数据集解析 001:MNIST数据集与IDX文件(附带IDX文件提取代码Python版)
写在最前
在开始这个专题第一篇文章之前,请先允许博主先跟大家聊聊这个专题咱们讲什么具体内容。相信凡是做过与深度学习或者神经网络相关工作的同学对 数据集 这个概念并不陌生,在网络训练过程中我们采用的各种数据集都有各自的格式。不论是直接打包的图片集,还是例如MNIST这种直接保存为二进制文件格式的数据集,本质都是图像数据在存储介质中的一种存储方式。这个专题我们就来深度的剖析一下各个数据集的细节文件组成与编码规则等具体问题。
目录
第一章: MNIST数据集内容概览
第二章: 图像集与标签的对应关系
2.1 数据集与标签
2.2 MNIST数据集中的对应关系
第三章: MNIST数据集中的IDX文件
3.1 IDX文件的数据格式
3.1.1 文件内地址构成
3.1.2 文件内数据构成
3.1.3 官方说明书的使用
3.2 IDX文件打开与读取(Python版本)
3.2.1 思路剖析
3.2.2 模块拆解-步骤1
3.2.3 模块拆解-步骤2
3.2.4 模块拆解-步骤3
第四章: 完整代码
1. MNIST数据集内容概览
我们今天介绍的主角是MNIST数据集,他的文件构成格式是IDX文件。很多小伙伴在刚刚初学深度学习基础知识的时候接触到的数据集应该都是MNIST,他是LeNet-5网络实现手写体识别功能的标准训练集。这里博主给出该数据集的下载地址:MNIST数据集传送门
当我们将数据集解压后会得到这样的四个文件:

这四个文件内容分别如下:
- t10k-images-idx3-ubyte(第一行):数量为10000的测试图片集,每张图片28*28像素,单通道灰度图;
- t10k-labels-idx1-ubyte(第二行):数量为10000的测试图像标签集,对应每张测试图像;
- train-images-idx3-ubyte(第三行):数量为60000的训练图片集,每张图片28*28像素,单通道灰度图;
- train-labels-idx1-ubyte(第四行):数量为60000的训练图像标签集,对应每张训练图像;
以上所有的图片内容均是阿拉伯数字0-9的手写体图片。
2. 图像集与标签的对应关系
2.1 数据集与标签
首先 这里给大家简单解释一下 什么是数据集,什么是标签:
在训练卷积神经网络的时候(以LeNet-5为例),我们需要告诉网络每一个训练的数据究竟是哪个数字。举个例子来说:我们小时候看葫芦娃动画片知道一共有7个兄弟,我们怎么分辨这七个兄弟呢?
可能有的同学靠各个葫芦娃穿的 裤衩颜色 不同来分辨:
- 老大:粉裤衩;
- 老二:橙裤衩;
- 老三:黄裤衩;
- (博主记不住了…)
也有可能有的同学靠各个葫芦娃 能力不同 来分别来分辨:
- 老大:力大无穷,还能变大;
- 老二:千里眼,顺风耳;
- 老三:钢筋铁骨,铜墙铁壁;
- (还有很多…)
总而言之,我们会对每个葫芦娃都贴上一个 “标签”, 这个标签帮助我们确定具体是哪7个兄弟中的一个。MNIST数据集也是同样道理,他会给图像数据集中每个0-9的手写体数字图片一个标签,告诉计算机当前这张图片上写的数字究竟是0-9中的哪一个。
2.2 MNIST数据集中的对应关系
由于MNIST数据集将 图片集 和 注释标签 分成了两部分文件分别独立存储,所以弄清楚如何将这两个文件中的信息关联起来至关重要。总结来说: MNIST数据集中训练集和测试集与其相应的标签集均是一对一的对应关系,即 匹配的文件中对应项目数据组成一组。
比如说: 训练图片集中的第一张图片和训练标签集中的第一个标签就是对应项目,测试图片集中的第五张图片和测试标签集中的第五个标签也为对应项目。
上述 四个文件 共会组成 两套 绑定数据:一套由 训练图片集+训练集标签 (这两个文件即为匹配文件)组成,另一套由 测试图片集+测试集标签 (这两个文件也为匹配文件)组成。
3. MNIST数据集中的IDX文件
第1章节给出的图片中,四个文件的命名种均有 idx。这些文件我们不能用通常的图像查看软件打开,他们的本质我们可以理解为采用特殊编码的二进制文件。emmm…二进制文件,这是啥东西?? 咱们先来个直观的感受,下面的图片是将 train-labels-idx1-ubyte 文件用十六进制格式打开后的样子(只截取了一部分展示):
