文章目录
- pandas基本介绍
- pandas 选择数据
-
- select by label:loc 纯标签筛选
- select by position:iloc 纯位置筛选
- mixed selection:ix 既有标签又有位置筛选
- Boolean indexing
- pandas设置值
- pandas处理丢失数据
- pandas导入导出数据
- pandas合并DataFrame
-
- 1.concatenating
-
- join,['inner','outer']
- join_axes
- 2.append合并
- 3.merge合并
-
- consider two keys
- indicator
- index
- pandas:数据可视化
pandas基本介绍
import pandas as pd
import numpy as np
s = pd.Series([1,3,6,np.nan,44,1])
s
0 1.0
1 3.0
2 6.0
3 NaN
4 44.0
5 1.0
dtype: float64
dates = pd.date_range('20160101',periods=6)
dates
DatetimeIndex(['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2016-01-06'],
dtype='datetime64[ns]', freq='D')
df = pd.DataFrame(np.random.randn(6,4),index=dates)
df
|
0 |
1 |
2 |
3 |
| 2016-01-01 |
0.310279 |
-0.113450 |
1.453515 |
0.893409 |
| 2016-01-02 |
0.511068 |
-0.088535 |
-1.751460 |
0.390180 |
| 2016-01-03 |
0.415210 |
0.352752 |
0.431860 |
0.225930 |
| 2016-01-04 |
0.649793 |
0.743668 |
1.250057 |
1.396353 |
| 2016-01-05 |
1.145737 |
0.338144 |
1.077738 |
0.856458 |
| 2016-01-06 |
0.037643 |
1.375382 |
1.560754 |
-0.435449 |
df = pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d'])
df
|
a |
b |
c |
d |
| 2016-01-01 |
1.117627 |
-0.796587 |
0.041202 |
-0.772693 |
| 2016-01-02 |
-0.987977 |
-1.525442 |
-0.684378 |
0.007355 |
| 2016-01-03 |
-0.255173 |
-1.444724 |
0.599456 |
1.050332 |
| 2016-01-04 |
-0.020769 |
-0.354652 |
-1.111232 |
1.217364 |
| 2016-01-05 |
-1.114441 |
-0.069303 |
0.473385 |
0.425665 |
| 2016-01-06 |
1.157257 |
-0.081045 |
0.973594 |
1.198853 |
df1 = pd.DataFrame(np.arange(12).reshape(3,4))
df1
|
0 |
1 |
2 |
3 |
| 0 |
0 |
1 |
2 |
3 |
| 1 |
4 |
5 |
6 |
7 |
| 2 |
8 |
9 |
10 |
11 |
df2 = pd.DataFrame({'A':1.,
'B':pd.Timestamp('20230102'),
'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype='int32'),
'E':pd.Categorical(['test','train','test','train']),
'F':'foo'})
df2
|
A |
B |
C |
D |
E |
F |
| 0 |
1.0 |
2023-01-02 |
1.0 |
3 |
test |
foo |
| 1 |
1.0 |
2023-01-02 |
1.0 |
3 |
train |
foo |
| 2 |
1.0 |
2023-01-02 |
1.0 |
3 |
test |
foo |
| 3 |
1.0 |
2023-01-02 |
1.0 |
3 |
train |
foo |
df2.dtypes
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
df2.index
Int64Index([0, 1, 2, 3], dtype='int64')
df2.columns
Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
df2.values
array([[1.0, Timestamp('2023-01-02 00:00:00'), 1.0, 3, 'test', 'foo'],
[1.0, Timestamp('2023-01-02 00:00:00'), 1.0, 3, 'train', 'foo'],
[1.0, Timestamp('2023-01-02 00:00:00'), 1.0, 3, 'test', 'foo'],
[1.0, Timestamp('2023-01-02 00:00:00'), 1.0, 3, 'train', 'foo']],
dtype=object)
df2.describe()
|
A |
C |
D |
| count |
4.0 |
4.0 |
4.0 |
| mean |
1.0 |
1.0 |
3.0 |
| std |
0.0 |
0.0 |
0.0 |
| min |
1.0 |
1.0 |
3.0 |
| 25% |
1.0 |
1.0 |
3.0 |
| 50% |
1.0 |
1.0 |
3.0 |
| 75% |
1.0 |
1.0 |
3.0 |
| max |
1.0 |
1.0 |
3.0 |
df2.T
|
0 |
1 |
2 |
3 |
| A |
1.0 |
1.0 |
1.0 |
1.0 |
| B |
2023-01-02 00:00:00 |
2023-01-02 00:00:00 |
2023-01-02 00:00:00 |
2023-01-02 00:00:00 |
| C |
1.0 |
1.0 |
1.0 |
1.0 |
| D |
3 |
3 |
3 |
3 |
| E |
test |
train |
test |
train |
| F |
foo |
foo |
foo |
foo |
df2.sort_index(axis=1,ascending=False)
