得物大模型平台,业务效果提升实践
一、背景
得物大模型训练与推理平台上线几个月后,我们与公司内部超过 10 个业务领域展开了全面的合作。在一些关键业务指标方面,取得了显著的成效,例如:
效率相关部门的合作,多维度打标总正确率取得 2 倍以上提升。利用大模型开辟了新的业务,提升了效率部门的人力产出。
某业务订单 NPS 的识别准确率由 70% (PROMPT 方式)提升到 85% (平台训练大模型) 。
本文基于我们与业务合作的经验,将分享如何在大模型平台上实现业务效果指标提升。我们将以大模型平台上从训练到推理部署的全链路流程为基础,提供优化思路,最终达成业务效果指标的提升。这些流程包括大模型选择、数据准备、大模型训练、效果评估和推理部署。

我们期望更多的业务方能与大模型平台合作,以实现业务效果的提升。
二、大模型如何帮助业务提升效果
大模型应用场景
大语言模型是一种基于深度学习算法的人工智能技术,可以模拟人类的语言行为,并能够从大量的文本数据中学习到语言的特征和规律。其应用场景非常广泛,以下是一些主要的应用场景:
- 自然语言处理:例如文本分类、情感分析、机器翻译等,这些应用可以帮助人们更好地理解和处理不同的语言文本,提高准确率。
- 文本生成和摘要:例如新闻报道、广告文案、科技论文摘要等,这些应用可以通过对文本内容的分析和理解,自动生成符合语法和语义规则的文本内容。
- 智能问答系统:例如智能客服、在线教育等,这些应用可以通过对问题的理解和分析,自动回答用户的问题。
- 社交媒体分析:例如情感分析、主题分类等,这些应用可以通过对社交媒体文本内容的分析和理解,提取出其中的情感、主题等信息,帮助企业了解用户的反馈和情感倾向。
此外还有一些行业大模型的应用场景,比如,法律大模型可以提供专业的法务咨询,医疗大模型可以提供医疗咨询等场景,Code 大模型可以专业去做编码等工作。
目前企业内在很多业务场景中都有对接,而且取得不错的效果,比如:智能问答,商品评论信息分析,自动化编码等场景。
接入大模型的方式
要接入大语言模型,主要有两种方式:
使用 PROMPT 工程:
通过设计具有引导性的输入提示词,可以调整大模型的状态,使其能够按照特定的方式响应新的输入数据。比如在文本生成任务中,可以设计一些特定的提示词,让大模型生成符合要求的文本。
微调训练大模型:
这是一种使用特定任务的标签数据来训练大模型的方法。首先需要准备相应的数据集,然后将预训练的大模型作为基础模型进行训练。完成训练后,可以对模型进行评估,并根据评估结果进行优化或调整。最后,将微调后的模型部署到实际应用中。
大模型训练与推理平台主要提供微调训练的方式接入大模型。经过微调训练的大模型通常在效果指标上明显优于直接使用 PROMPT 工程,这得到了我们与业务方的充分验证支持。在之前使用 PROMPT 工程接入的业务中,转向微调训练后,效果显著提升。例如,在某业务订单 NPS 的识别准确率方面,之前基于 PROMPT 与各种工程优化,准确率最多 70%,转由大模型微调训练后,可以提升到 85%。
三、基础大模型选型
基础大模型指的是各组织已经进行预训练的大模型,这些模型通常是在大规模文本数据上进行了通用性的预训练,可以作为基础模型供其他任务的微调和特定应用程序使用。
业界提供的基础大模型有哪些