注意:上面这段话中二进制文件是说该文件的性质,而十六进制格式打开的意思是说将这个文件中的数据用十六进制方式进行显示,这两个概念不要混淆,两者不冲突。
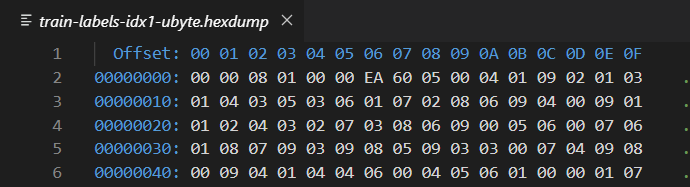
备注: 打开这四个文件我用的VSCode,大家可以在VSCode里寻找一个名为 hexdump 的插件就可以打开啦!如果有小伙伴用的是Notepad++,可以搜索一个名为 Hex-Editor 的插件,也可以打开。
这是啥??一堆数字??这玩意怎么变成图片和标签啊??先不慌哈,如果大家点开了上文中 MNIST数据集传送门 这个链接的话,往下翻你会找到这样的一张图片:

这样类似的图片一共有四张,分别对应于MNIST数据集解压出来的四个文件。这四个图片就是我们解读上面一堆数字的 使用说明书。我们就用上面这个训练标签集作为例子,看看这个说明书怎么用。
3.1 IDX文件的数据格式
IDX文件的基本数据格式是:地址-数据。我们可以把IDX文件想想成类似下图的收纳袋子,每个袋子上都有一个标号,如下图中的1,2,3白色数字所示。我们将这些白色数字称为 地址。袋子中装的东西称为 数据。

3.1.1 文件内地址构成
首先,我们来看看上述用十六进制方式打开的文件中 蓝色的数字。在垂直方向上是00000000、00000010、00000020…,水平方向上是00,01,02,03…0F。水平方向 上一共有16个标签,这16个标签对比上述口袋图可以理解为每个相同颜色的挂壁收纳袋共有16个小口袋构成。垂直方向 有5个标签,代表5个不同颜色的挂壁收纳袋。用上图中的两个挂壁收纳为例,可以理解为绿色挂壁袋中装的是编号为00000000行中的16个数据,粉色挂壁袋中装的是编号为00000010行中的16个数据。当我们需要取出具体的某一个数据时,只需要给出 颜色+地址编号 即可,例如:粉色第2个袋子。我们将 颜色 所表示的含义称为 基地址,对应于上述16进制蓝色数字中的垂直方向数字。口袋上的小编号的含义称为 偏移地址,对应于16进制蓝色数字中的水平方向数字。这样同理,当我们需要取IDX文件中某一个数据时,只需要给出 基地址+偏移地址 的组合即可拿到数据,例如 00000000+03 = 00000003,即表示数据01。(这一部分讲的有点啰嗦,目的是为了照顾基础稍微差一点的同学,还请大家谅解~)
3.1.2 文件内数据构成
其次,我们来说说每个袋子中存储的数据。上述IDX文件中,每个袋子存储的数据长度为8bit,即1个字节,对应于打开文件截图中的一个白色数据。 1个字节可以表示十进制0-255的数字范围,也恰好是灰度图像素的数值范围。
由于打开文件中数据的显示格式为十六进制,我们将255用十六进制显示,其数值为FF,也就是说在十六进制下,上图中每个白色数据的取值范围应该为0-FF。我们以 00000000(基地址)+06(偏移地址) = 000000006 中的EA数据为例,将其从十六进制转化为十进制为数据234,在0~FF的规定范围内,所以是合理的,并且占用一个字节(1个字节是8bit)。
3.1.3 说明书的使用
接下来,我们终于可以看说明书了。说明书中第一行标签中的 [offset] 代表 偏移地址。但是这个偏移地址和咱们上文中介绍的偏移地址不是一回事,这其中有个转换关系。咱们上文中提到的偏移地址仅仅从00~0F共16个,但是 说明书中的 “偏移地址” 是包括了 上文中 咱们提到的 “基地址+偏移地址” 的总地址。例如:当采用 说明书中 偏移地址0041进行表达的时候,代表了 上文中 介绍的 00000040+01 = 00000041 总地址的数据(后四位相同)。
说明书中 [type] 表示了当前元素的数据长度,[value] 表示了当前数据的数据值,[discription] 表示了当前数据的功能。例如,说明书中第一行的描述是magic number,占用了32bit(4个字节),数值是0x00000801。对应于我们打开的文件:
magic number 从0000地址开始,占用4个字节(32bit),上图中4个字节分别是00,00,08,01四个白色字体代表的数据,连接起来 00000801 恰好和给出的 [value] 数值 0x00000801相等(0x开头表示改数据是十六进制表示,恰好咱们打开文件的数据显示格式也是十六进制,所以相等)。