|
F |
E |
D |
C |
B |
A |
| 0 |
foo |
test |
3 |
1.0 |
2023-01-02 |
1.0 |
| 1 |
foo |
train |
3 |
1.0 |
2023-01-02 |
1.0 |
| 2 |
foo |
test |
3 |
1.0 |
2023-01-02 |
1.0 |
| 3 |
foo |
train |
3 |
1.0 |
2023-01-02 |
1.0 |
df2.sort_index(axis=0,ascending=False)
|
A |
B |
C |
D |
E |
F |
| 3 |
1.0 |
2023-01-02 |
1.0 |
3 |
train |
foo |
| 2 |
1.0 |
2023-01-02 |
1.0 |
3 |
test |
foo |
| 1 |
1.0 |
2023-01-02 |
1.0 |
3 |
train |
foo |
| 0 |
1.0 |
2023-01-02 |
1.0 |
3 |
test |
foo |
df2.sort_values(by='E')
|
A |
B |
C |
D |
E |
F |
| 0 |
1.0 |
2023-01-02 |
1.0 |
3 |
test |
foo |
| 2 |
1.0 |
2023-01-02 |
1.0 |
3 |
test |
foo |
| 1 |
1.0 |
2023-01-02 |
1.0 |
3 |
train |
foo |
| 3 |
1.0 |
2023-01-02 |
1.0 |
3 |
train |
foo |
pandas 选择数据
import pandas as pd
import numpy as np
dates = pd.date_range('20240101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df['A']
2024-01-01 0
2024-01-02 4
2024-01-03 8
2024-01-04 12
2024-01-05 16
2024-01-06 20
Freq: D, Name: A, dtype: int32
df.A
2024-01-01 0
2024-01-02 4
2024-01-03 8
2024-01-04 12
2024-01-05 16
2024-01-06 20
Freq: D, Name: A, dtype: int32
df[0:3]
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
df['20240102':'20240105']
|
A |
B |
C |
D |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
select by label:loc 纯标签筛选
df.loc['20240103']
A 8
B 9
C 10
D 11
Name: 2024-01-03 00:00:00, dtype: int32
df.loc[:,['A','B']]
|
A |
B |
| 2024-01-01 |
0 |
1 |
| 2024-01-02 |
4 |
5 |
| 2024-01-03 |
8 |
9 |
| 2024-01-04 |
12 |
13 |
| 2024-01-05 |
16 |
17 |
| 2024-01-06 |
20 |
21 |
df.loc['20240102',['A','B']]
A 4
B 5
Name: 2024-01-02 00:00:00, dtype: int32
select by position:iloc 纯位置筛选
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df.iloc[3]
A 12
B 13
C 14
D 15
Name: 2024-01-04 00:00:00, dtype: int32
df.iloc[3,1]
13
df.iloc[3:5,1:3]
|
B |
C |
| 2024-01-04 |
13 |
14 |
| 2024-01-05 |
17 |
18 |
df.iloc[[1,3,5],1:3]
|
B |
C |
| 2024-01-02 |
5 |
6 |
| 2024-01-04 |
13 |
14 |
| 2024-01-06 |
21 |
22 |
mixed selection:ix 既有标签又有位置筛选
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df.ix[:3,['A','C']]
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[64], line 1
----> 1 df.ix[:3,['A','C']]
File D:\ProgramData\anaconda3\Lib\site-packages\pandas\core\generic.py:5902, in NDFrame.__getattr__(self, name)
5895 if (
5896 name not in self._internal_names_set
5897 and name not in self._metadata
5898 and name not in self._accessors
5899 and self._info_axis._can_hold_identifiers_and_holds_name(name)
5900 ):
5901 return self[name]
-> 5902 return object.__getattribute__(self, name)
AttributeError: 'DataFrame' object has no attribute 'ix'
Boolean indexing
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df[df.A>8]
|
A |
B |
C |
D |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
pandas设置值
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df.iloc[2,2]=1111
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
1111 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df.loc['20240102','C']=2222
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
2222 |
7 |
| 2024-01-03 |
8 |
9 |
