求topk——CUDA on ARM Platform夏令营 Day04 课后作业
前言:对相关基础知识了解的朋友可跳过第一部分,本文求topk的思想是在向量元素求和思想的基础上得到的,读者理清楚后会更容易理解如何求topk。
有图解哦~ ヾ(✿゚▽゚)ノ
目录
- 1. 相关基础知识回顾
-
- 1.1 grid与block与thread
- 1.2 shared memory与register
- 1.3 C语言指针与数组
- 2. 向量元素求和
- 3. 向量元素求topk
-
- 3.1 元素求和思想转变
- 3.2 insert_value函数
- 3.3 kernel函数及坐标计算
1. 相关基础知识回顾
1.1 grid与block与thread
主要讲解线程层次和相关内置变量的含义,这对后面的坐标计算很重要。
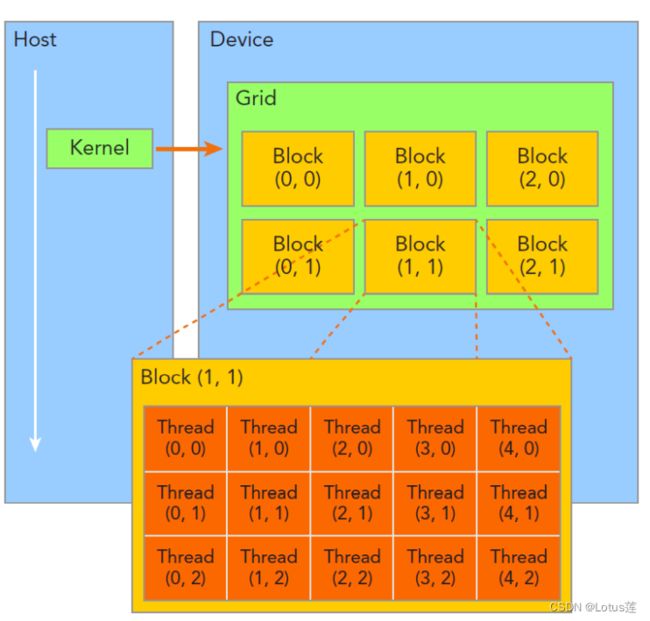
(上图来自夏令营PPT,可以很清楚地看出线程层次)
- Dim表示其所包含的下一层次元素的个数。比如blockDim.[x y z]表示一个block包含多少个thread。
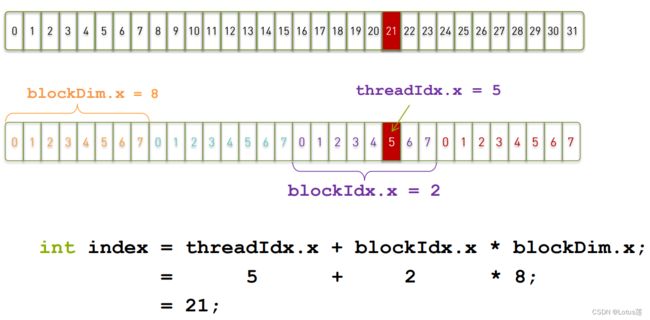
- Idx表示其在上一层次中的索引值。比如threadIdx.[x y z]表示当前thread在block中的索引值。注意此索引不是thread在所有thread中的索引,全局索引计算方法如下(下图来自夏令营PPT):
1.2 shared memory与register
主要介绍shared memory与register所在位置,这对理解后面的计算任务思想很重要。
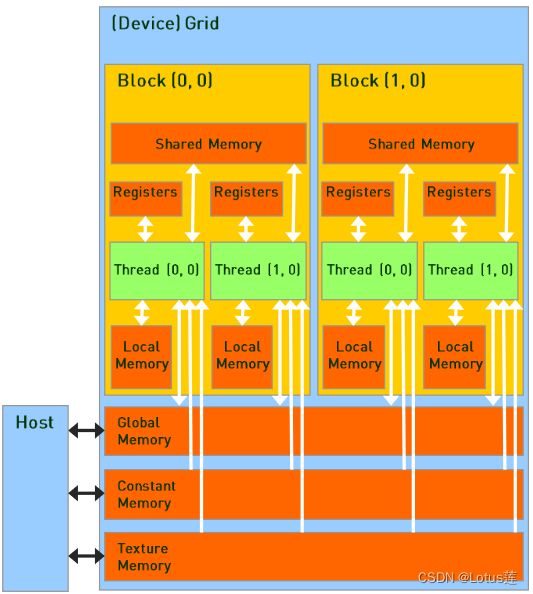
(上图来自夏令营PPT)
- 每个thread拥有一个属于自己的register。
- 每个block拥有一块属于自己的shared memory,其中的thread都能访问,可以借此协作完成一些任务。
1.3 C语言指针与数组
这里主要是介绍C语言指针与数组,这两者间的转换也会用于后续计算坐标,本人在用到的时候开始有些遗忘,所以在这里记录一下。(部分知识点参考于谭浩强老师C程序设计(第五版))
对于一维数组int a[10]来说,变量名a即为数组首元素的地址。所以int *p=a;即将该地址赋给了指针变量p。
那么此时要想通过指针p访问数组a中其他元素的值怎么办呢?如下图所示(来自谭浩强老师C程序设计(第五版)):在指针变量上加上对应的偏移量,指针变量就能指向对应的数组元素。

2. 向量元素求和
本部分代码来自夏令营所给例程。
核函数如下:
__global__ void _sum_gpu(int *input, int count, int *output)
{
__shared__ int sum_per_block[BLOCK_SIZE];
int temp = 0;
for (int idx = threadIdx.x + blockDim.x * blockIdx.x;
idx < count; idx += gridDim.x * blockDim.x
)
{
temp += input[idx];
}
sum_per_block[threadIdx.x] = temp; //the per-thread partial sum is temp!