至于magic number是啥,在这里给大家简单的介绍一下。这个东西准确来讲叫 魔数, 也有人叫他为 幻数,它是用来表征一个文件的数据格式的,比如一个 .mp4 文件你可以强制改名将他变成 .txt 文件,虽然播放不了,但是并不影响采用文件方式对其进行数据提取。由于该文件魔数固定,即便名字是.txt,也不会影响数据访问。更多的大家可以自行百度哈~
我们再来看一个例子:说明书第二行给出的信息是 起始地址0004,描述为项目个数(标签个数),数据长度为4个字节(32bit),数值等于60000(没有0x前缀,表示十进制6万)。 对应于我们打开的文件:

数据从0004地址开始,占用4个字节(32bit),上图中4个字节分别是00,00,EA,60四个白色字体代表的数据,连接起来 0000EA60 化为十进制等于 60000,和给出的数据结论相等。
我们最后看一个例子:说明书第三行给出的信息是 起始地址0008,描述为标签内容,数据长度为1个无符号字节(8bit),数值等于未定。 对应于我们打开的文件:

数据从0008地址开始,占用1个字节(8bit),上图中1个字节是05白色字体代表的数据。即从0008地址开始,表示的是图像的标签,且第一张图片的标签就是手写体数字5。纵观打开的标签文件,在地址0008以后所有的数据内容没有超过09的,也就是说从0008地址开始,后面的每一个字节都代表了图片集中0-9相应的数字的标签。
以上就是说明书对应于数据文件的使用方法,在这里我们先留下一个 悬念 :根据标签数据集,训练数据集第一张图片打开应该是手写体数字5。若确实如此,我们就印证了2.2章节中给出的数据关联方式。
3.2 IDX文件打开与读取(Python版本)
鉴于前面的讲解咱们都以标签集为例子,该部分数据提取咱们以图像集为例子为大家展示。
闲话:在开始之前想先跟大家聊点编程问题, 因为今天上午(2019.12.24 平安夜)跟我学弟聊算法的时候他问了我一些工程问题的实现方法。当我跟他交流完毕之后,学弟觉得他的基础知识不够,对我说很多OpenCV的函数他都不清楚,问我要不要系统的学一学OpenCV,他还觉得他的基础太差了。在我看来,他的基础完全可以满足项目要求,只是代码写的少,没有针对问题的解决思路才导致他满脸疑惑。
相信很多刚刚接触代码的小伙伴都经历过这样的处境(博主也一样),感觉看了网上的代码或者讲解一脸懵逼,代码中的基本语法或者函数都没有用过,是不是需要把知识点系统的学习一遍。对此 我的建议 是:
- 分清楚你到底是知识点不会,还是编程经验太少。
- 如果知识点了解,但是看不懂函数,最佳的方法是百度一下,把你需要的功能看懂就可以了,先不必深究。
- 如果基础知识点不了解(例如:类,指针与地址,继承,结构体等),那你需要做的就是先简单的动手写一个该知识点的小例子,然后再回来看代码,看不懂再百度。
对于大部分工程应用来讲,思路的重要性是远远大于代码基础知识的。只有当逻辑能力,代码阅读量达到一定程度之后,才会有手到擒来的那种熟练感。所以在以后的博客中,凡是涉及到代码问题,我都会先跟大家聊聊思路或者原理,然后再给出代码内容分析。
3.2.1 思路剖析
对IDX文件中图像的提取操作可以理解为一个 解码问题:将已经通过固定格式存储起来的数据读取出来,并成功还原成为我们想要的形态。所以我们的思路可以归结为 以下三步:
- 将文件放到一个工作台上,打开外包装,暴露出内部数据;
- 将内部数据按照说明书中的内容,分别归纳到不同的收纳盒里,比如:装魔数的盒子,装数据样本的盒子等等;
- 重新将收纳盒中的数据进行整理,按照一定格式转化成我们想要的数据形态(比如转化为图像)。
我们将上述解码过程 组合成一个解码函数,按照上述步骤,为大家逐步讲解。
3.2.2 模块拆解-步骤1
1. Python 之 open() 函数:
bin_data = open(idx3file,'rb').read()
open() 函数的功能是用于打开一个文件,上述代码中 idx3file 参数是我们需要读取的待处理文件,rb 参数是说用只读方式对文件进行打开,不会对文件内容造成更改等影响。.read() 方法会将该文件中的 所有数据内容 作为返回值传递给 bin_data 变量。
经过上述函数的处理,我们完成了把文件内部数据暴露出来的过程,并将文件中的所有数据存放在了 bin_data 中,如果将 bin_data 打印出来,结果是这样的~

