在 Oracle 数据库表中加载多个数据文件
在本文中,我将展示 SQL 加载器 + Unix 脚本实用程序的强大功能,其中 SQL 加载器可以使用自动 shell 脚本加载多个数据文件。这在处理大量数据以及需要将数据从一个系统移动到另一个系统时非常有用。
它适合涉及大量历史数据的迁移项目。那么就不可能为每个文件运行 SQL 加载程序并等待其加载。因此,最好的选择是让包含 SQL 加载命令的 Unix 程序始终运行。一旦文件夹位置中有任何文件可用,它将从该文件夹位置拾取文件并立即开始处理。
设置
示例程序是我做的。在 Macbook 中,Oracle 的安装与 Windows 机器上的安装有所不同。
请观看包含如何在 Mac 上安装 Oracle 的详细步骤的视频。
让SQL 开发人员遵守 Java 8。
现在让我们来演示一下这个例子。
在 Oracle DB 表中加载多个数据文件
因为它是 Macbook,所以我必须在 Oracle 虚拟机内完成所有操作。
让我们看看下图 SQL Loader 是如何工作的。
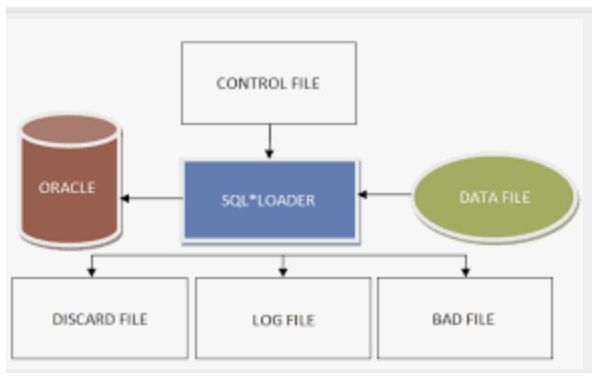
使用案例
需要使用 Shell 脚本 + SQL 加载器自动化将数百万学生的信息加载到学生表中。该脚本将始终在 Unix 服务器中运行并轮询。DAT 文件,一旦 DAT 文件就位,它将对其进行处理。另外,如果存在任何不良数据,则需要单独识别它们。
此类示例在需要加载数百万历史记录的迁移项目中非常有用。
-
从旧系统,将定期生成实时源(DAT 文件)并将其发送到新系统服务器。
-
在新系统中,服务器文件可用,并将使用自动化 Unix 脚本加载到数据库中。
-
现在让我们运行脚本,该脚本可以在Unix服务器上一直运行。为了实现这一点,整个代码被放入下面的 while 块中。
while true[some logic]done
过程
1、我已复制以下文件夹中的所有文件+文件夹结构。
/home/oracle/Desktop/example-SQLdr/
2、请参阅以下文件(ls -lrth)
rwxr-xr-x. 1 oracle oinstall 147 Jul 23 2022 student.ctl
-rwxr-xr-x. 1 oracle oinstall 53 Jul 23 2022 student_2.dat
-rwxr-xr-x. 1 oracle oinstall 278 Dec 9 12:42 student_1.dat
drwxr-xr-x. 2 oracle oinstall 48 Dec 24 09:46 BAD
-rwxr-xr-x. 1 oracle oinstall 1.1K Dec 24 10:10 TestSqlLoader.sh
drwxr-xr-x. 2 oracle oinstall 27 Dec 24 11:33 DISCARD
-rw-------. 1 oracle oinstall 3.5K Dec 24 11:33 nohup.out
drwxr-xr-x. 2 oracle oinstall 4.0K Dec 24 11:33 TASKLOG
-rwxr-xr-x. 1 oracle oinstall 0 Dec 24 12:25 all_data_file_list.unx