1111 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df[df.A>4]=0
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
2222 |
7 |
| 2024-01-03 |
0 |
0 |
0 |
0 |
| 2024-01-04 |
0 |
0 |
0 |
0 |
| 2024-01-05 |
0 |
0 |
0 |
0 |
| 2024-01-06 |
0 |
0 |
0 |
0 |
dates = pd.date_range('20240101',periods=6)
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df.A[df.A>4]=0
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
0 |
9 |
10 |
11 |
| 2024-01-04 |
0 |
13 |
14 |
15 |
| 2024-01-05 |
0 |
17 |
18 |
19 |
| 2024-01-06 |
0 |
21 |
22 |
23 |
dates = pd.date_range('20240101',periods=6)
dates
DatetimeIndex(['2024-01-01', '2024-01-02', '2024-01-03', '2024-01-04',
'2024-01-05', '2024-01-06'],
dtype='datetime64[ns]', freq='D')
df = pd.DataFrame(np.arange(24).reshape(6,4),index=dates,columns=['A','B','C','D'])
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df.B[df.A>2]=0
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
0 |
6 |
7 |
| 2024-01-03 |
8 |
0 |
10 |
11 |
| 2024-01-04 |
12 |
0 |
14 |
15 |
| 2024-01-05 |
16 |
0 |
18 |
19 |
| 2024-01-06 |
20 |
0 |
22 |
23 |
df['F']=np.nan
df
|
A |
B |
C |
D |
E |
F |
| 2024-01-01 |
0 |
1 |
2 |
3 |
1 |
NaN |
| 2024-01-02 |
4 |
5 |
6 |
7 |
2 |
NaN |
| 2024-01-03 |
8 |
9 |
10 |
11 |
3 |
NaN |
| 2024-01-04 |
12 |
13 |
14 |
15 |
4 |
NaN |
| 2024-01-05 |
16 |
17 |
18 |
19 |
5 |
NaN |
| 2024-01-06 |
20 |
21 |
22 |
23 |
6 |
NaN |
df['E']=pd.Series([1,2,3,4,5,6],index=pd.date_range('20240101',periods=6))
df
|
A |
B |
C |
D |
E |
F |
| 2024-01-01 |
0 |
1 |
2 |
3 |
1 |
NaN |
| 2024-01-02 |
4 |
5 |
6 |
7 |
2 |
NaN |
| 2024-01-03 |
8 |
9 |
10 |
11 |
3 |
NaN |
| 2024-01-04 |
12 |
13 |
14 |
15 |
4 |
NaN |
| 2024-01-05 |
16 |
17 |
18 |
19 |
5 |
NaN |
| 2024-01-06 |
20 |
21 |
22 |
23 |
6 |
NaN |
df['E']=pd.Series([1,2,3,4,5,6],index=df.index)
df
|
A |
B |
C |
D |
E |
F |
| 2024-01-01 |
0 |
1 |
2 |
3 |
1 |
NaN |
| 2024-01-02 |
4 |
5 |
6 |
7 |
2 |
NaN |
| 2024-01-03 |
8 |
9 |
10 |
11 |
3 |
NaN |
| 2024-01-04 |
12 |
13 |
14 |
15 |
4 |
NaN |
| 2024-01-05 |
16 |
17 |
18 |
19 |
5 |
NaN |
| 2024-01-06 |
20 |
21 |
22 |
23 |
6 |
NaN |
pandas处理丢失数据
import pandas as pd
import numpy as np
dates = pd.date_range('20240101',periods=6)
dates
DatetimeIndex(['2024-01-01', '2024-01-02', '2024-01-03', '2024-01-04',
'2024-01-05', '2024-01-06'],
dtype='datetime64[ns]', freq='D')
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
1 |
2 |
3 |
| 2024-01-02 |
4 |
5 |
6 |
7 |
| 2024-01-03 |
8 |
9 |
10 |
11 |
| 2024-01-04 |
12 |
13 |
14 |
15 |
| 2024-01-05 |
16 |
17 |
18 |
19 |
| 2024-01-06 |
20 |
21 |
22 |
23 |
df.iloc[0,1]=np.nan
df.iloc[1,2]=np.nan
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
NaN |
2.0 |
3 |
| 2024-01-02 |
4 |
5.0 |
NaN |
7 |
| 2024-01-03 |
8 |
9.0 |
10.0 |
11 |
| 2024-01-04 |
12 |
13.0 |
14.0 |
15 |
| 2024-01-05 |
16 |
17.0 |
18.0 |
19 |
| 2024-01-06 |
20 |
21.0 |
22.0 |
23 |
df.dropna(axis=0,how='any')
|
A |
B |
C |
D |
| 2024-01-03 |
8 |
9.0 |
10.0 |
11 |
| 2024-01-04 |
12 |
13.0 |
14.0 |
15 |
| 2024-01-05 |
16 |
17.0 |
18.0 |
19 |
| 2024-01-06 |
20 |
21.0 |
22.0 |
23 |
df.dropna(axis=1,how='any')
|
A |
D |
| 2024-01-01 |
0 |
3 |
| 2024-01-02 |
