python股票分析挖掘预测利器Numpy,Pandas,Matplotlib库知识点(2)
本人股市多年的老韭菜了,各种股票分析书籍,技术指标书籍阅历无数,萌发想法,何不自己开发个股票预测分析软件,选择python因为够强大,它提供了很多高效便捷的数据分析工具包,
其中数据分析中常见的3大利器---Numpy,Pandas,Matplotlib库。
俗话说的好,工欲善其事,必先利其器,我们要做好项目,必先打好基础,那我们一起学习一下这三个数据分析库,上一章简单的讲了Numpy的基础,这一章我们讲Pandas
(二)Pandas库基础
pandas库是基于Numpy库的一个开源python库,主要运用数据快速分析,清洗和准备等工作,某种程度来说可以把Pandas当成python版的Excel,与Numpy相比,Pandas库更擅长处理二维数组,Pandas库有处理一维数据结构的Series和二维数组的DataFrame.
一维数据结构的Series用法
import pandas as pd
s = pd.Series(['李四', '王二', '张三'])
print(s)二维数组的DataFrame.的用法
# 二维数据表格DataFrame的创建**
import pandas as pd
a = pd.DataFrame([[1, 2], [3, 4], [5, 6]])
print(a)(1)Series入门
Series(系列、数列、序列)是一个带有标签的一维数组,是由一组数据以及与这组数据有关的标签(索引)组成,Series对象可以存储整数、浮点数、字符串、Python对象等多种数据类型的数据,是pandas最基础的数据结构。
(1)Series对象创建
#series对象的创建
import pandas as pd
data=[12,22,25,118]
index=['章三','里斯','王儿','刘武']
s=pd.Series(data=data,index=index)
print(s)
(2)Series索引创建
#位置索引
data=[13.14,21.34,5.08,10.18]
s=pd.Series(data=data)
print(s)
print(s[2])#s[2]---获取位置索引为2的值
(3)获取Series的索引和值
data=[13.14,21.34,5.08,10.18]
index=['Zhang','liu','wang','haima']
s=pd.Series(data=data,index=index)
print(s.index)
print(list(s.index))#通常将索引转换成列表输出
print(s.values)
(2)DataFrame入门
DataFrame是一个表格型的数据结构。每列都可以是不同的数据类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,这两种索引在DataFrame的实现上,本质上是一样的。但在使用的时候,往往是将列索引作为区分不同数据的标签。DataFrame的数据结构与SQL数据表或者Excel工作表的结构非常类似,可以很方便地互相转换。
下面先来创建一个DataFrame,一种常用的方式是使用字典,这个字典是由等长的list或者ndarray组成的,示例代码如下:
data={'A':['x','y','z'],'B':[1000,2000,3000],'C':[10,20,30]}
df=pd.DataFrame(data,index=['a','b','c'])
print(df)显示结果: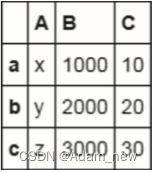
从上图我们可以看到,DataFrame主要由如下三个部分组成。
- 数据,位于表格正中间的9个数据就是DataFrame的数据部分。
- 索引,最左边的a、b、c是索引,代表每一行数据的标识。这里的索引是显式指定的。如果没有指定,会自动生成从0开始的数字索引。
- 列标签,表头的A、B、C就是标签部分,代表了每一列的名称。
(1)DataFrame常用函数及参数
data:ndarray/字典/类似列表 | DataFrame数据;数据类型可以是ndarray、嵌套列表、字典等
index:索引/类似列表 | 使用的索引;默认值为range(n)
columns:索引/类似列表 | 使用的列标签;默认值为range(n)
dtype:dtype | 使用(强制)的数据类型;否则通过推导得出;默认值为None
copy:布尔值 | 从输入复制数据;默认值为False
属性 描述
describe() 查看每列的统计汇总信息,DataFrame类型
count( ) 返回每一列的非空值的个数
sum() 返回每一列的和,无法计算返回空值
max() 返回每一列的最大值
min() 返回每一列的最小值
(2)通过列表创建 DataFrame
import pandas as pd
a = pd.DataFrame([[1, 2], [3, 4], [5, 6]])
