Python爬虫之多线程爬取小说
博主:一只程序猿子
博客主页:一只程序猿子 博客主页
个人介绍:爱好(bushi)编程!
创作不易:喜欢的话麻烦您点个和⭐!
欢迎访问我的主页(点我直达)
除此之外您还可以通过个人名片联系我
额滴名片儿
目录
1.介绍
2.技术介绍
(1)threading
(2)queue
(3)lxml
3.爬取过程分析
(1)找到完本小说排行榜
(2)获取每一篇小说的信息
(3)获取某篇小说所有章节的信息
(4)多线程下载所有章节的内容
(5)合并该小说的所有章节
4.源码
5.运行效果
1.介绍
本文讲介绍如何使用Python编写爬虫爬取小说网站的小说!在本文中,我们将使用多线程技术提高爬取的效率。
2.技术介绍
(1)threading
Python的threading库是Python标准库中的一个模块,用于实现多线程编程。它提供了一些简单的线程控制机制,使得程序员可以轻松地创建和管理线程。
threading库中的Thread类是实现多线程的核心类,可以创建多个线程,并对线程的状态进行控制。通过调用线程对象的start()方法可以启动线程,线程启动后会自动执行run()方法中的代码。线程的执行可以通过join()方法来等待线程完成。
我们将在本文代码中使用该库来实现多线程爬取!
(2)queue
Python的
queue库(在Python 2.x中名为Queue)是Python标准库中的一个模块,提供了线程安全的队列实现。这个库在多线程编程中特别有用,因为当多个线程需要安全地交换数据时,它可以作为一个中间的数据结构来保证数据的安全性和一致性。
queue库中有三种类型的队列:
- FIFO队列(先进先出):这是最常见的队列类型,其中元素的添加和移除都是按照它们首次出现的顺序进行的。可以通过
queue.Queue(maxsize)来创建一个FIFO队列,其中maxsize是一个整数,用于设置队列中可以放入的项目数的上限。- LIFO队列(后进先出):这种队列类似于一个栈,后添加的元素会先被移除。可以使用
queue.LifoQueue(maxsize)来创建一个LIFO队列。- 优先级队列:在这种队列中,元素是按照它们的优先级被移除的,优先级最低的元素会最先被移除(或者可以根据设置的最高优先级来移除元素)。元素通常是以元组的形式存储的,例如
(priority_number, data),其中priority_number表示优先级。可以使用queue.PriorityQueue(maxsize)来创建一个优先级队列。除了队列类型外,
queue库还提供了一些常用的方法,如put()用于向队列中添加元素,get()用于从队列中移除并返回元素,以及empty()用于检查队列是否为空等。在多线程应用中,由于多个线程可能同时访问和修改共享数据,因此使用线程安全的队列是很重要的。
queue库提供的队列实现是线程安全的,这意味着在多线程环境中,你可以放心地使用这些队列来进行数据交换和通信,而不用担心数据的一致性和安全性问题。
我们将使用该库生成一个队列,用于存放爬取任务,保证数据的安全性和一致性。
(3)lxml
lxml是Python中一个非常快速和方便的XML和HTML解析库。其中,etree是lxml中的一个模块,提供了对XML和HTML文档的解析和操作功能。
etree模块提供了以下几个常用的类:
- Element:表示XML或HTML文档中的元素。可以通过Element类创建新的元素,并可以添加子元素、属性和文本内容。
- SubElement:表示元素的一个子元素。可以使用SubElement类在现有元素下创建子元素。
- ElementTree:表示整个XML或HTML文档。可以使用ElementTree类创建整个文档,并将元素添加到文档中。
- fromstring()和parse():这两个函数可以从字符串或文件中解析XML或HTML文档,并返回一个ElementTree对象。
etree模块还提供了一些常用的方法,如find()、findall()、xpath()等,用于在XML或HTML文档中查找元素。这些方法可以方便地查找具有特定属性、标签名或路径的元素。
使用lxml的etree模块可以方便地解析、操作和生成XML和HTML文档,使得在Python中进行XML和HTML处理更加简单和高效。
我们将使用该库的etree模块在HTML文档中查找我们需要的内容!
3.爬取过程分析
(1)找到完本小说排行榜

(2)获取每一篇小说的信息
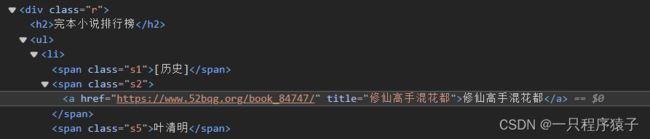
(3)获取某篇小说所有章节的信息

(4)多线程下载所有章节的内容
因为小说的章节较多,使用多线程下载每个章节的内容会提高爬取效率。
(5)合并该小说的所有章节
最终实现把整本小说存放到一个.txt文档中!