__syncthreads();
//**********shared memory summation stage***********
for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2)
{
int double_kill = -1;
if (threadIdx.x < length)
{
double_kill = sum_per_block[threadIdx.x] + sum_per_block[threadIdx.x + length];
}
__syncthreads(); //why we need two __syncthreads() here, and,
if (threadIdx.x < length)
{
sum_per_block[threadIdx.x] = double_kill;
}
__syncthreads(); //....here ?
} //the per-block partial sum is sum_per_block[0]
if (blockDim.x * blockIdx.x < count) //in case that our users are naughty
{
//the final reduction performed by atomicAdd()
if (threadIdx.x == 0) atomicAdd(output, sum_per_block[0]);
}
}
要说清楚这个过程需要各种图(都是夏令营PPT的图或有一定修改)!
- 声明位于shared memory的变量:__shared__ int sum_per_block[BLOCK_SIZE];用于存放每个block中每个thread计算的求和值(具体是什么和将会随程序推进发生变化)。
- 第一部分循环充分利用了每个thread的寄存器空间,用单个thread计算了向量元素中跨步长gridDim.x * blockDim.x(此相乘结果即为所有的thread数)元素的和。此思想即为总thread不够用时,一个thread处理多个元素~
一个thread计算了上述对应位置的元素之和放在temp变量中,然后将计算的结果放在该thread在sum_per_block中对应的位置上,注意这里使用的索引是threadIdx.x,是该thread在所在block中的坐标!
具体过程可见下图,如线程10就计算了a[10],a[42],a[74]这三个元素的和。

还有记得写shared memory用__syncthreads();同步!! - 下面将进行block中thread间暂加值的再求和,为了提高效率可以进行如下图所示的两两相加。
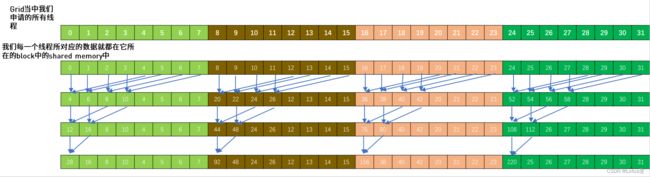
所以随着累加的进行,每次两两相加间的步长需要对半分,直到最后结果存放在了每个block的threadIdx.x=0的thread在sum_per_block中对应的位置,即sum_per_block[0]。这个过程中也不要忘记同步!