print(a)(3)通过字典 创建 DataFrame
# (2) 通过字典创建DataFrame
b = pd.DataFrame({'a': [1, 3, 5], 'b': [2, 4, 6]}, index=['x', 'y', 'z'])
print(b)
c = pd.DataFrame.from_dict({'a': [1, 3, 5], 'b': [2, 4, 6]}, orient="index")
print(c)(4)通过二维数组 创建 DataFrame
# (3) 通过二维数组创建
import numpy as np
c=np.arange(12).reshape(3,4)
print(c)
import numpy as np
d = pd.DataFrame(np.arange(12).reshape(3,4), index=[1, 2, 3], columns=['A', 'B', 'C', 'D'])
print(d)(3)文件的读取和写入
pandas库可以从多种数据中读取数据,也可以将获得的数据写入这些文件
(1)文件读取
一下代码一个简单的excel读取文件
# **2.2.2 Excel等文件的读取和写入**
import pandas as pd
data = pd.read_excel('data.xlsx') # data为DataFrame结构
data.head() # 通过head()可以查看前5行数据,如果写成head(10)则可以查看前10行数据
# 其中read_excel还可以设定参数,使用方式如下:
data = pd.read_excel('data.xlsx', sheet_name=0, encoding='utf-8')
data = pd.read_csv('data.csv')
data.head()
# read_csv也可以指定参数,使用方式如下:
data = pd.read_csv('data.csv', delimiter=',', encoding='utf-8')(2)文件的写入
(2) 文件写入
data = pd.DataFrame([[1, 2], [3, 4], [5, 6]], columns=['A列','B列'])
data.to_excel('data_new.xlsx')
data.to_excel('data_new.xlsx', sheet_name=0, encoding='utf-8', index=False, columns=['A列','B列'])
data.to_csv('data_new.csv')
data.to_csv('演示.csv', index=False, encoding="utf_8_sig")
# **补充知识点:文件相对路径与绝对路径**
data.to_excel('E:\\大数据分析\\data.xlsx') # 绝对路径推荐写法1,此时E盘要有一个名为“大数据分析”的文件夹
data.to_excel(r'E:\大数据分析\data.xlsx') # 绝对路径推荐写法2,此时E盘要有一个名为“大数据分析”的文件夹
(3)数据的获取和筛选
# **2.2.3 数据读取与筛选**
import pandas as pd
data = pd.DataFrame([[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['r1', 'r2', 'r3'], columns=['c1', 'c2', 'c3'])
print(data)
# 1.按照行列进行数据筛选
# (1) 按照列来选取数据
a = data['c1']
print(a)
b = data[['c1']]
print(b)
c = data[['c1', 'c3']]
print(c)
# (2) 按照行来选取数据
a = data[1:3]
print(a)
b = data.iloc[1:3]
print(b)
c = data.iloc[-1]
print(c)
d = data.loc[['r2', 'r3']]
print(d)
e = data.head()
print(e)
# (3) 按照区块来选取
a = data[['c1', 'c3']][0:2] # 也可写成data[0:2][['c1', 'c3']]
print(a)
b = data.iloc[0:2][['c1', 'c3']]
print(b)
c = data.iloc[0]['c3']
print(c)
d = data.loc[['r1', 'r2'], ['c1', 'c3']]
e = data.iloc[0:2, [0, 2]]
print(d)
print(e)
f = data.ix[0:2, ['c1', 'c3']]
print(f)
Pandas库还提供了很多高级的功能,比如数据表拼接,如果详细的介绍Pandas的各项功能和用法,需要一本书的厚度,在这只是介绍简单的用法和入门,谢谢!