是不是很眼熟??是不是和说明书中,还有刚才第三章节用十六进制方式打开的文件的截图是一样格式的内容??
备注:
3.2.3 模块拆解-步骤2
1. Python 之 struct.unpack_from() 函数方法
fmt_header = '>iiii'
offset = 0
magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, bin_data, offset)
print ('幻数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols))
上面的代码我们从第四行开始看。struct.unpack_from() 这个方法用一句话概括其功能就是:从某个文件中以特定的格式读取出相应的数据。 使用该方法需要在文件开头 import struct 模块
我们先看该函数的第一个参数 fmt_header ,这个参数规定了数据的读取格式。从上述代码第一行的定义可知其数值为 >iiii,其中 > 符号代表数据读取方式采用 大端法 进行读取, i 代表 读取一个整数(int),该整数所占空间为4个字节(8bit*4 = 32bit)。以上的设定是系统定义好的,我们无法修改。换句话说,你要是问我为什么一个整数占用4个字节,我只能告诉你,人家语法规定,你也没法更改。所以 >iiii 用普通话解释一波就是 采用大端法在数据中读取4个整数,每个整数占用4个字节。
好了,现在是不是有小伙伴问我 大端法 是啥??不慌,我们先来看一个问题,同样是这个图:
根据上面的提取规则,一个整数占用4个字节,也就是说 00,00,08,01 这四个字节的数据会被组合成一个整数。那么组合后的整数到底是 00000801 呢?还是 10800000 呢? 对于计算机来说,他是不清楚这个事情的,咱们需要人为的告诉他一种计数顺序,然后计算机按照这个计数顺序来存储数据。大端法 的意思就是说 数据的高位 保存在 低地址中,按照大端法,最左边的00才是最高位,写出数据就是0x00000801,换算成十进制就是2049。与之相反,还有一种读取方式叫 小端法,小端法的意思是说 数据的高位 保存在 高地址中,写出数据就是0x10800000,换算成十进制就是276824064。我们的读取方式采用 大端法 进行。
现在我们看看第二个参数和第三个参数。bin_data 就是指需要读取的文件内容,和3.2.2章节 open()函数 得出的结果是同一个。offset 是数据读取的起始地址,它指定了数据具体从哪个位置开始截取。在代码第二行,offset 的数值被赋值为0,也就是说从文件的起始地址开始读取。
那可能有小伙伴会问,为啥要这么设置数据读模式?? 凭啥你说读取4个整数就读取4个整数?我读取5个,把指令变成 >iiiii 行不行???这个时候我们就要请出我们训练图片集的 使用手册 了,截图如下:

从上图中看出一共有4项基本信息占用了32bit(4个字节),分别是魔数,图片数量,每张图片行数,每张图片列数,所以代码设置读取格式才为 >iiii,每个 i 对应一个具体含义信息。看到这里再看看上面的代码,是不是函数 struct.unpack_from() 的返回值全部与上述信息对应??给大家一个打印出来的输出结果:
打印的结果也和说明书中数据相同,说明数据读取完全正确~~
备注:struct 模块详解 (打开后左上角可以调整语言)
备注:大小端读取数据详解
3.2.4 模块拆解-步骤3
因为魔数,图片数量,每张图片行数,每张图片列数这些数据是 固定格式的单独数据,不需要进行重新组合,所以直接读取出来就可以了。但是图片数据不同,图片数据需要我们对其进行数据组合。所以实现起来要比较麻烦,具体代码如下:
#定义一张图片需要的数据个数(每个像素一个字节,共需要行*列个字节的数据)
img_size = num_rows*num_cols
#struct.calcsize(fmt)用来计算fmt格式所描述的结构的大小
offset += struct.calcsize(fmt_header)
# '>784B'是指用大端法读取784个unsigned byte
fmt_image = '>' + str(img_size) + 'B'
#定义了一个三维数组,这个数组共有num_images个 num_rows*num_cols尺寸的矩阵。
