Python爬虫-爬取当日中药材价格数据
博主:一只程序猿子
博客主页:一只程序猿子 博客主页
个人介绍:爱好(bushi)编程!
创作不易:喜欢的话麻烦您点个和⭐!
欢迎访问我的主页(点我直达)
除此之外您还可以通过个人名片联系我
额滴名片儿
目录
1.介绍
2.分析
(1)数据来源
(2)找到对应的数据包
(3)查看请求信息
3.爬取流程
4.源码
5.效果展示
1.介绍
本文将介绍如何编写python爬虫,爬取药通网的中药材市场价格!数据集结合pandas,echarts进行处理分析和可视化,用作学年设计太合适不过了!
2.分析
(1)数据来源
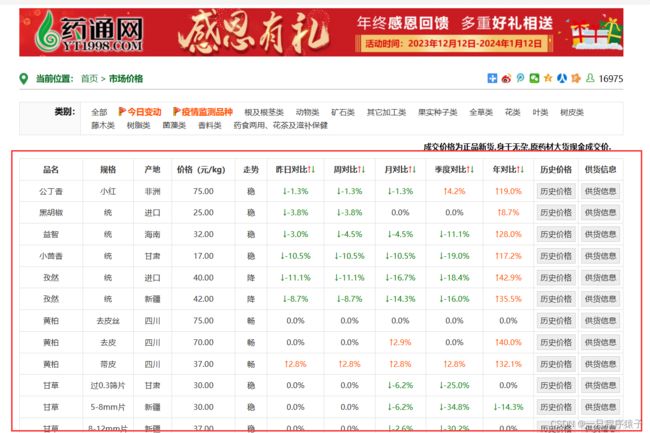
(2)找到对应的数据包
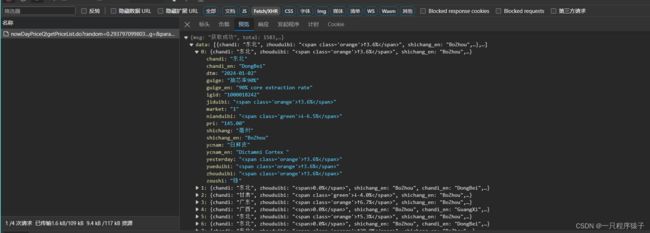
(3)查看请求信息

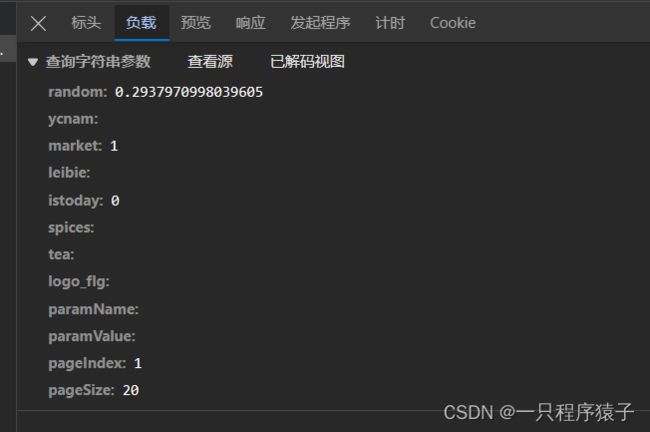
请求的参数中,只需要修改pageIndex的值,即可实现换页!
3.爬取流程
逐页发送请求,获取服务器返回的数据,然后把数据稍加处理后保存到CSV表格中.
注意:需控制爬取到速度,爬取过快会导致服务器连接超时!
4.源码
import csv
import time
import requests
from yaotongwang_zhongyao_price.settings import cookies, headers
from lxml import etree
import pandas as pd
# 1.获取当前页面中的所有中药材价格
def get_zhongyao_price(page):
# 定义请求参数
global data
params = {
'random': '0.35934104418089574',
'ycnam': '',
'market': '1',
'leibie': '',
'istoday': '0',
'spices': '',
'tea': '',
'logo_flg': '',
'paramName': '',
'paramValue': '',
'pageIndex': page,
'pageSize': '20',
}
response = requests.get(
'https://www.yt1998.com/price/nowDayPriceQ!getPriceList.do',
params=params,
cookies=cookies,
headers=headers,
)
if response.json()['msg'] == '获取成功':
items = response.json()['data']
# 定义空列表存放中药材信息
data = []
zhongyao_info_dict['月对比'] = item['yueduibi']
zhongyao_info_dict['市场'] = item['shichang']
zhongyao_info_dict['统计时间'] = item['dtm']
data.append(zhongyao_info_dict)
else:
print('暂未获取到当前页面的内容!')