4.源码
import os
import threading
import time
from threading import Thread
import requests
from lxml import etree
from queue import Queue
from Fiction_Spider.settings import headers
# 创建了一个具有最大长度为 10000 的先进先出(FIFO)队列。
q = Queue(10000)
# 1. 获取完本小说排行榜中的小说信息
def get_fiction_list():
fiction_list_url = "https://www.52bqg.org/wanben/"
req = requests.get(url=fiction_list_url, headers=headers).text
# print(req)
html = etree.HTML(req)
fiction_types = html.xpath('//div[@id="newscontent"]/div[2]//span[@class="s1"]/text()')
# print(fiction_types)
fiction_urls = html.xpath('//div[@id="newscontent"]/div[2]//a/@href')
# print(fiction_urls)
return fiction_types, fiction_urls, fiction_titles, fiction_authors
# 2.获取一本小说的所有章节信息
def get_chapter(fiction_url):
# fiction_url = "https://www.52bqg.org/book_84747/"
req = requests.get(url=fiction_url, headers=headers).text
html = etree.HTML(req)
chapter_urls = html.xpath('//div[@id="list"]//a/@href')[12:22] # 去掉22获取所有章节url
chapter_titles = html.xpath('//div[@id="list"]//a/text()')[12:22] # 去掉22获取所有章节标题
# print(chapter_urls)
# print(chapter_titles)
return chapter_titles
# 3.获取小说的一个章节的内容
def get_content(chapter_url, chapter_title):
max_retries = 3
session = requests.Session()
retries = 0
while retries < max_retries:
try:
resp = session.get(chapter_url)
resp.raise_for_status() # 如果响应状态码不是200,则引发HTTPError异常
html = etree.HTML(resp.text)
content = html.xpath('//div[@id="content"]/text()')[1:]
content = f'{chapter_title}\n\n' + '\n\n'.join(content) + '\n\n'
# print(content)
return content
# 4.下载一本小说的所有章节的内容
def download():
while not q.empty():
chapter_url, chapter_title = q.get()
content = get_content(chapter_url, chapter_title)
if content != "":
with open(f'data/{chapter_title}.txt', 'w', encoding='utf-8') as f:
f.write(content)
print(f'{threading.current_thread().name}已下载.....{chapter_title}')
else:
q.put([chapter_url, chapter_title])
time. Sleep(1)
# 5.合并一本小说的所有章节
def merge(chapter_titles, book_name):
with open(f'data/{book_name}.txt', 'a', encoding='utf-8') as f:
for chapter_title in chapter_titles:
file_path = f"data/{chapter_title}.txt"
if os.path.exists(file_path):
with open(file_path, 'r', encoding='utf-8') as fp:
content = fp.read()
f.write(content)
print(f'已合并....{chapter_title}')
os.remove(file_path)
print(f'已删除....{chapter_title}')
# 主程序
def main():
fiction_types, fiction_urls, fiction_titles, fiction_authors = get_fiction_list()
for fiction_type, fiction_url, fiction_title, fiction_author in\
zip(fiction_types, fiction_urls, fiction_titles, fiction_authors):
chapter_titles = get_chapter(fiction_url)
book_name = f'【{fiction_type}】_{fiction_title}_{fiction_author}'
tasks = []
for i in range(3):
th = Thread(target=download, name=f'线程{i}')
th.start()
tasks.append(th)
for task in tasks:
task.join()
merge(chapter_titles, book_name)
print(f'已爬取 {book_name} 全部章节....休息三秒继续\n\n\n')
time.sleep(3)
# 主控制程序
if __name__ == '__main__':
main()
注意:篇幅有限,这里仅提供部分源码!需要完整源码可以通过开头的名片或文末的名片联系我!
5.运行效果
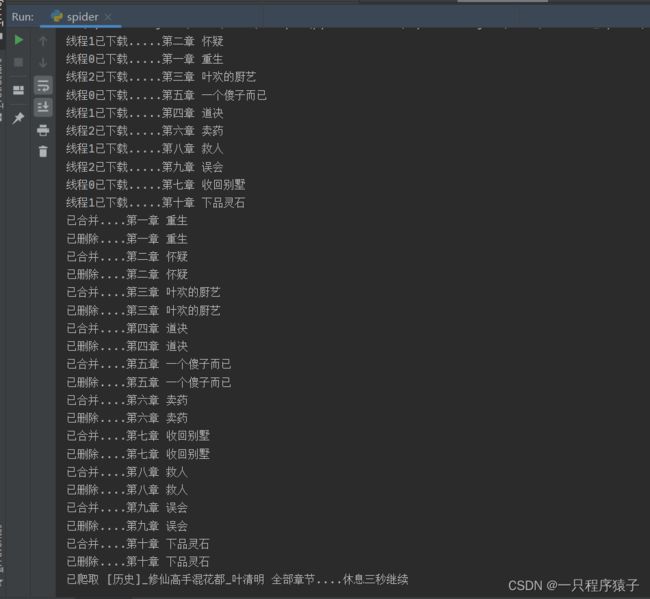
这里我为了进行展示,设置成每篇小说只爬取了前10章,可在源码中修改爬取全部章节 !
 这里为了演示,在爬取了三篇小说后我主动关闭了爬虫的运行!
这里为了演示,在爬取了三篇小说后我主动关闭了爬虫的运行!
