【数据结构-单链表】(C语言版本)
今天分享的是数据结构有关单链表的操作和实践(图解法,图变化更利于理解)
记录宗旨: 眼(脑)过千遍,不如手过一遍。
我们都知道单链表是一种常见的链表数据结构,由一系列节点组成。每个节点包含两部分:数据域和指针域。
- 数据域:用于存储节点中的数据。
- 指针语:用于指向下一个节点的地址。
每个节点的指针域指向链表中的下一个节点,最后一个节点的指针域指向NULL,表示链表的结束。
链表的头节点是链表中的第一个节点。通过头节点,可以访问整个链表。
相比于数组,链表具有动态性,可以根据需要动态地插入和删除节点,而无需预先分配固定大小的内存空间。
Node1 Node2 Node3 Node4
+------+ +------+ +------+ +------+
| data | | data | | data | | data |
+------+ +------+ +------+ +------+
| next |-->| next |-->| next |-->| NULL |
+------+ +------+ +------+ +------+
在上面的示例中,每个节点包含一个数据域(data)和一个指针域(next)。节点1、节点2、节点3和节点4依次连接,形成一个链表。节点4的指针域指向NULL,表示链表的结束。
通过遍历链表,可以访问链表中的所有节点,并执行相应的操作。例如,可以在链表中插入新节点、删除节点或查找特定节点等。
因此以下主要进行单链表的操作进行分析和实践
单链表的结构

其中head为头节点,head -> length: 链表的长度, head -> next:指向首元节点(储存首元节点的地址)。一次前一个节点指向后一个节点,尾节点最后一个NULL。
头文件
#include 声明链表结构体
通过typedef声明结构体, 并给int类型起别名,便于数据类型变更的维护。
typedef int ElementType;
typedef struct s_node
{
// 声明节点数据域
ElementType data;
// 声明下一个节点的指针域
struct s_node* next;
} ListNode;
单链表的创建–头插法创建
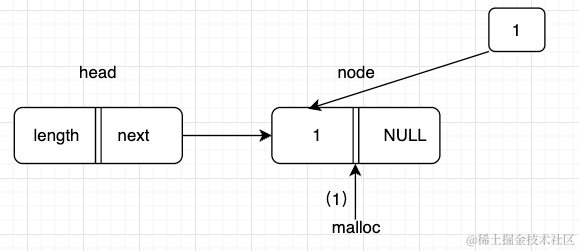
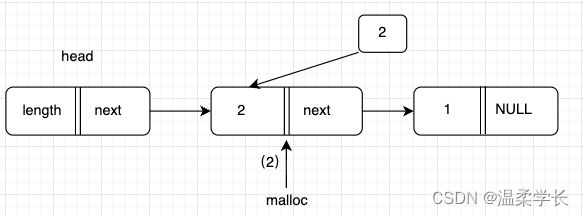
目前有一条数据,{1,2,3,4,5}。 然后依次添加到链表中,如图:
...
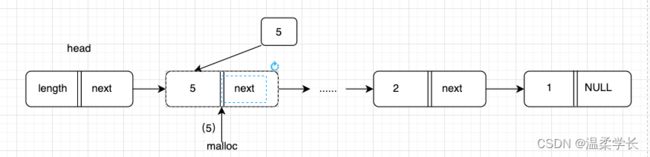
我们可以看到上面的头插法就是将数据每一个新的插入在头节点head的后面,依次往复。
// 头插法创建链表, arr: 需要插入的数据, size: 需要创建链表的长度
ListNode* topInsertList(int arr[], int size) {
ListNode* head = (ListNode*)malloc(sizeof(ListNode));
head -> next = NULL;
ListNode* node;
for (int i = 0; i < size; i++)
{
// 为每次新增数据节点创建空间
node = (ListNode*)malloc(sizeof(ListNode));
// 将数据内容分别给到新创建的空间
node -> data = arr[i];
// 当前数据的下一个节点为插入前头节点的下一个节点地址
node -> next = head -> next;
// 将头节点重新赋值为当前节点
head -> next = node;
}
// 返回头节点
return head;
}
输出: 5,4,3,2,1, 可以看出来和输入数据相反。
头插法只需要操作两个节点,当前元素指向头节点的指向,并修改头节点指向当前节点。
单链表的创建–尾插法创建
目前有一条数据,{1,2,3,4,5}。 然后依次添加到链表中,如图:



