Pytorch:多块GPU分布式|并行训练
分布式与并行训练的区别
- 分布式:
多台服务器上的多个GPU,分布式涉及了服务器之间的通信,因此比较复杂,PyTorch封装了相应的接口,可以用几句简单的代码实现分布式训练。 - 并行:
一台服务器上的多个GPU
多GPU训练
可以分为model parallel(模型并行)和data parallel(数据并行)
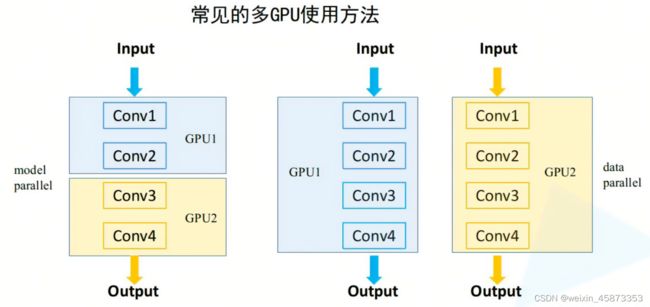
- model parallel
由于模型太大了,单块GPU跑不起来,因此需要将一个模型分到不同的GPU上。没有加速训练的作用。 - data parallel
将数据分到不同的GPU上,可以加速训练
多GPU并行训练时会涉及到多GPU之间的通信问题,因此训练时间不是线性递减的。
在Pytorch实现多GPU训练
Pytorch提供了两种多GPU的训练,DataParallel和DistributedDataParallel
-
DataParallel:
早期方法,仅能实现单机多卡,只有一个进程,master节点相当于参数服务器,向其他服务器广播参数,梯度正向传播后,各GPU将梯度的数值传回到master节点上,master节点对搜集来的梯度进行计算后更新参数,再广播出去更新后的参数。这种方式使得master节点计算任务重,阻塞网络,训练速度不是很高
相比于单机单卡仅需要增加一行代码
#创建模型 model = models.resnet101() #模型拷贝 model = torch.nn.DataParallel(model.cuda(), device_ids = [0,1,2,3]) -
DistributedDataParallel:
推荐方法,可以实现单机多卡、多机多卡,而且速度更快
具体实现步骤
以下仅实现单机多卡
1 启动方式
torch.distributed.launch
2 传入参数
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int, help='node rank for distributed training')
parser.add_argument("--gpu_id", type=str, default='0,1,2,3,4,5', help='path log files')
args = parser.parse_args()
os.environ["CUDA_DEVICE_ORDER"] = 'PCI_BUS_ID'
os.environ["CUDA_VISIBLE_DEVICES"] = opt.gpu_id
3 初始化进程
torch.distributed.init_process_group("nccl",world_size=n_gpu,rank=args.local_rank) # 第一参数nccl为GPU通信方式, world_size为当前机器GPU个数,rank为当前进程在哪个PGU上
4 设置进程使用的卡
torch.cuda.set_device(args.local_rank)
5 对模型进行包裹
model=torch.nn.DistributedDataParallel(model.cuda(args.local_rank), device_ids=[args.local_rank]),#这里device_ids传入一张卡即可,因为是多进程多卡,一个进程一个卡
6 将数据分配到不同的GPU上
train_sampler = torch.util.data.distributed.DistributedSampler(train_dataset) # train_dataset为Dataset()
将train_sampler传入到DataLoader中,不需要传入shuffle=True,因为shuffle和sampler互斥 data_dataloader = DataLoader(…, sampler=train_sampler)
整体代码示例
# main.py
import torch
import argparse
import torch.distributed as dist
#(1)要使用`torch.distributed`,你需要在你的`main.py(也就是你的主py脚本)`中的主函数中加入一个**参数接口:`--local_rank`**
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=-1, type=int,
help='node rank for distributed training')
args = parser.parse_args()
#(2)使用 init_process_group 设置GPU 之间通信使用的后端和端口:
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
#(3)使用 DistributedSampler 对数据集进行划分:
train_dataset = ...
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
#(4)使用 DistributedDataParallel 包装模型
model = ...
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
optimizer = optim.SGD(model.parameters())
for epoch in range(100):
for batch_idx, (data, target) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
...
output = model(images)
loss = criterion(output, target)
...
optimizer.zero_grad()
loss.backward()
optimizer.step()
运行命令
python -m torch.distributed.launch main.py --model_name BPRMF --emb_size 64 --lr 1e-3 --l2 1e-6 --dataset Grocery_and_Gourmet_Food
参考文章
pytorch多GPU分布式训练代码编写
Pytorch中多GPU并行计算教程