomcat安装目录 /apache-tomcat-6.0.26/bin下运行 #./startup.sh start 停止tomcat时运行命令: #./shutdown.sh start 远程查看tomcat的控制台 进入tomcat/logs/文件夹下 键入指令:tail -f catalina.out 就可以查看控制台了.26/bin下运行 #./startup.sh start 停止tomcat时运行命令: #./shutdown.sh start 远程查看tomcat的控制台
进入tomcat/logs/文件夹下 键入指令:tail -f catalina.out 就可以查看控制台了
linux或者部分unix系统提供随机数设备是/dev/random 和/dev/urandom ,两个有区别,urandom安全性没有random高,但random需要时间间隔生成随机数。jdk默认调用random。然后就很简单啦,找到对应的配置文件去修改就好了找到jdk1.x.x_xx/jre/lib/security/Java.security文件,在文件中找到securerandom.source这个设置项,将其改为:securerandom.source=file:/dev/./urandom
两个有区别,urandom安全性没有random高,但random需要时间间隔生成随机数。jdk默认调用random。
然后就很简单啦,找到对应的配置文件去修改就好了
找到jdk1.x.x_xx/jre/lib/security/Java.security文件,在文件中找到securerandom.source这个设置项,将其改为:
securerandom.source=file:/dev/./urandom
再次将Tomcat启动的时候,就可以顺利启动了。在windows下访问linux下的Tomcat

安装Mysql
Mysql的版本是5.6.38
摘要自http://blog.csdn.net/1099564863/article/details/51622709
和https://www.cnblogs.com/idnf/p/4590818.html
这篇是最后成功的:http://blog.csdn.net/wplblog/article/details/52179299
安装Mysql就用了我非常多的时间、有的博客前面和后面的目录结构是对不上的、装了我好久….哎。
下面就从各个博客中摘抄我成功安装Mysql的记录吧:
安装 所需小环境 (此部分我不知道有什么用,以后知道了再来补吧)
[root@localhost ~]# yum -y install make bison-devel ncures-devel libaio [root@localhost ~]# yum -y install libaio libaio-devel [root@localhost ~]# yum -y install perl-Data-Dumper [root@localhost ~]# yum -y install net-tools
[root@localhost ~]# yum -y install libaio libaio-devel
[root@localhost ~]# yum -y install perl-Data-Dumper
[root@localhost ~]# yum -y install net-tools
安装bison(这个我也安装了,感觉没什么用处)
bison下载地址:http://www.gnu.org/software/bison/ [root@localhost ~]# tar zxvf bison-2.5.tar.gz [root@localhost ~]# cd bison-2.5 [root@localhost ~]# ./configure [root@localhost ~]# make [root@localhost ~]# make install /www.gnu.org/software/bison/
[root@localhost ~]# tar zxvf bison-2.5.tar.gz
[root@localhost ~]# cd bison-2.5
[root@localhost ~]# ./configure
[root@localhost ~]# make
[root@localhost ~]# make install
解压刚刚下载的Mysql安装包(我是按照它的指示就在root的目录下安装)
[root@localhost ~]#tar -zxvf mysql-5.6.38.tar.gz #tar -zxvf mysql-5.6.38.tar.gz
使用cmake安装,在博文中的目录被它变了,后面又不是一致的。后来我自己修改了才解决了问题。复制下面的内容