drwxr-xr-x. 2 oracle oinstall 6 Dec 24 12:29 ARCHIVE3、如下图,student表中没有数据。
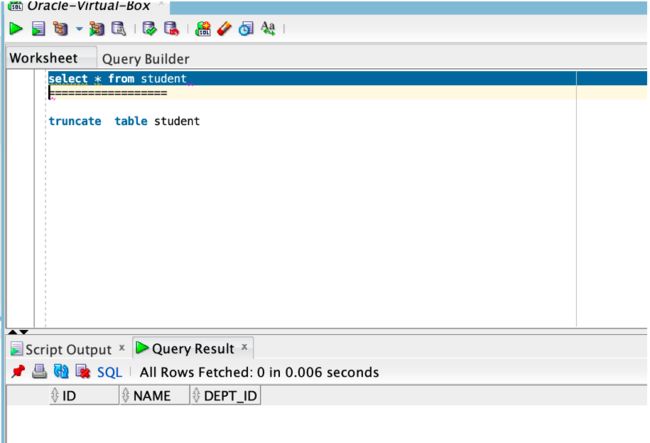
4、现在使用以下命令运行脚本nohup.out ./TestSqlLoader.sh 通过这样做,它将始终在 Unix 服务器中运行。
5、现在脚本将运行,它将通过 SQL 加载器加载两个 .dat 文件。
6、该表应加载两个文件的内容。
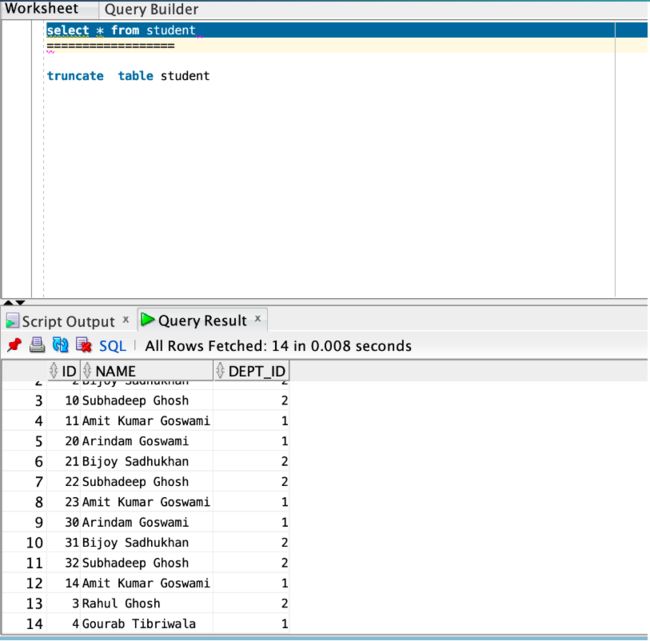
7、现在我再次删除表数据,只是为了证明脚本始终在服务器中运行,我将仅将两个 DAT 文件从 ARCHIVE 放置到当前目录。
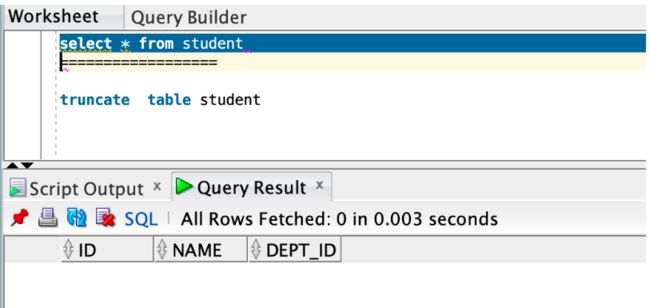
8、再次将这两个数据文件放入当前目录中。
-rwxr-xr-x. 1 oracle oinstall 147 Jul 23 2022 student.ctl
-rwxr-xr-x. 1 oracle oinstall 53 Jul 23 2022 student_2.dat
-rwxr-xr-x. 1 oracle oinstall 278 Dec 9 12:42 student_1.dat
drwxr-xr-x. 2 oracle oinstall 48 Dec 24 09:46 BAD
-rwxr-xr-x. 1 oracle oinstall 1.1K Dec 24 10:10 TestSqlLoader.sh
drwxr-xr-x. 2 oracle oinstall 27 Dec 24 12:53 DISCARD
-rw-------. 1 oracle oinstall 4.3K Dec 24 12:53 nohup.out
drwxr-xr-x. 2 oracle oinstall 4.0K Dec 24 12:53 TASKLOG
-rwxr-xr-x. 1 oracle oinstall 0 Dec 24 13:02 all_data_file_list.unx
drwxr-xr-x. 2 oracle oinstall 6 Dec 24 13:03 ARCHIVE9、再次看到 Student 表已加载所有数据。
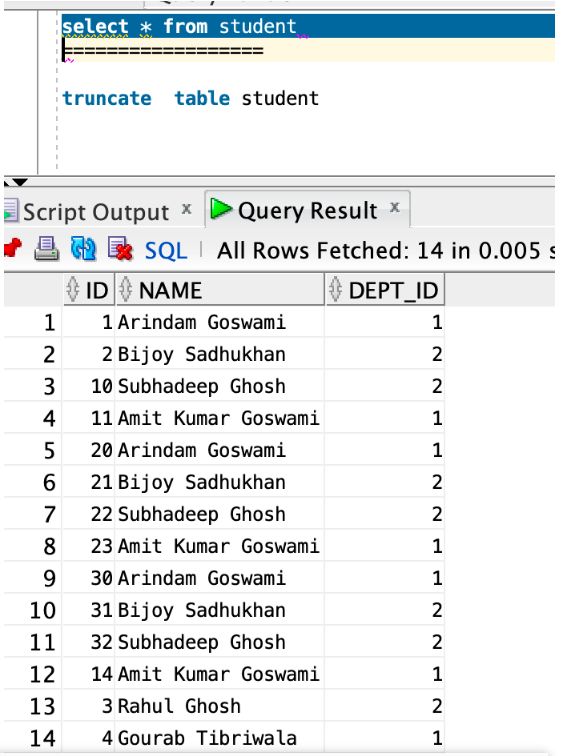
10、该脚本始终在服务器上运行
[oracle@localhost example-sqldr]$ ps -ef|grep Test
oracle 30203 1 0 12:53? 00:00:00 /bin/bash ./TestSqlLoader.sh
oracle 31284 31227 0 13:06 pts/1 00:00:00 grep --color=auto Test完整源代码供参考
#!/bin/bash
bad_ext='.bad'
dis_ext='.dis'
data_ext='.dat'
log_ext='.log'
log_folder='TASKLOG'
arch_loc="ARCHIVE"
bad_loc="BAD"
discard_loc="DISCARD"
now=$(date +"%Y.%m.%d-%H.%M.%S")
log_file_name="$log_folder/TestSQLLoader_$now$log_ext"
