注意力机制(attention mechanism)
1、注意力
灵长类动物的视觉系统接收了大量的感官输入,这些感官输入远远超出了大脑能够完全处理的能力。然而,并非所有刺激的影响都是同等的。意识的汇聚和专注使灵长类动物能够在复杂的视觉环境中将注意力引向感兴趣的物体,例如猎物和天敌。只关注一小部分信息的能力对进化更加有意义,使人类以生存和成功。
2、注意力经济
自经济学研究稀缺资源分配以来,人们正处在“注意力经济”时代,即人类的注意力(大量人群的注意力)被视为可以交换的、有限的、有价值的且稀缺的商品。
3、注意力的稀缺性
注意力是稀缺的,而环境中的干扰注意力的信息却并不少。
读者的注意力具有稀缺性,是一种稀缺资源,读者正在阅读这篇文章(而忽略了其他文章),因此读者的注意力是用机会成本(与金钱类似)来支付的。
4、注意力的管理分配能力
整个人类历史中,这种只将注意力引向感兴趣的一小部分信息的能力,使人类的大脑能够更明智地分配资源来生存、成长和社交,例如发现天敌、寻找食物和伴侣。
5、生物学中的注意力提示
注意力如何应用于视觉世界中?需要从双组件(two-component)框架讲起(该框架由威廉詹姆斯在1890年代提出)。在这个框架中,受试者基于非自主性提示和自主性提示有选择性地引导注意力的焦点。
6、注意力机制的框架
自主性的与非自主性的注意力提示解释了人类的注意力的方式,下面来看看如何通过这两种注意力提示,用神经网络来设计注意力机制的框架。(设计的灵感和依据来源,实证科学)
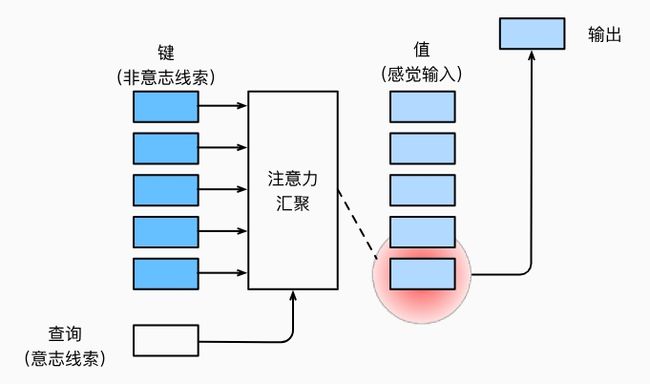
7、注意力汇聚
注意力机制框架下的注意力机制的主要组件:查询(自主性提示)和键(非自主性提示)之间的交互形成了注意力汇聚:注意力汇聚有选择性地汇聚了值(感官输入)以生成最终的输出。
如下图所示,注意力机制通过注意力汇聚将查询(自主性提示)和键(非自主性提示)结合在一起,实现对值(感官输入,包含更广)的选择倾向,形成注意力输出。
8、注意力模型
这一在这个框架下的模型,称为主要的讨论内容。由简单到复杂,介绍内容包括Nadaraya-Waston核回归模型(1964),注意力评分函数(具体介绍两个典型评分函数)、Bahdanau注意力(没有严格单向对齐限制的可微注意力模型)、多头注意力、自注意力、位置编码、Transformer。
8.1 注意力汇聚
介绍注意力汇聚的更多细节,以便宏观上了解注意力机制在实践中的运作方式。
具体以1964年提出的Nadaraya-Waston核回归模型为例,这是一个简单但完整的例子,可以用于演示具有注意力机制的机器学习。
8.1.1 平均汇聚
![]()
8.1.2 非参数注意力汇聚
![]()
![]()
8.1.3 带参数注意力汇聚
![]()
8.2 注意力评分函数
注意力权重,即键对应的值的概率分布。从注意力的角度来看,分配给每个值![]() 的注意力权重取决于一个函数
的注意力权重取决于一个函数![]() ,这个函数以值所对应的键
,这个函数以值所对应的键![]() 和查询
和查询![]() 作为输入。
作为输入。
![]()

图 计算注意力汇聚的输出为值的加权和
其中,查询![]() 和键
和键![]() 的注意力权重
的注意力权重![]() ,该权重是一个标量,是通过将注意力评分函数
,该权重是一个标量,是通过将注意力评分函数 将两个向量映射成标量
将两个向量映射成标量![]() ,再经过softmax运算得到的:
,再经过softmax运算得到的:
。
加性注意力:
![]()
缩放点积注意力:
![]()
8.3 Bahdanau注意力
将上下文变量视为注意力集中的输出。
![]()
8.4 多头注意力
与其只使用单独一个注意力汇聚,我们可以用独立学习到的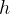 组不同的线性投影来变换查询、键和值。
组不同的线性投影来变换查询、键和值。
![]()

8.5 自注意力
每个查询都会关注所有的键-值对,并生成一个注意力输出。由于查询、键、值来自同一组输入,因此被称为自注意力(self-attention),也被称为内部注意力(intra-attention)。
给定一个词元组成的输入序列![]() ,其中任意
,其中任意![]() 。该序列的自注意输出为一个长度相同的序列
。该序列的自注意输出为一个长度相同的序列![]() ,其中
,其中
![]() 。
。
8.6 位置编码
在处理词元序列时,循环神经网络是逐个重复地处理词元的,而自注意力则因为并行计算而放弃了顺序操作。
为了使用序列的顺序信息,通过在输入表示中添加位置编码来注入绝对的或相对的位置信息。编码(Encoding)通常是指将原始数据或信息转化为计算机可处理的格式的过程。位置编码可以通过学习得到,也可以直接固定。
介绍一个具体编码方式:基于正弦函数和余弦函数的固定位置编码。
基于正弦函数和余弦函数的固定位置编码是Transformer模型中用于捕获输入序列中词序信息的一种重要方法。在原始Transformer论文《Attention is All You Need》中提出的方案,位置编码(Positional Encoding)为序列中的每个位置生成一个与词嵌入维度相同的向量,并将这个向量直接加到该位置对应的词嵌入上。
假设输入表示![]() 包含一个序列中
包含一个序列中 个词元的
个词元的 维嵌入表示。位置编码使用相同形状的位置嵌入矩阵
维嵌入表示。位置编码使用相同形状的位置嵌入矩阵![]() ,输出
,输出![]() 。矩阵
。矩阵![]() 第
第 行、第
行、第![]() 列和第
列和第![]() 列上的元素分别为:
列上的元素分别为:
![]()
![]() .