也可见上述过程中每次只会有上次一半的thread继续工作,因此上一步骤中充分利用寄存器减少这个过程最开始需要的thread数,可以更好地利用thread资源~ - 那么现在只需要将所有block中的sum_per_block[0]相加就可得到最终结果了。
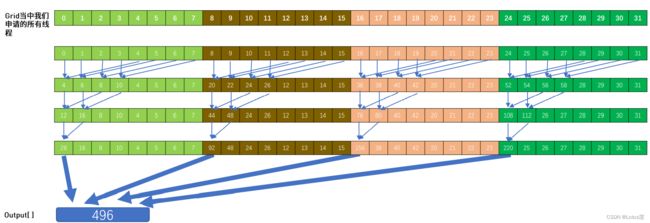
为了避免此累加过程相互影响,这里用到了原子操作atomicAdd(output, sum_per_block[0])实现了对多线程共享的output变量的互斥保护,保证了计算结果的正确性。
3. 向量元素求topk
本部分代码除核函数外来自夏令营所给例程。
3.1 元素求和思想转变
由上述思想我们可以尝试将其用在求topk的任务中,将原来的求和过程变为相互之间比较大小且保留前topk元素,难点在于需要维护数组变量和找到正确的索引值。
3.2 insert_value函数
这个函数是实现寻找topk的关键之一。代码如下:
__device__ __host__ void insert_value(int* array, int k, int data)
{
for (int i = 0; i < k; i++)
{
if (array[i] == data)
{
return;
}
}
if (data < array[k - 1])
return;
for (int i = k - 2; i >= 0; i--)
{
if (data > array[i])
array[i + 1] = array[i];
else {
array[i + 1] = data;
return;
}
}
array[0] = data;
}
- 第一个for循环寻找array的topk中是否有与输入data相同的元素,有则不再重复记录直接return。
- 接下来的if判断data是否比array的topk中最小的一个数还要小,是则直接return。
- 然后从topk的倒数第二个元素开始比较,若data比之更大,则该元素向后一个位置复制,再循环直到比较出data是最大的放在array[0]或者比某个数更小了放在它后面然后return。
3.3 kernel函数及坐标计算
相关代码如下:
#define topk 10
__managed__ int source_array[N];
__managed__ int _1pass_results[topk * GRID_SIZE];
__managed__ int final_results[topk];
__global__ void top_k(int* input, int length, int* output, int k)
{
__shared__ int topk_per_block[BLOCK_SIZE*topk];
int top_kt[topk] = {0};
for(int i=blockDim.x*blockIdx.x+threadIdx.x; i<length; i+=gridDim.x*blockDim.x){
insert_value(top_kt, k, input[i]);
}
for(int i=0; i<topk; i++)
topk_per_block[threadIdx.x*k+i] = top_kt[i];
__syncthreads();
for(int len=BLOCK_SIZE/2; len>=1; len/=2){
if(threadIdx.x<len){
for(int i=0; i<k; i++)
insert_value(topk_per_block+threadIdx.x*k, k, topk_per_block[(threadIdx.x+len)*k+i]);
}
__syncthreads();
}
if(blockDim.x * blockIdx.x < length)
if (threadIdx.x == 0){
for(int i=0; i<k; i++)
output[k*blockIdx.x+i] = topk_per_block[i];
}
}
int main(int argc, char const* argv[])
{
...
top_k <<<GRID_SIZE, BLOCK_SIZE >>>(source_array, N, _1pass_results, topk);
top_k <<<1, BLOCK_SIZE >>>(_1pass_results, topk * GRID_SIZE, final_results, topk);
...
}
- 由于需要存放topk个元素,所以声明变量大小为BLOCK_SIZE*topk。
- 这里大致思路也相同,主要是数组top_kt中的元素需要循环放入对应位置,且由于每个thread对应需要在topk_per_block中存topk个元素,所以每个thread对应存放的起始位置为threadIdx.x*k。
- 同样类似地,循环比较两两间的topk元素,注意比较时步长len也要加在*k的括号里。这一步就将每个block的topk放在topk_per_block数组的前topk中了。
- 然后再将每个block的前topk结果再赋值给output对应的位置,对应的起始位置是k*blockIdx.x。
- 显然经过此役还没有得到最终的结果,只得到了每个block中的topk,所以还需要再调用一次核函数,只再用一个block重复上述过程就可以得到最终整个topk的结果啦~
最终运行结果:
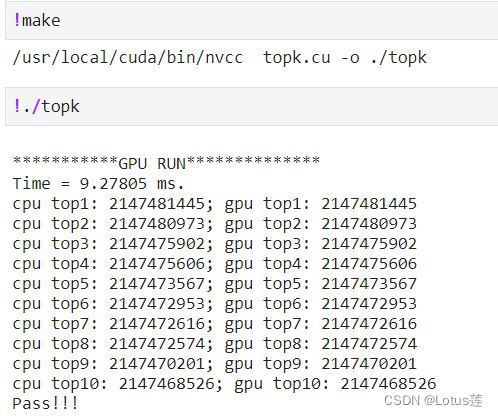
其实还可以加上topk在原向量中坐标的寻找哦ヽ(* ̄▽ ̄*)ノ
读者朋友们可以试试在此基础上修改各函数,增加向量中坐标的相关变量完成上述任务。