cmake \-DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_DATADIR=/usr/local/mysql/data -DSYSCONFDIR=/etc/my.cnf -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_MEMORY_STORAGE_ENGINE=1 -DWITH_READLINE=1 -DMYSQL_UNIX_ADDR=/tmp/mysqld.sock -DMYSQL_TCP_PORT=3306 -DENABLED_LOCAL_INFILE=1 -DWITH_PARTITION_STORAGE_ENGINE=1 -DEXTRA_CHARSETS=all -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci /usr/local/mysql/data -DSYSCONFDIR=/etc/my.cnf -DWITH_MYISAM_STORAGE_ENGINE=1 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_MEMORY_STORAGE_ENGINE=1 -DWITH_READLINE=1 -DMYSQL_UNIX_ADDR=/tmp/mysqld.sock -DMYSQL_TCP_PORT=3306 -DENABLED_LOCAL_INFILE=1 -DWITH_PARTITION_STORAGE_ENGINE=1 -DEXTRA_CHARSETS=all -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci
make 和安装
make && make install make install
配置mysql
检查系统是否已经有mysql用户,如果没有则创建 [root@localhost mysql-5.6.38]# cat /etc/passwd | grep mysql [root@localhost mysql-5.6.38]# cat /etc/group | grep mysql -5.6.38]# cat /etc/passwd | grep mysql
[root@localhost mysql-5.6.38]# cat /etc/group | grep mysql
创建mysql用户(但是不能使用mysql账号登陆系统)
[root@localhost mysql-5.6.32]# groupadd mysql -s /sbin/nologin [root@localhost mysql-5.6.32]# useradd -g mysql mysql .32]# groupadd mysql -s /sbin/nologin
[root@localhost mysql-5.6.32]# useradd -g mysql mysql
修改权限
[root@localhost mysql-5.6.32]# chown -R mysql:mysql /usr/local/mysql .32]# chown -R mysql:mysql /usr/local/mysql
切换到mysql目录
cd /usr/local/mysql local/mysql
设置权限等东西
chown -R mysql:mysql . (#这里最后是有个.的大家要注意# 为了安全安装完成后请修改权限给root用户) scripts/mysql_install_db --user=mysql (先进行这一步再做如下权限的修改) chown -R root:mysql . (将权限设置给root用户,并设置给mysql组, 取消其他用户的读写执行权限,仅留给mysql "rx"读执行权限,其他用户无任何权限) chown -R mysql:mysql ./data (数据库存放目录设置成mysql用户mysql组) chmod -R ug+rwx . (赋予读写执行权限,其他用户权限一律删除仅给mysql用户权限) #这里最后是有个.的大家要注意# 为了安全安装完成后请修改权限给root用户)
scripts/mysql_install_db --user=mysql (先进行这一步再做如下权限的修改)
chown -R root:mysql . (将权限设置给root用户,并设置给mysql组, 取消其他用户的读写执行权限,仅留给mysql "rx"读执行权限,其他用户无任何权限)
chown -R mysql:mysql ./data (数据库存放目录设置成mysql用户mysql组)
chmod -R ug+rwx . (赋予读写执行权限,其他用户权限一律删除仅给mysql用户权限)
将mysql的配置文件拷贝到/etc
cp support-files/my-default.cnf /etc/my.cnf
修改my.cnf
# vi /etc/my.cnf
[mysqld] 下面添加:
user=mysql datadir=/usr/local/mysql/data default-storage-engine=MyISAM /usr/local/mysql/data
default-storage-engine=MyISAM
启动mysql(还是在mysql的目录下进行的)
cp support-files/mysql.server /etc/init.d/mysqlservice mysql start
service mysql start
修改root的密码
chkconfig --add mysql 修改密码 cd 切换到mysql所在目录 # cd /usr/local/mysql ./bin/mysqladmin -u root password