.
8.6 Transformer
与CNN和RNN相比,自注意力同时具有并行计算和最短最大路径长度这两个优势。因此,使用自注意力来设计深度架构是很有吸引力的。Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层。
Transformer最初是应用于在文本数据上的序列到序列学习,现在已经推广到各种现代的深度学习中,例如语言、视觉、语音和强化学习领域。
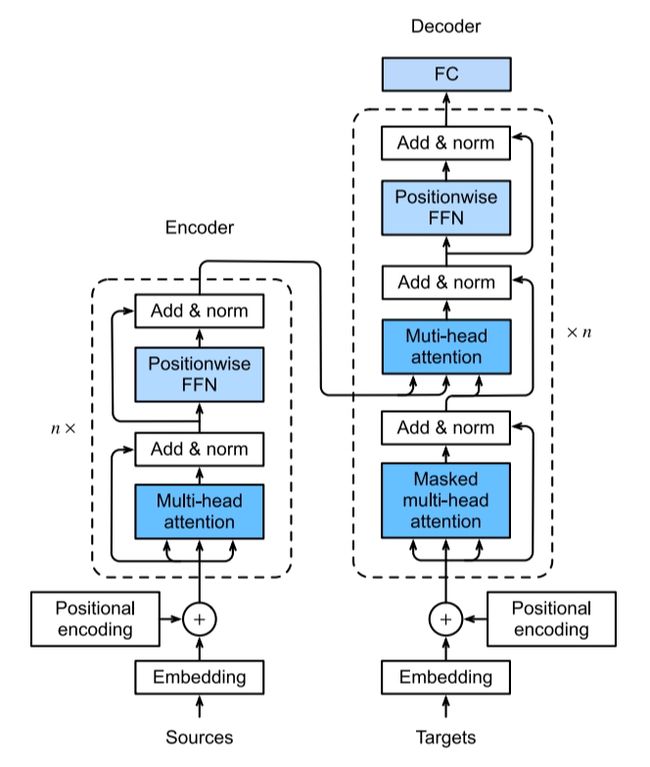
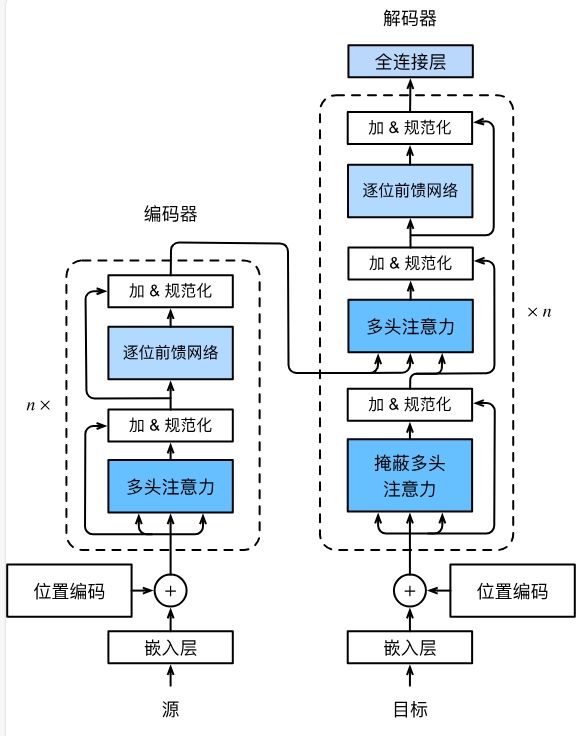
图 transformer架构
上面两幅展示了Transformer的中文架构和英文架构,英文架构类的模块名称和具体代码一一对应,方便大家对照代码、理解和使用。从宏观角度来看,Transformer的编码器和解码器都是基于自注意力的模块叠加而成的。其中,编码器是由多个相同的层叠加而成的,每个层有两个子层,第一个子层是多头自注意力(multi-head self-attention),第二个子层是基于位置的前馈网络(pointwise feed-forward network)。解码器也是由多个相同的层叠加而成,除了编码器中描述的两个子层,解码器还有第三个子层,称为编码器-解码器注意力层(encoder-decoder attention)。
9、注意力模型分析
各个模型的原理、具体实现和效果分析:(待续)