images = np.empty((num_images, num_rows, num_cols))
for i in range(num_images):
images[i] = np.array(struct.unpack_from(fmt_image, bin_data, offset)).reshape((num_rows,num_cols))
offset += struct.calcsize(fmt_image)
前8行代码相信大家都能看懂,也已经添加了备注,如果看不懂可以点击下面的备注慢慢理解。我们重点从第11行说起。 第11行中,我们定义了一个巨大的三维数组,这个数组用来接收重组数据后的图像,每张图像的尺寸是28 * 28(num_rows * num_cols),共需要60000张图(num_images)。第13行开始的60000次循环操作就是在重组每一张图像信息,并存放在 image 数组中。第14行是数图像数据重组的核心操作,先将 每一张图片的数据 从数据集中提取出来,然后转换成 numpy 格式的数组(此时数据为一维数组),再通过 numpy.reshape() 方法转换为 28 * 28 (num_rows * num_cols)的二维图像矩阵。在转换完毕后,跳过当前图片的数据地址,开始下一轮的转换。
备注:
备注:
备注:
备注:
至此,IDX文件的所有介绍,包括读取部分全部结束。 我们把 3.1.3 章节末尾留下的悬念为大家展示一下,通过下面第4章的代码,我们输出提取图像的第一张:

可以看出来这是个阿拉伯数字5吧?和标签中的5对应吧?说明 确实是一一对应的关系。验证成功~~~!!
4. 完整代码
# 作者:打团从来人不齐;
# 时间:2019.12.24(平安夜);
# 说明:MNIST数据集提取代码;
# 版本:V1.0;
# 维护:打团从来人不齐;
import numpy as np
import struct
import matplotlib.pyplot as plt
import cv2
Train_IMG_idx3_file = ""
Train_LBL_idx1_file = ""
Test_IMG_idx3_file = ""
Test_LBL_idx1_file = ""
def decode_idx3(idx3file):
#读取二进制数据:
bin_data = open(idx3file,'rb').read()
fmt_header = '>iiii'
offset = 0
magic_number, num_images, num_rows, num_cols = struct.unpack_from(fmt_header, bin_data, offset)
print ('魔数:%d, 图片数量: %d张, 图片大小: %d*%d' % (magic_number, num_images, num_rows, num_cols))
img_size = num_rows*num_cols
offset += struct.calcsize(fmt_header)
# '>784B'的意思就是用大端法读取784个unsigned byte
fmt_image = '>' + str(img_size) + 'B'
images = np.empty((num_images, num_rows, num_cols))
for i in range(num_images):
images[i] = np.array(struct.unpack_from(fmt_image, bin_data, offset)).reshape((num_rows,num_cols))
offset += struct.calcsize(fmt_image)
return images
image_data = decode_idx3(Train_IMG_idx3_file)
cv2.imshow("test",image_data[0])
cv2.waitKey(0)
5.写在最后
哇!终于写完了,实在是写的太长了~~~可能大家读的都没有耐心了,不过博主相信,这一定你能找到的MNIST数据集最为详尽的博客之一,还是希望大家多多关注,评论,和提出宝贵的修改意见!!你们的支持是我的不竭动力!!撒花~
(来自一名励志用“普通话”讲技术的菜狗子~)