# cd /usr/local/mysql
./bin/mysqladmin -u root password
最后设置新的密码即可!
Mysql导入数据
创建开发时的mysql用户:
GRANT USAGE ON *.* TO 'user01'@'localhost' IDENTIFIED BY '123456' WITH GRANT OPTION;USAGE ON *.* TO 'user01'@'localhost' IDENTIFIED BY '123456' WITH GRANT OPTION;
设置该用户的权限,并且,值得注意的就是,如果想要被开发机器能够连接服务器的mysql,要设置它的访问为“%”
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;PRIVILEGES ON *.* TO 'myuser'@'%' IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
还要把ECS服务器的端口打开,不然是访问不到的。
在开发环境的机器上成功连接Linux服务器的Mysql
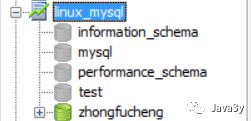
那么导入数据就很简单了。
安装Elasticsearch
tar -xzvf elasticsearch-2.3.3.tar.gz-xzvf elasticsearch-2.3.3.tar.gz
切换到bin目录下执行就行了…
需要这样执行elasticsearch,如果使用的是root用户的话
./elasticsearch -d -Des.insecure.allow.root=true
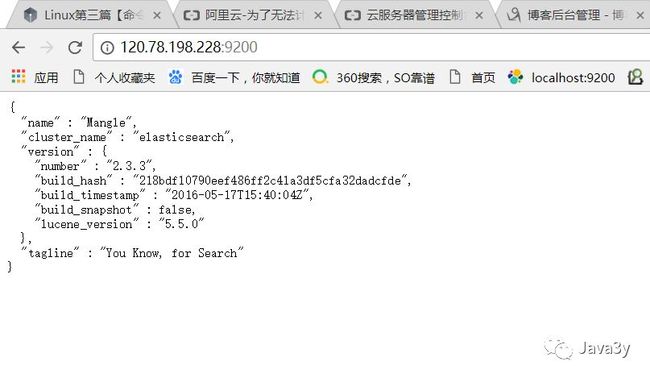
现在使用下面的语句,是可以获取得到信息的
curl -X GET 'http://localhost:9200''http://localhost:9200'
想要通过外网来访问的话,那么就需要修改配置文件了,参考链接http://blog.csdn.net/u012599988/article/details/51767183
还要在ESC服务器上开放端口才能访问:
下载head插件
在下载head插件的时候,需要修改elasticsearch的用户和组,否则它就不让你下载。命令如下
添加用户和组
groupadd elasticsearchuseradd elasticsearch -g elasticsearch -p 123456
useradd elasticsearch -g elasticsearch -p 123456
修改文件夹权限
chown -R elasticsearch:elasticsearch elasticsearch-2.3.3-R elasticsearch:elasticsearch elasticsearch-2.3.3

弄完之后就可以执行命令下载head插件了。
./plugin install mobz/elasticsearch-headhead
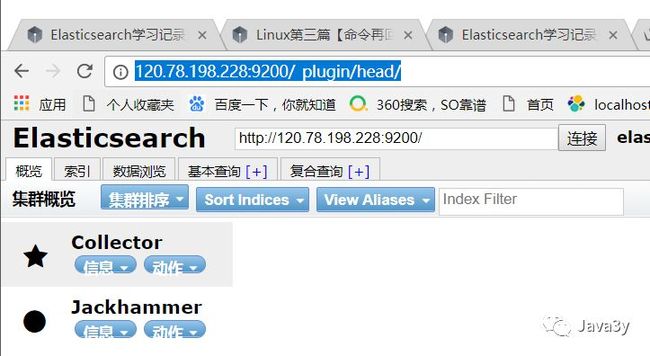
下载完head插件后,不要立马下载shield插件,首先在head插件上创建一个索引!
否则,当下载完shield插件、再访问head插件的话,就无法连接节点了!
这搞了我好长的时间才弄好!!!!!网上也有很多人遇到过这种情况,却没什么好的回答。都在说配置文件上的事情。
我是通过在github中别人提出的issue中找到答案的。参考:https://github.com/mobz/elasticsearch-head/issues/191#issuecomment-132636493
记住了,先在head插件中创建索引、再下载shield插件,否则无法连接head插件!
下载权限shield
我在windows下开发是有下载shiled,为了保持一致,我也下载吧。
输入命令:
plugin install licenseplugin install shield
plugin install shield
下载完就配置一个管理员用户
bin/shield/esusers useradd adminName -r admin貌似就到这里结束了,配置linux环境,如果有就再回来吧。
将项目打包成war包
我使用的是Maven来构建项目的,因此打war包也是非常方便的。
参考链接:
http://blog.csdn.net/yums467/article/details/51660683
部署到Tomcat上
要部署到tomcat上,想要通过域名来访问的话,那么就需要将路径和配置修改一下了。
我们配置一个虚拟主机,将映射目录映射成“/”
还要将8080端口改成是80端口。
修改server.xml 代码如下:
<Context path="" docBase="/opt/apache-tomcat-7.0.82/webapps/zhongfucheng"/>
Host>
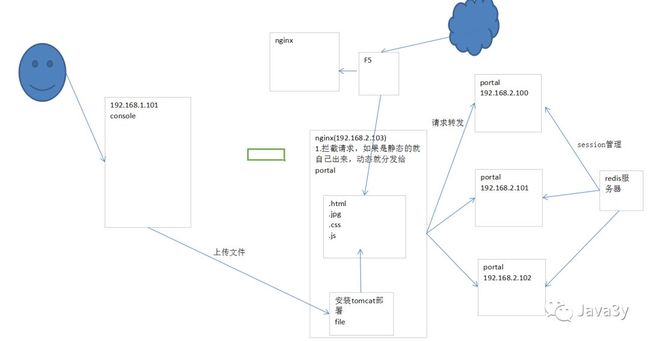
互联网的一般架构图
Hudson用法
为啥需要使用Hudson来进行部署呢?