4 |
7 |
| 2024-01-03 |
8 |
11 |
| 2024-01-04 |
12 |
15 |
| 2024-01-05 |
16 |
19 |
| 2024-01-06 |
20 |
23 |
df
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
NaN |
2.0 |
3 |
| 2024-01-02 |
4 |
5.0 |
NaN |
7 |
| 2024-01-03 |
8 |
9.0 |
10.0 |
11 |
| 2024-01-04 |
12 |
13.0 |
14.0 |
15 |
| 2024-01-05 |
16 |
17.0 |
18.0 |
19 |
| 2024-01-06 |
20 |
21.0 |
22.0 |
23 |
df.fillna(value=0)
|
A |
B |
C |
D |
| 2024-01-01 |
0 |
0.0 |
2.0 |
3 |
| 2024-01-02 |
4 |
5.0 |
0.0 |
7 |
| 2024-01-03 |
8 |
9.0 |
10.0 |
11 |
| 2024-01-04 |
12 |
13.0 |
14.0 |
15 |
| 2024-01-05 |
16 |
17.0 |
18.0 |
19 |
| 2024-01-06 |
20 |
21.0 |
22.0 |
23 |
df.isnull()
|
A |
B |
C |
D |
| 2024-01-01 |
False |
True |
False |
False |
| 2024-01-02 |
False |
False |
True |
False |
| 2024-01-03 |
False |
False |
False |
False |
| 2024-01-04 |
False |
False |
False |
False |
| 2024-01-05 |
False |
False |
False |
False |
| 2024-01-06 |
False |
False |
False |
False |
np.any(df.isnull()) == True
True
pandas导入导出数据
import pandas as pd
data = pd.read_csv('C:/Users/43160/Desktop/肝代码/Python/数据分析/实验数据/Advertising.csv')
data
|
Number |
TV |
radio |
newspaper |
sales |
| 0 |
1 |
230.1 |
37.8 |
69.2 |
22.1 |
| 1 |
2 |
44.5 |
39.3 |
45.1 |
10.4 |
| 2 |
3 |
17.2 |
45.9 |
69.3 |
9.3 |
| 3 |
4 |
151.5 |
41.3 |
58.5 |
18.5 |
| 4 |
5 |
180.8 |
10.8 |
58.4 |
12.9 |
| ... |
... |
... |
... |
... |
... |
| 195 |
196 |
38.2 |
3.7 |
13.8 |
7.6 |
| 196 |
197 |
94.2 |
4.9 |
8.1 |
9.7 |
| 197 |
198 |
177.0 |
9.3 |
6.4 |
12.8 |
| 198 |
199 |
283.6 |
42.0 |
66.2 |
25.5 |
| 199 |
200 |
232.1 |
8.6 |
8.7 |
13.4 |
200 rows × 5 columns
data.to_csv('advertising.csv')
pandas合并DataFrame
1.concatenating
import pandas as pd
import numpy as np
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
df1
|
a |
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
0.0 |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
df2
|
a |
b |
c |
d |
| 0 |
1.0 |
1.0 |
1.0 |
1.0 |
| 1 |
1.0 |
1.0 |
1.0 |
1.0 |
| 2 |
1.0 |
1.0 |
1.0 |
1.0 |
df3
|
a |
b |
c |
d |
| 0 |
2.0 |
2.0 |
2.0 |
2.0 |
| 1 |
2.0 |
2.0 |
2.0 |
2.0 |
| 2 |
2.0 |
2.0 |
2.0 |
2.0 |
res = pd.concat([df1,df2,df3],axis=0)
res
|
a |
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
0.0 |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
| 0 |
1.0 |
1.0 |
1.0 |
1.0 |
| 1 |
1.0 |
1.0 |
1.0 |
1.0 |
| 2 |
1.0 |
1.0 |
1.0 |
1.0 |
| 0 |
2.0 |
2.0 |
2.0 |
2.0 |
| 1 |
2.0 |
2.0 |
2.0 |
2.0 |
| 2 |
2.0 |
2.0 |
2.0 |
2.0 |
res = pd.concat([df1,df2,df3],axis=0,ignore_index=True)
res
|
a |
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
0.0 |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
| 3 |
1.0 |
1.0 |
1.0 |
1.0 |
| 4 |
1.0 |
1.0 |
1.0 |
1.0 |
| 5 |
1.0 |
1.0 |
1.0 |
1.0 |
| 6 |
2.0 |
2.0 |
2.0 |
2.0 |
| 7 |
2.0 |
2.0 |
2.0 |
2.0 |
| 8 |
2.0 |
2.0 |
2.0 |
2.0 |
res = pd.concat([df1,df2,df3],axis=1)
res
|
a |
b |
c |
d |
a |
b |
c |
d |
a |
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
0.0 |
1.0 |
1.0 |
1.0 |
1.0 |
2.0 |
2.0 |
2.0 |
2.0 |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
1.0 |
1.0 |
1.0 |
1.0 |
2.0 |
2.0 |
2.0 |