return data
def save_to_csv(data):
# 定义文件路径
file_path = './data/今日中药材价格1.csv'
with open(file_path, 'a', encoding='utf-8', newline='') as csvfile:
fieldnames = ['名称', '规格', '产地', '价格(元/kg)', '走势', '月对比', '市场', '统计时间'] # 列名
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# 写入数据
writer.writerows(data)
# 主程序
def main():
for i in range(4):
save_to_csv(get_zhongyao_price(i))
if i < 3:
print(f'第 {i} 页已保存, 休息2秒后继续...')
time.sleep(2)
else:
print(f'第 {i} 页已保存, 爬虫运行完成...')
# 主控制程序
if __name__ == '__main__':
main()
setting.py:
# 定义cookie
cookies = {
'换成你自己的'
}
# 定义请求头
headers = {
'authority': 'www.yt1998.com',
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/Json',
'referer': 'https://www.yt1998.com/priceInfo.html',
'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Microsoft Edge";v="120"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'x-requested-with': 'XMLHttpRequest',
}
篇幅有限,仅提供部分源码,完整源码请通过我的个人名片联系我获取!
5.效果展示
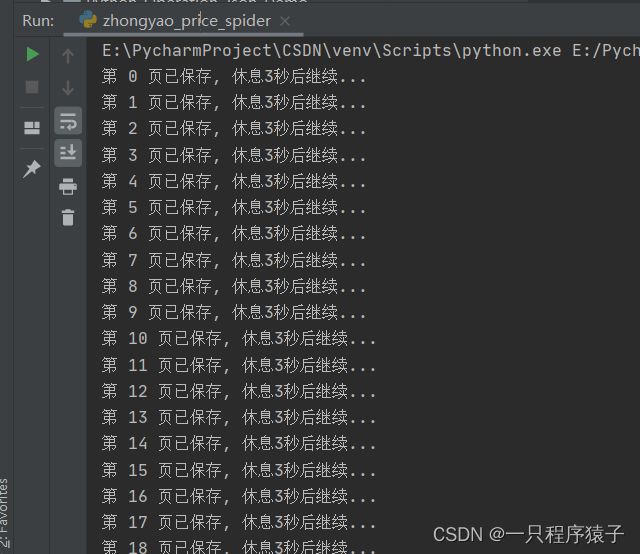
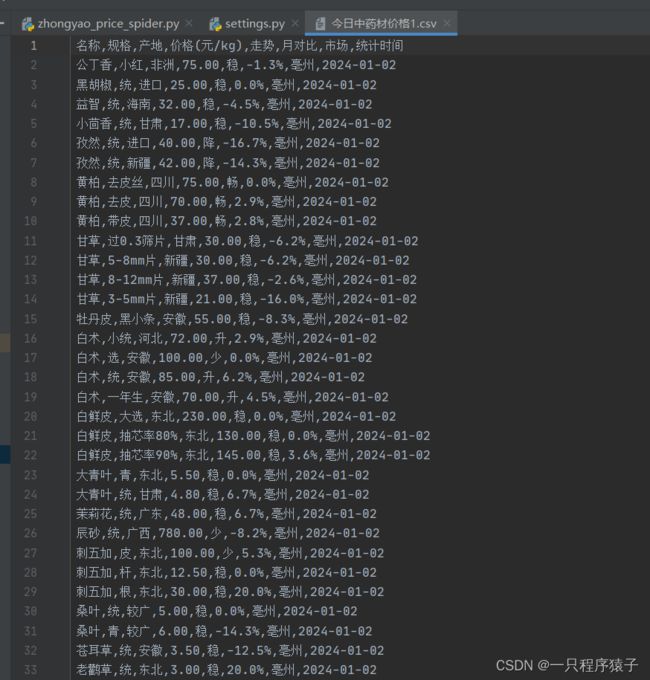
这么一套操作下来,数据就被保存到本地了!打完收工!