首先来回顾一下我们普通的部署方式:使用Maven命令来进行打包,获取得到项目的war包,拷贝到Tomcat上运行。
而使用了Hudson有什么好处呢:能够管理我们构建war包时的版本问题,还能够定时构建(貌似没啥用)。
下载Hudson的war包,在tomcat上运行,并且配置其属性,最终通过svn或者git的地址来帮我们构建war包,最终使用脚本来将war包放置Tomcat上。
对于目前我的应用来说,使用起来还是有点复杂的。还不如我直接用SSH连接服务器拷贝到Tomcat上…………
Nginx
F5硬件:也是做负载均衡的
Nginx:作用:
Nginx作为一个Web服务器,将静态文件由自己处理,动态文件转发为其他的服务器进行处理(Tomcat),这样就提高了效率。
Nginx不能处理动态文件的。
Nginx常见的问题:http://bbs.csdn.net/topics/390276707
下载配置Nginx
去官网上下载Nginx,我选择的是稳定版:http://nginx.org/en/download.html
安装Nginx需要的依赖项:
yum -y install gcc pcre pcre-devel zlib zlib-devel openssl openssl-devel
执行configure
要设置安装的路径是啥:make[1]: Leaving directory `/opt/nginx-1.10.3',出现这样的命令可以不用管他
./configure --prefix=/opt/nginx
我安装到了root下了。
执行make&make install
make && make installmake install
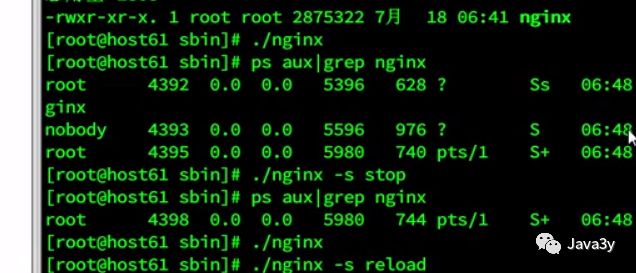
启动报错的情况:
/usr/local/nginx/sbin/nginx 启动nginx报错,信息如下:nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)…..使用ps -ef|grep nginx,并未发现有nginx进程,有可能被其他进程占用,这时可以采用如下方式处理:1. 查看80端口占用netstat -ntpl2. 杀掉占用80端口的进程kill -9 $piduse)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address already in use)
…..
使用ps -ef|grep nginx,并未发现有nginx进程,有可能被其他进程占用,这时可以采用如下方式处理:
1. 查看80端口占用
netstat -ntpl
2. 杀掉占用80端口的进程
kill -9 $pid
最终可以启动:

Nginx简单配置
内容来自于:http://www.jikexueyuan.com/course/1876_1.html?ss=1
还有相关配置详解的博文:http://blog.csdn.net/xmtblog/article/details/42295181
Nginx拦截请求的配置:
# server 表示一个虚拟主机,一台服务器可配置多个虚拟主机 server { # 监听端口 listen 80; # 识别的域名 server_name localhost; # 一个关键设置,与url参数乱码问题有关 charset utf-8; #access_log logs/host.access.log main; #location表达式: #syntax: location [=|~|~*|^~|@] /uri/ { … } #分为两种匹配模式,普通字符串匹配,正则匹配 #无开头引导字符或以=开头表示普通字符串匹配 #以~或~* 开头表示正则匹配,~*表示不区分大小写 #多个location时匹配规则 #总体是先普通后正则原则,只识别URI部分,例如请求为/test/1/abc.do?arg=xxx #1. 先查找是否有=开头的精确匹配,即location = /test/1/abc.do {...} #2. 再查找普通匹配,以 最大前缀 为规则,如有以下两个location # location /test/ {...} # location /test/1/ {...} # 则匹配后一项 #3. 匹配到一个普通格式后,搜索并未结束,而是暂存当前结果,并继续再搜索正则模式 #4. 在所有正则模式location中找到第一个匹配项后,以此匹配项为最终结果 # 所以正则匹配项匹配规则受定义前后顺序影响,但普通匹配不会 #5. 如果未找到正则匹配项,则以3中缓存的结果为最终结果 #6. 如果一个匹配都没有,返回404 #location =/ {...} 与 location / {...} 的差别 #前一个是精确匹配,只响应/请求,所有/xxx类请求不会以前缀匹配形式匹配到它 #而后一个正相反,所有请求必然都是以/开头,所以没有其它匹配结果时一定会执行到它 #location ^~ / {...} ^~意思是非正则,表示匹配到此模式后不再继续正则搜索 #所有如果这样配置,相当于关闭了正则匹配功能 #因为一个请求在普通匹配规则下没得到其它普通匹配结果时,最终匹配到这里 #而这个^~指令又相当于不允许正则,相当于匹配到此为止 location / { root html; index index.html index.htm; # deny all; 拒绝请求,返回403 # allow all; 允许请求 } location /test/ { deny all; } location ~ /test/.+\.jsp$ { proxy_pass http://192.168.1.62:8080; } location ~ \.jsp$ { proxy_pass http://192.168.1.61:8080; } # 定义各类错误页 error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } # @类似于变量定义 # error_page 403 http://www.jikexueyuan.com这种定义不允许,所以利用@实现 error_page 403 @page403; location @page403 { proxy_pass http://http://www.jikexueyuan.com; } }
# 监听端口
listen 80;