2.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
1.0 |
1.0 |
1.0 |
1.0 |
2.0 |
2.0 |
2.0 |
2.0 |
join,[‘inner’,‘outer’]
df1 = pd.DataFrame(np.ones((3,4))*0,index=[1,2,3],columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,index=[2,3,4],columns=['b','c','d','e'])
df1
|
a |
b |
c |
d |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
| 3 |
0.0 |
0.0 |
0.0 |
0.0 |
df2
|
b |
c |
d |
e |
| 2 |
1.0 |
1.0 |
1.0 |
1.0 |
| 3 |
1.0 |
1.0 |
1.0 |
1.0 |
| 4 |
1.0 |
1.0 |
1.0 |
1.0 |
res = pd.concat([df1,df2])
res
|
a |
b |
c |
d |
e |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
NaN |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
NaN |
| 3 |
0.0 |
0.0 |
0.0 |
0.0 |
NaN |
| 2 |
NaN |
1.0 |
1.0 |
1.0 |
1.0 |
| 3 |
NaN |
1.0 |
1.0 |
1.0 |
1.0 |
| 4 |
NaN |
1.0 |
1.0 |
1.0 |
1.0 |
res = pd.concat([df1,df2],join='outer')
res
|
a |
b |
c |
d |
e |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
NaN |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
NaN |
| 3 |
0.0 |
0.0 |
0.0 |
0.0 |
NaN |
| 2 |
NaN |
1.0 |
1.0 |
1.0 |
1.0 |
| 3 |
NaN |
1.0 |
1.0 |
1.0 |
1.0 |
| 4 |
NaN |
1.0 |
1.0 |
1.0 |
1.0 |
res = pd.concat([df1,df2],join='inner')
res
|
b |
c |
d |
| 1 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
| 3 |
0.0 |
0.0 |
0.0 |
| 2 |
1.0 |
1.0 |
1.0 |
| 3 |
1.0 |
1.0 |
1.0 |
| 4 |
1.0 |
1.0 |
1.0 |
res = pd.concat([df1,df2],join='inner',ignore_index=True)
res
|
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
| 1 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
| 3 |
1.0 |
1.0 |
1.0 |
| 4 |
1.0 |
1.0 |
1.0 |
| 5 |
1.0 |
1.0 |
1.0 |
join_axes
df1
|
a |
b |
c |
d |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
| 3 |
0.0 |
0.0 |
0.0 |
0.0 |
df2
|
b |
c |
d |
e |
| 2 |
1.0 |
1.0 |
1.0 |
1.0 |
| 3 |
1.0 |
1.0 |
1.0 |
1.0 |
| 4 |
1.0 |
1.0 |
1.0 |
1.0 |
res = pd.concat([df1,df2],axis=1)
res
|
a |
b |
c |
d |
b |
c |
d |
e |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
NaN |
NaN |
NaN |
NaN |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
1.0 |
1.0 |
1.0 |
1.0 |
| 3 |
0.0 |
0.0 |
0.0 |
0.0 |
1.0 |
1.0 |
1.0 |
1.0 |
| 4 |
NaN |
NaN |
NaN |
NaN |
1.0 |
1.0 |
1.0 |
1.0 |
res = pd.concat([df1,df2],axis=1,join_axes=[df1.index])
res
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[161], line 1
----> 1 res = pd.concat([df1,df2],axis=1,join_axes=[df1.index]) # 考虑df1的索引,但是已在anaconda中去除
2 res
File D:\ProgramData\anaconda3\Lib\site-packages\pandas\util\_decorators.py:331, in deprecate_nonkeyword_arguments..decorate..wrapper(*args, **kwargs)
325 if len(args) > num_allow_args:
326 warnings.warn(
327 msg.format(arguments=_format_argument_list(allow_args)),
328 FutureWarning,
329 stacklevel=find_stack_level(),
330 )
--> 331 return func(*args, **kwargs)
TypeError: concat() got an unexpected keyword argument 'join_axes'
2.append合并
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df1
|
a |
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
0.0 |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
df2
|
a |
b |
c |
d |
| 0 |
1.0 |
1.0 |
1.0 |
1.0 |
| 1 |
1.0 |
1.0 |
1.0 |
1.0 |
| 2 |
1.0 |
1.0 |
1.0 |
1.0 |