尾插法更加直接,相当于在一条线的尾巴上进行追加链接数据。
/*
创建一个新的链表
arr: 创建链表的数据
size: 创建的大小
尾插法
思想: 首先将新插入的节点设置成一个完整的链表节点格式,然后将头节点复制给一个临时节点,每次将临时节点都指向下一个新插入节点,保证节点的移动和链接
*/;
ListNode* rInsertList(int arr[], int size) {
ListNode *head = (ListNode*)malloc(sizeof(ListNode));
// node为新插入的节点。 middle为链表最后节点,当第一次创建链表时指向头节点
ListNode *node, *middle;
// head -> next = NULL;
// middle临时当作头节点
middle = head;
for (int i = 0; i < size; i++)
{
node = (ListNode*)malloc(sizeof(ListNode));
node -> data = arr[i];
node -> next = NULL;
middle -> next = node;
middle = node;
}
middle -> next = NULL;
return head;
}
输出: 1,2,3,4,5。 输入和输出一样。
尾插法因为需要获取到当前最后一个节点,故需要设置三个节点:头节点,当前节点,动态变化的尾节点。
遍历链表
可以将上面新创建的链表打印输出:
//打印链表
void disList(ListNode *list) {
//(1)、当遍历链表没有head头节点的时候使用第一条:
ListNode *node = list; // ndoe指向首节点
// (2)、当遍历链表由头节点的时候选择第二条
//ListNode *node = list -> next; // 头节点指向首元节点
while(node != NULL) {
printf("%d====", node -> data);
node = node -> next;
}
printf("\n");
}
按照上面方式创建的链表,可以使用这个方法打印输出链表的内容。
获取链表长度
int isLength(ListNode *list) {
//(1)、当遍历链表没有head头节点的时候使用第一条:
ListNode *node = list;
// (2)、当遍历链表由头节点的时候选择第二条
//ListNode *node = list -> next; // 头节点指向首元节点
// p = p-> next;
int n = 0;
while(node != NULL) {
n++;
node = node->next;
};
printf("长度:%d\n", n);
return n;
}
判断是否为空
// 检查线性链表是否为空
int isEmpty(ListNode* list) {
return list == NULL;
}
删除链表中指定元素
删除链表中的指定元素,首先需要查找当前元素所在链表中的位置,然后将该节点赋值给一个临时指针,方便修改前后指针的指向:

// 删除指定元素, 传入的时候,list传入需要传入链表的地址
bool deleteNode(ListNode **list, ElementType key) {
// 声明临时指针
ListNode *temp;
// 判断是否为头节点
if ((*list) -> data == key) {
// 将头节点复制给临时指针
temp = *list;
// 并将头节点的指针指向后一个节点
*list = (*list) -> next;
// 删除头节点空间
free(temp);
return true;
} else {
// 将头节点复制给临时
ListNode *pre = *list;
while(pre -> next != NULL) {
if (pre -> next -> data == key) {
// 将temp备份为待删除节点
temp = pre -> next;
pre -> next = pre -> next -> next;
free(temp);
return true;
} else {
pre = pre -> next;
}
}
return false;
}
}
例如输入:{1,2,3,4,5}, 删除2,结果变成{1,3,4,5}。
可以清晰看到删除操作,在声明指针的时候,声明了三个指针,并且传入的链表头节点采用的双指针,这是为什么呢?
首先声明的临时指针用于存放当前需要删除的节点指针,如果直接删除当前节点,后续节点还未将数据节点指向头节点或者前一个节点,这会导致整个链表后续的节点丢失。当前链表就断开了,这是不允许的。 因此增加临时指针,用于过渡。
反转一个链表
- 把当前节点的next存起来,next = curr -> next
- 把当前节点的next指向前一个节点, curr -> next = prev
- 前指针后移prev = curr
- 当前指针后移curr = next
ListNode* reversList(ListNode *list) {
ListNode *curr = list -> next;
ListNode *prev = NULL;
while(curr != NULL) {
ListNode * next = (ListNode*)malloc(sizeof(ListNode));
next = curr -> next;
curr -> next = prev;
prev = curr;
curr = next;
}
return prev; // 返回反转后的首元节点
}
反转链表的思想就是:指定一个指针,每次给当前指针的下一个值赋值给一个临时变量,防止链表断开从而找不到后续节点;并将当前节点的的下一个指针指向赋值为新设置的节点,第一次新设置的节点为NULL,后续并将操作完的当前节点赋值给设置的节点,保证下次节点的移动从而遍历链表中的数据,依次反转元素。