# 识别的域名
server_name localhost;
# 一个关键设置,与url参数乱码问题有关
charset utf-8;
#access_log logs/host.access.log main;
#location表达式:
#syntax: location [=|~|~*|^~|@] /uri/ { … }
#分为两种匹配模式,普通字符串匹配,正则匹配
#无开头引导字符或以=开头表示普通字符串匹配
#以~或~* 开头表示正则匹配,~*表示不区分大小写
#多个location时匹配规则
#总体是先普通后正则原则,只识别URI部分,例如请求为/test/1/abc.do?arg=xxx
#1. 先查找是否有=开头的精确匹配,即location = /test/1/abc.do {...}
#2. 再查找普通匹配,以 最大前缀 为规则,如有以下两个location
# location /test/ {...}
# location /test/1/ {...}
# 则匹配后一项
#3. 匹配到一个普通格式后,搜索并未结束,而是暂存当前结果,并继续再搜索正则模式
#4. 在所有正则模式location中找到第一个匹配项后,以此匹配项为最终结果
# 所以正则匹配项匹配规则受定义前后顺序影响,但普通匹配不会
#5. 如果未找到正则匹配项,则以3中缓存的结果为最终结果
#6. 如果一个匹配都没有,返回404
#location =/ {...} 与 location / {...} 的差别
#前一个是精确匹配,只响应/请求,所有/xxx类请求不会以前缀匹配形式匹配到它
#而后一个正相反,所有请求必然都是以/开头,所以没有其它匹配结果时一定会执行到它
#location ^~ / {...} ^~意思是非正则,表示匹配到此模式后不再继续正则搜索
#所有如果这样配置,相当于关闭了正则匹配功能
#因为一个请求在普通匹配规则下没得到其它普通匹配结果时,最终匹配到这里
#而这个^~指令又相当于不允许正则,相当于匹配到此为止
location / {
root html;
index index.html index.htm;
# deny all; 拒绝请求,返回403
# allow all; 允许请求
}
location /test/ {
deny all;
}
location ~ /test/.+\.jsp$ {
proxy_pass http://192.168.1.62:8080;
}
location ~ \.jsp$ {
proxy_pass http://192.168.1.61:8080;
}
# 定义各类错误页
error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# @类似于变量定义
# error_page 403 http://www.jikexueyuan.com这种定义不允许,所以利用@实现
error_page 403 @page403;
location @page403 {
proxy_pass http://http://www.jikexueyuan.com;
}
}
80端口和Tomcat8080端口的问题:
http://www.oschina.net/question/922543_89331
http://blog.csdn.net/juan0728juan/article/details/53019997#
我的简单配置修改如下:
server { listen 80; server_name localhost; charset utf-8; #access_log logs/host.access.log main; #反向代理到8080端口,而页面不显示! proxy_set_header Host $host:$server_port; proxy_set_header X-Real-IP $remote_addr; proxy_set_header REMOTE-HOST $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; #直接匹配网站根,通过域名访问网站首页比较频繁,使用这个会加速处理,官网如是说。 #这里是直接转发给后端应用服务器了,也可以是一个静态首页 # 第一个必选规则 location = / { proxy_pass http://www.zhongfucheng.site:8080/index.html; } # 第二个必选规则是处理静态文件请求,这是nginx作为http服务器的强项 # 有两种配置模式,目录匹配或后缀匹配,任选其一或搭配使用 #后缀匹配 location ~* \.(css|js|html|ico)$ { root /opt/apache-tomcat-7.0.82/webapps/zhongfucheng; } #第三个规则就是通用规则,用来转发动态请求到后端应用服务器 #非静态文件请求就默认是动态请求,自己根据实际把握 #毕竟目前的一些框架的流行,带.php,.jsp后缀的情况很少了 location / { proxy_pass http://www.zhongfucheng.site:8080/; }
server_name localhost;
charset utf-8;
#access_log logs/host.access.log main;
#反向代理到8080端口,而页面不显示!