res = df1.append(df2,ignore_index=True)
res
C:\Users\43160\AppData\Local\Temp\ipykernel_15804\3917667868.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
res = df1.append(df2,ignore_index=True)
|
a |
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
0.0 |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
| 3 |
1.0 |
1.0 |
1.0 |
1.0 |
| 4 |
1.0 |
1.0 |
1.0 |
1.0 |
| 5 |
1.0 |
1.0 |
1.0 |
1.0 |
df3 = pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
res = df1.append([df2,df3],ignore_index=True)
res
C:\Users\43160\AppData\Local\Temp\ipykernel_15804\3744420715.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
res = df1.append([df2,df3],ignore_index=True)
|
a |
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
0.0 |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
| 3 |
1.0 |
1.0 |
1.0 |
1.0 |
| 4 |
1.0 |
1.0 |
1.0 |
1.0 |
| 5 |
1.0 |
1.0 |
1.0 |
1.0 |
| 6 |
1.0 |
1.0 |
1.0 |
1.0 |
| 7 |
1.0 |
1.0 |
1.0 |
1.0 |
| 8 |
1.0 |
1.0 |
1.0 |
1.0 |
res = df1.append([df2,df3])
res
C:\Users\43160\AppData\Local\Temp\ipykernel_15804\1214992729.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
res = df1.append([df2,df3])
|
a |
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
0.0 |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
| 0 |
1.0 |
1.0 |
1.0 |
1.0 |
| 1 |
1.0 |
1.0 |
1.0 |
1.0 |
| 2 |
1.0 |
1.0 |
1.0 |
1.0 |
| 0 |
1.0 |
1.0 |
1.0 |
1.0 |
| 1 |
1.0 |
1.0 |
1.0 |
1.0 |
| 2 |
1.0 |
1.0 |
1.0 |
1.0 |
df1 = pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
s1 = pd.Series([1,2,3,4],index=['a','b','c','d'])
s1
a 1
b 2
c 3
d 4
dtype: int64
res = df1.append(s1,ignore_index=True)
res
C:\Users\43160\AppData\Local\Temp\ipykernel_15804\2713288841.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
res = df1.append(s1,ignore_index=True)
|
a |
b |
c |
d |
| 0 |
0.0 |
0.0 |
0.0 |
0.0 |
| 1 |
0.0 |
0.0 |
0.0 |
0.0 |
| 2 |
0.0 |
0.0 |
0.0 |
0.0 |
| 3 |
1.0 |
2.0 |
3.0 |
4.0 |
3.merge合并
import pandas as pd
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
right
|
key |
C |
D |
| 0 |
K0 |
C0 |
D0 |
| 1 |
K1 |
C1 |
D1 |
| 2 |
K2 |
C2 |
D2 |
| 3 |
K3 |
C3 |
D3 |
left
|
key |
A |
B |
| 0 |
K0 |
A0 |
B0 |
| 1 |
K1 |
A1 |
B1 |
| 2 |
K2 |
A2 |
B2 |
| 3 |
K3 |
A3 |
B3 |
res = pd.merge(left,right,on='key')
res
|
key |
A |
B |
C |
D |
| 0 |
K0 |
A0 |
B0 |
C0 |
D0 |
| 1 |
K1 |
A1 |
B1 |
C1 |
D1 |
| 2 |
K2 |
A2 |
B2 |
C2 |
D2 |
| 3 |
K3 |
A3 |
B3 |
C3 |
D3 |
consider two keys
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
left
|
key1 |
key2 |
A |
B |
| 0 |
K0 |
K0 |
A0 |
B0 |
| 1 |
K0 |
K1 |
A1 |
B1 |
| 2 |
K1 |
K0 |
A2 |
B2 |
| 3 |
K2 |
K1 |
A3 |
B3 |
right
|
key1 |
key2 |
C |
D |
| 0 |
K0 |
K0 |
C0 |
D0 |
| 1 |
K1 |
K0 |
C1 |
D1 |
| 2 |
K1 |
K0 |
C2 |
D2 |
| 3 |
K2 |
K0 |
C3 |
D3 |
res = pd.merge(left,right,on=['key1','key2'])
res
|
key1 |
key2 |
A |
B |
C |
D |
| 0 |
K0 |
K0 |
A0 |
B0 |
C0 |
D0 |
| 1 |
K1 |
K0 |
A2 |
B2 |
C1 |
D1 |
| 2 |
K1 |
K0 |
A2 |
B2 |
C2 |
D2 |
res = pd.merge(left,right,on=['key1','key2'],how='inner')
res
|
key1 |
key2 |
A |
B |
C |
D |
| 0 |
K0 |
K0 |
A0 |
B0 |
C0 |
D0 |
| 1 |
K1 |
K0 |
A2 |
B2 |
C1 |