while true;
do
ls -a *.dat 2>/dev/null > all_data_file_list.unx
for i in `cat all_data_file_list.unx`
do
#echo "The data file name is :-- $i"
data_file_name=`basename $i .dat`
echo "Before executing the sql loader command ||Starting of the script" > $log_file_name
sqlldr userid=hr/oracle@orcl control=student.ctl errors=15000 log=$i$log_ext bindsize=512000000 readsize=500000 DATA=$data_file_name$data_ext BAD=$data_file_name$bad_ext DISCARD=$data_file_name$dis_ext
mv $data_file_name$data_ext $arch_loc 2>/dev/null
mv $data_file_name$bad_ext $bad_loc 2>/dev/null
mv $data_file_name$dis_ext $discard_loc 2>/dev/null
mv $data_file_name$data_ext$log_ext $log_folder 2>/dev/null
echo "After Executing the sql loader command||File moved successfully" >> $log_file_name
done
## halt the procesing for 2 mins
sleep 1m
doneCTL 文件如下。
OPTIONS (SKIP=1)LOAD DATAAPPENDINTO TABLE studentFIELDS TERMINATED BY '|' OPTIONALLY ENCLOSED BY '"'TRAILING NULLCOLS(id,name,dept_id)
SQL 加载器规范
1. control --> name of the .ctl file
2.errors=15000(SQL Loader 允许的最大错误数)
3.log=$i$log_ext(日志文件的名称)
4.bindsize=512000000(绑定数组的最大大小)
5.readsize=500000(最大大小)
6. DATA=$data_file_name$data_ext(数据文件的名称和位置)
7. BAD=$data_file_name$bad_ext(坏文件的名称和位置)
8. DISCARD=$data_file_name$dis_ext(丢弃文件的名称和位置)
综上所述,这种方式可以通过SQL加载器+Unix脚本自动化的方式加载数百万条记录,以上参数可以根据需要设置。
作者:ARINDAM GOSWAMI
更多技术干货请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
irds.cn,多数据库管理平台(私有云)。