proxy_set_header Host $host:$server_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header REMOTE-HOST $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
#直接匹配网站根,通过域名访问网站首页比较频繁,使用这个会加速处理,官网如是说。
#这里是直接转发给后端应用服务器了,也可以是一个静态首页
# 第一个必选规则
location = / {
proxy_pass http://www.zhongfucheng.site:8080/index.html;
}
# 第二个必选规则是处理静态文件请求,这是nginx作为http服务器的强项
# 有两种配置模式,目录匹配或后缀匹配,任选其一或搭配使用
#后缀匹配
location ~* \.(css|js|html|ico)$ {
root /opt/apache-tomcat-7.0.82/webapps/zhongfucheng;
}
#第三个规则就是通用规则,用来转发动态请求到后端应用服务器
#非静态文件请求就默认是动态请求,自己根据实际把握
#毕竟目前的一些框架的流行,带.php,.jsp后缀的情况很少了
location / {
proxy_pass http://www.zhongfucheng.site:8080/;
}
Nginx优化配置
# nginx不同于apache服务器,当进行了大量优化设置后会魔术般的明显性能提升效果# nginx在安装完成后,大部分参数就已经是最优化了,我们需要管理的东西并不多#user nobody;#阻塞和非阻塞网络模型:#同步阻塞模型,一请求一进(线)程,当进(线)程增加到一定程度后#更多CPU时间浪费到切换一,性能急剧下降,所以负载率不高#Nginx基于事件的非阻塞多路复用(epoll或kquene)模型#一个进程在短时间内可以响应大量的请求#建议值 <= cpu核心数量,一般高于cpu数量不会带好处,也许还有进程切换开销的负面影响worker_processes 4;#将work process绑定到特定cpu上,避免进程在cpu间切换的开销worker_cpu_affinity 0001 0010 0100 1000 #8内核4进程时的设置方法 worker_cpu_affinity 00000001 00000010 00000100 10000000# 每进程最大可打开文件描述符数量(linux上文件描述符比较广义,网络端口、设备、磁盘文件都是)# 文件描述符用完了,新的连接会被拒绝,产生502类错误# linux最大可打开文件数可通过ulimit -n FILECNT或 /etc/security/limits.conf配置# 理论值 系统最大数量 / 进程数。但进程间工作量并不是平均分配的,所以可以设置的大一些worker_rlimit_nofile 655350 #error_log logs/error.log;#error_log logs/error.log notice;#error_log logs/error.log info;#pid logs/nginx.pid;events { # 并发响应能力的关键配置值 # 每个进程允许的最大同时连接数,work_connectins * worker_processes = maxConnection; # 要注意maxConnections不等同于可响应的用户数量, # 因为一般一个浏览器会同时开两条连接,如果反向代理,nginx到后端服务器的连接也要占用连接数 # 所以,做静态服务器时,一般 maxClient = work_connectins * worker_processes / 2 # 做反向代理服务器时 maxClient = work_connectins * worker_processes / 4 # 这个值理论上越大越好,但最多可承受多少请求与配件和网络相关,也可最大可打开文件,最大可用sockets数量(约64K)有关 worker_connections 500; # 指明使用epoll 或 kquene (*BSD) use epoll # 备注:要达到超高负载下最好的网络响应能力,还有必要优化与网络相关的linux内核参数}http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; # 关闭此项可减少IO开销,但也无法记录访问信息,不利用业务分析,一般运维情况不建议使用 access_log off # 只记录更为严重的错误日志,可减少IO压力 error_log logs/error.log crit; #access_log logs/access.log main; # 启用内核复制模式,应该保持开启达到最快IO效率 sendfile on; # 简单说,启动如下两项配置,会在数据包达到一定大小后再发送数据 # 这样会减少网络通信次数,降低阻塞概率,但也会影响响应及时性 # 比较适合于文件下载这类的大数据包通信场景 #tcp_nopush on; 在 #tcp_nodelay on|off on禁用Nagle算法 #keepalive_timeout 0; # HTTP1.1支持持久连接alive # 降低每个连接的alive时间可在一定程度上提高可响应连接数量,所以一般可适当降低此值 keepalive_timeout 30s; # 启动内容压缩,有效降低网络流量 gzip on; # 过短的内容压缩效果不佳,压缩过程还会浪费系统资源 gzip_min_length 1000; # 可选值1~9,压缩级别越高压缩率越高,但对系统性能要求越高 gzip_comp_level 4; # 压缩的内容类别 gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript; # 静态文件缓存 # 最大缓存数量,文件未使用存活期 