D1 |
| 2 |
K1 |
K0 |
A2 |
B2 |
C2 |
D2 |
res = pd.merge(left,right,on=['key1','key2'],how='outer')
res
|
key1 |
key2 |
A |
B |
C |
D |
| 0 |
K0 |
K0 |
A0 |
B0 |
C0 |
D0 |
| 1 |
K0 |
K1 |
A1 |
B1 |
NaN |
NaN |
| 2 |
K1 |
K0 |
A2 |
B2 |
C1 |
D1 |
| 3 |
K1 |
K0 |
A2 |
B2 |
C2 |
D2 |
| 4 |
K2 |
K1 |
A3 |
B3 |
NaN |
NaN |
| 5 |
K2 |
K0 |
NaN |
NaN |
C3 |
D3 |
left
|
key1 |
key2 |
A |
B |
| 0 |
K0 |
K0 |
A0 |
B0 |
| 1 |
K0 |
K1 |
A1 |
B1 |
| 2 |
K1 |
K0 |
A2 |
B2 |
| 3 |
K2 |
K1 |
A3 |
B3 |
right
|
key1 |
key2 |
C |
D |
| 0 |
K0 |
K0 |
C0 |
D0 |
| 1 |
K1 |
K0 |
C1 |
D1 |
| 2 |
K1 |
K0 |
C2 |
D2 |
| 3 |
K2 |
K0 |
C3 |
D3 |
res = pd.merge(left,right,on=['key1','key2'],how='left')
res
|
key1 |
key2 |
A |
B |
C |
D |
| 0 |
K0 |
K0 |
A0 |
B0 |
C0 |
D0 |
| 1 |
K0 |
K1 |
A1 |
B1 |
NaN |
NaN |
| 2 |
K1 |
K0 |
A2 |
B2 |
C1 |
D1 |
| 3 |
K1 |
K0 |
A2 |
B2 |
C2 |
D2 |
| 4 |
K2 |
K1 |
A3 |
B3 |
NaN |
NaN |
res = pd.merge(left,right,on=['key1','key2'],how='right')
res
|
key1 |
key2 |
A |
B |
C |
D |
| 0 |
K0 |
K0 |
A0 |
B0 |
C0 |
D0 |
| 1 |
K1 |
K0 |
A2 |
B2 |
C1 |
D1 |
| 2 |
K1 |
K0 |
A2 |
B2 |
C2 |
D2 |
| 3 |
K2 |
K0 |
NaN |
NaN |
C3 |
D3 |
indicator
df1 = pd.DataFrame({'col1':[0,1], 'col_left':['a','b']})
df2 = pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]})
df1
|
col1 |
col_left |
| 0 |
0 |
a |
| 1 |
1 |
b |
df2
|
col1 |
col_right |
| 0 |
1 |
2 |
| 1 |
2 |
2 |
| 2 |
2 |
2 |
res = pd.merge(df1,df2,on='col1',how='outer',indicator=True)
res
|
col1 |
col_left |
col_right |
_merge |
| 0 |
0 |
a |
NaN |
left_only |
| 1 |
1 |
b |
2.0 |
both |
| 2 |
2 |
NaN |
2.0 |
right_only |
| 3 |
2 |
NaN |
2.0 |
right_only |
res = pd.merge(df1,df2,on='col1',how='outer',indicator='indicator_columns')
res
|
col1 |
col_left |
col_right |
indicator_columns |
| 0 |
0 |
a |
NaN |
left_only |
| 1 |
1 |
b |
2.0 |
both |
| 2 |
2 |
NaN |
2.0 |
right_only |
| 3 |
2 |
NaN |
2.0 |
right_only |
index
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
'D': ['D0', 'D2', 'D3']},
index=['K0', 'K2', 'K3'])
left
|
A |
B |
| K0 |
A0 |
B0 |
| K1 |
A1 |
B1 |
| K2 |
A2 |
B2 |
right
|
C |
D |
| K0 |
C0 |
D0 |
| K2 |
C2 |
D2 |
| K3 |
C3 |
D3 |
res = pd.merge(left, right, left_index=True, right_index=True, how='outer')
res
|
A |
B |
C |
D |
| K0 |
A0 |
B0 |
C0 |
D0 |
| K1 |
A1 |
B1 |
NaN |
NaN |
| K2 |
A2 |
B2 |
C2 |
D2 |
| K3 |
NaN |
NaN |
C3 |
D3 |
res = pd.merge(left, right, left_index=True, right_index=True, how='inner')
res
|
A |
B |
C |
D |
| K0 |
A0 |
B0 |
C0 |
D0 |
| K2 |
A2 |
B2 |
C2 |
D2 |
boys = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'age': [1, 2, 3]})
girls = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'age': [4, 5, 6]})
boys
|
k |
age |
| 0 |
K0 |
1 |
| 1 |
K1 |
2 |
| 2 |
K2 |
3 |
girls
|
k |
age |
| 0 |
K0 |
4 |
| 1 |
K0 |
5 |
| 2 |
K3 |
6 |
res = pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='inner')
res
|
k |
age_boy |
age_girl |
| 0 |
K0 |
1 |
4 |
| 1 |
K0 |
1 |
5 |
pandas:数据可视化
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.Series(np.random.randn(1000),index=np.arange(1000))
data
0 0.547677
1 -0.288794
2 0.556806
3 1.261752
4 -1.912560
...