open_file_cache max=655350 inactive=20s; # 验证缓存有效期时间间隔 open_file_cache_valid 30s; # 有效期内文件最少使用次数 open_file_cache_min_uses 2; server { listen 80; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # #location ~ \.php$ { # proxy_pass http://127.0.0.1; #} # pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000 # #location ~ \.php$ { # root html; # fastcgi_pass 127.0.0.1:9000; # fastcgi_index index.php; # fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; # include fastcgi_params; #} # deny access to .htaccess files, if Apache's document root # concurs with nginx's one # #location ~ /\.ht { # deny all; #} } # another virtual host using mix of IP-, name-, and port-based configuration # #server { # listen 8000; # listen somename:8080; # server_name somename alias another.alias; # location / { # root html; # index index.html index.htm; # } #} # HTTPS server # #server { # listen 443 ssl; # server_name localhost; # ssl_certificate cert.pem; # ssl_certificate_key cert.key; # ssl_session_cache shared:SSL:1m; # ssl_session_timeout 5m; # ssl_ciphers HIGH:!aNULL:!MD5; # ssl_prefer_server_ciphers on; # location / { # root html; # index index.html index.htm; # } #} include /usr/local/nginx/conf/vhosts/*.conf;}
#user nobody;
#阻塞和非阻塞网络模型:
#同步阻塞模型,一请求一进(线)程,当进(线)程增加到一定程度后
#更多CPU时间浪费到切换一,性能急剧下降,所以负载率不高
#Nginx基于事件的非阻塞多路复用(epoll或kquene)模型
#一个进程在短时间内可以响应大量的请求
#建议值 <= cpu核心数量,一般高于cpu数量不会带好处,也许还有进程切换开销的负面影响
worker_processes 4;
#将work process绑定到特定cpu上,避免进程在cpu间切换的开销
worker_cpu_affinity 0001 0010 0100 1000
#8内核4进程时的设置方法 worker_cpu_affinity 00000001 00000010 00000100 10000000
# 每进程最大可打开文件描述符数量(linux上文件描述符比较广义,网络端口、设备、磁盘文件都是)
# 文件描述符用完了,新的连接会被拒绝,产生502类错误
# linux最大可打开文件数可通过ulimit -n FILECNT或 /etc/security/limits.conf配置
# 理论值 系统最大数量 / 进程数。但进程间工作量并不是平均分配的,所以可以设置的大一些
worker_rlimit_nofile 655350
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
# 并发响应能力的关键配置值
# 每个进程允许的最大同时连接数,work_connectins * worker_processes = maxConnection;
# 要注意maxConnections不等同于可响应的用户数量,
# 因为一般一个浏览器会同时开两条连接,如果反向代理,nginx到后端服务器的连接也要占用连接数
# 所以,做静态服务器时,一般 maxClient = work_connectins * worker_processes / 2
# 做反向代理服务器时 maxClient = work_connectins * worker_processes / 4
# 这个值理论上越大越好,但最多可承受多少请求与配件和网络相关,也可最大可打开文件,最大可用sockets数量(约64K)有关
worker_connections 500;
# 指明使用epoll 或 kquene (*BSD)
use epoll
# 备注:要达到超高负载下最好的网络响应能力,还有必要优化与网络相关的linux内核参数
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
# 关闭此项可减少IO开销,但也无法记录访问信息,不利用业务分析,一般运维情况不建议使用
access_log off
# 只记录更为严重的错误日志,可减少IO压力
error_log logs/error.log crit;
#access_log logs/access.log main;
# 启用内核复制模式,应该保持开启达到最快IO效率
sendfile on;
# 简单说,启动如下两项配置,会在数据包达到一定大小后再发送数据
# 这样会减少网络通信次数,降低阻塞概率,但也会影响响应及时性
# 比较适合于文件下载这类的大数据包通信场景
#tcp_nopush on; 在
#tcp_nodelay on|off on禁用Nagle算法
#keepalive_timeout 0;
# HTTP1.1支持持久连接alive
# 降低每个连接的alive时间可在一定程度上提高可响应连接数量,所以一般可适当降低此值
keepalive_timeout 30s;
# 启动内容压缩,有效降低网络流量
gzip on;
# 过短的内容压缩效果不佳,压缩过程还会浪费系统资源
gzip_min_length 1000;
# 可选值1~9,压缩级别越高压缩率越高,但对系统性能要求越高
gzip_comp_level 4;
# 压缩的内容类别
gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript;
# 静态文件缓存
# 最大缓存数量,文件未使用存活期
open_file_cache max=655350 inactive=20s;
# 验证缓存有效期时间间隔
open_file_cache_valid 30s;
# 有效期内文件最少使用次数
open_file_cache_min_uses 2;
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# another virtual host using mix of IP-, name-, and port-based configuration
#
#server {
# listen 8000;
# listen somename:8080;
# server_name somename alias another.alias;
# location / {
# root html;
# index index.html index.htm;
# }
#}
# HTTPS server
#
#server {
# listen 443 ssl;
# server_name localhost;
# ssl_certificate cert.pem;
# ssl_certificate_key cert.key;
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 5m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
# location / {
# root html;
# index index.html index.htm;
# }
#}
include /usr/local/nginx/conf/vhosts/*.conf;
}
此部分我暂时没有进行修改!以后用到再来看把!
Tomcat优化

<Server port="8005" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.startup.VersionLoggerListener" />
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<Listener className="org.apache.catalina.core.JasperListener" />
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
<GlobalNamingResources>
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
GlobalNamingResources>
<Service name="Catalina">
<Connector port="8080" protocol="org.apache.coyote.http11.Http11NioProtocol"
connectionTimeout="20000"
redirectPort="8443
maxThreads=“500”
minSpareThreads=“100”
maxSpareThreads=“200”
acceptCount="200"
enableLookups="false"
/>
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
<Engine name="Catalina" defaultHost="localhost">
<Realm className="org.apache.catalina.realm.LockOutRealm">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
Realm>
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log." suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
Host>
Engine>
Service>
Server>
这部分也没有用到,等需要用到的时候再回来!
配置成功
在配置完之后,我总有一个疑问,Nginx是否已经帮我们处理了静态文件???
于是我在网上找相关的问题,可没有相关的资料。。
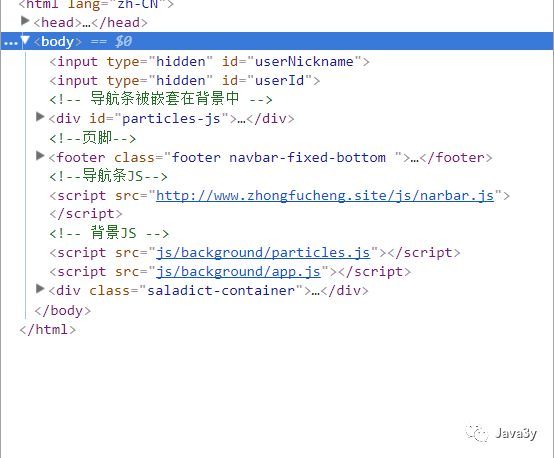
最后我就在想:Tomcat的端口我配置的是8080,静态资源在http://zhongfucheng.site:8080,在tomcat下肯定是可以获取得到的。
如果静态资源在http://zhongfucheng.site就能够获取得到了,那么静态资源就已经被Nginx处理了!
最后在网页上看源码果然是配置成功了!
如果文章有错的地方欢迎指正,大家互相交流。习惯在微信看技术文章,想要获取更多的Java资源的同学,可以关注微信公众号:Java3y