995 0.250478
996 -1.022430
997 -1.123374
998 -0.104338
999 1.049590
Length: 1000, dtype: float64
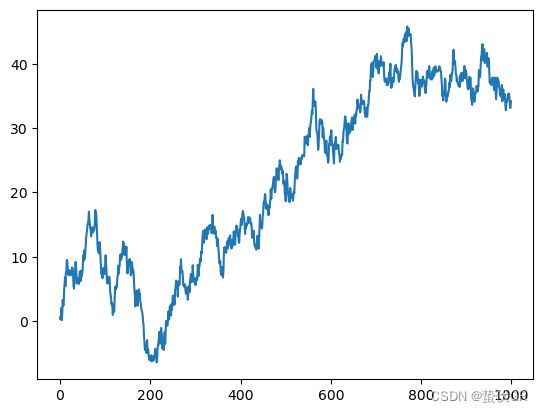
data =data.cumsum()
data.plot()
plt.show()
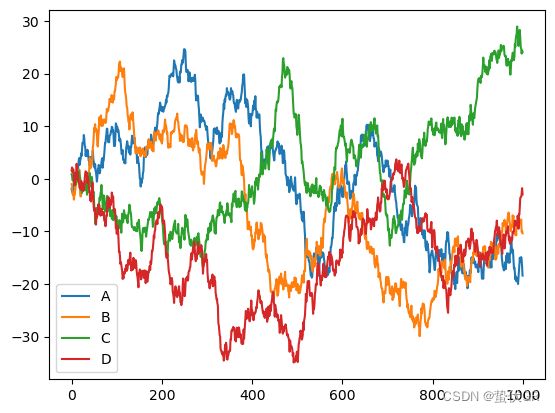
data = pd.DataFrame(np.random.randn(1000,4),
index=np.arange(1000),
columns=['A','B','C','D'])
data=data.cumsum()
data
|
A |
B |
C |
D |
| 0 |
-1.854020 |
-1.031726 |
0.873153 |
1.601868 |
| 1 |
-2.494261 |
-1.244128 |
0.510932 |
2.150016 |
| 2 |
-2.516531 |
-2.961676 |
-0.284869 |
1.238185 |
| 3 |
-1.974520 |
-3.029144 |
-0.258707 |
1.761474 |
| 4 |
-2.170233 |
-2.911106 |
0.002738 |
1.778242 |
| ... |
... |
... |
... |
... |
| 995 |
-15.542631 |
-8.357456 |
24.989268 |
-3.500648 |
| 996 |
-14.898920 |
-7.755639 |
24.748827 |
-3.434445 |
| 997 |
-15.438401 |
-10.115086 |
23.819015 |
-2.865272 |
| 998 |
-16.757351 |
-9.948964 |
24.401000 |
-1.790440 |
| 999 |
-18.415608 |
-10.377505 |
24.092952 |
-2.959285 |
1000 rows × 4 columns
data.head()
|
A |
B |
C |
D |
| 0 |
-1.854020 |
-1.031726 |
0.873153 |
1.601868 |
| 1 |
-2.494261 |
-1.244128 |
0.510932 |
2.150016 |
| 2 |
-2.516531 |
-2.961676 |
-0.284869 |
1.238185 |
| 3 |
-1.974520 |
-3.029144 |
-0.258707 |
1.761474 |
| 4 |
-2.170233 |
-2.911106 |
0.002738 |
1.778242 |
data.plot()
plt.show()
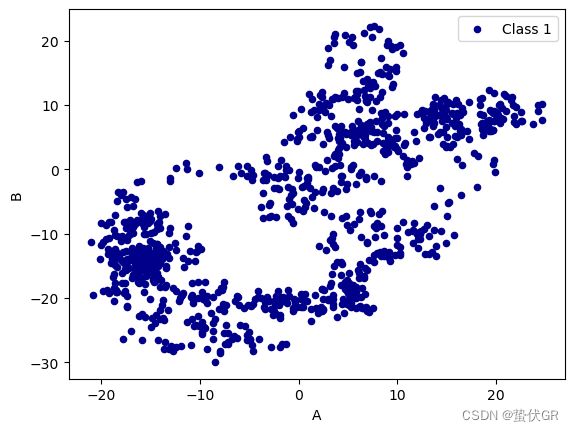
ax = data.plot.scatter(x='A', y='B', color='DarkBlue', label="Class 1")
plt.show()
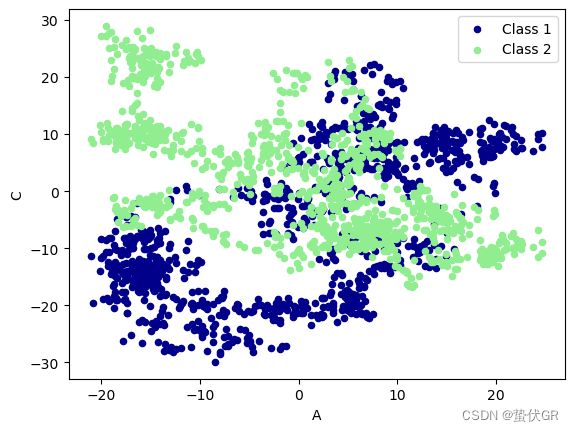
ax = data.plot.scatter(x='A', y='B', color='DarkBlue', label="Class 1")
data.plot.scatter(x='A', y='C', color='LightGreen', label='Class 2', ax=ax)
plt.show()