业界的大模型可以分为闭源系列大模型,开源系列大模型。
闭源系列大模型通常通过 API 接口与聊天页面等方式提供大模型服务,例如 OpenAI 的 GPT 系列、Anthropic 的 Claude 系列、百度的文心一言系列等。对于闭源大模型,通常建议使用 PROMPT 提示的方式来与模型进行交互。如果需要进行微调训练以适应特定任务或领域,一般建议使用开源大模型。
开源系列的大模型是指开源了模型的参数和部分训练数据,使用户能够下载模型并进行进一步的微调训练。例如:
Llama2 系列,由 Meta 公司提供,开源了模型参数和训练论文。
Llama2 生态系列,指的是各组织在 Llama2 的基础上进行微调训练,以获得更好的效果,然后进一步将其开源。当前一些不错的开源系列包括 Vicuna 系列、XinLM 系列、WizardLM 系列、UltraLM 系列等。
国内开源系列,国内一些厂商也会自己去训练一些大模型开源,效果也不错。比如:QianWen 系列,BaiChuan 系列等等。
行业大模型系列是指一些组织基于开源大模型进行领域特定的微调训练,以在特定行业领域获得良好的效果,然后将这些模型进行开源分享。这种做法可以满足特定行业的需求,例如法律领域、金融领域、医疗领域等。这些行业大模型可以更好地适应特定领域的任务和语境,提供更准确的结果,因此在相关行业中非常有价值。
大模型的评测数据集主要有哪些
既然有这么多大模型可供选择,我们如何确定哪些模型更为出色呢?这涉及对大模型性能进行评估。通俗来说,大模型的评估是指将各种不同场景的问题提供给模型进行回答,然后根据回答的质量来评分。
评测的题目又可以分为客观题与主观题,客观题主要看回答的是否正确,主观题则需要评测回答的质量等。
下面我们介绍下一些常用的大模型评测方式。

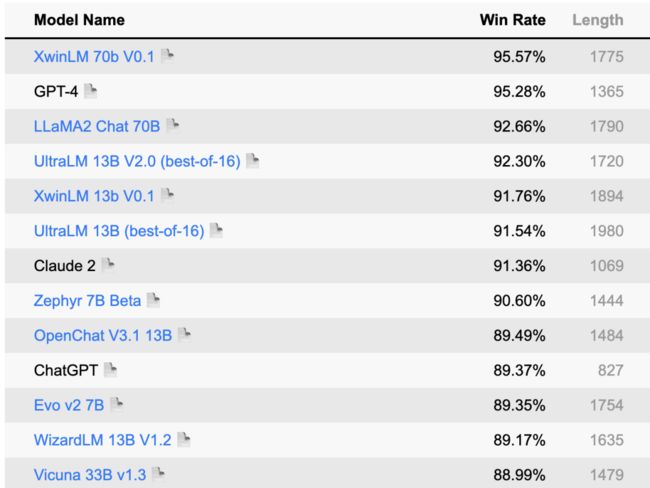
下面是最近 AlpacaEval 的大模型评分排行榜单。
如何做大模型的选型
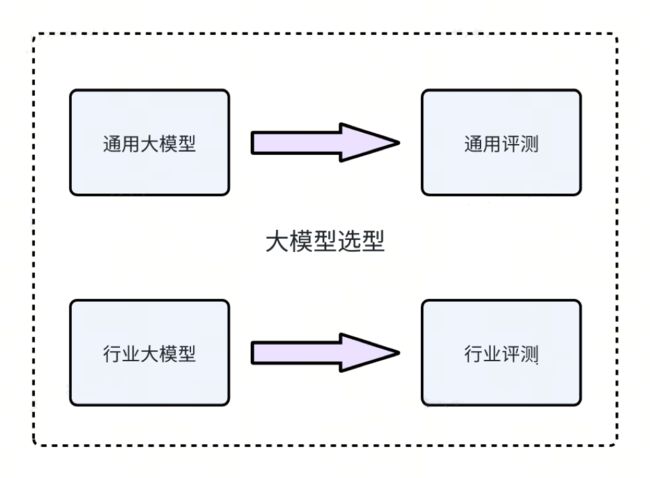
预训练的大模型的应用可以分为通用模型和行业模型。在选择基础大模型时,用户应该根据他们的具体应用场景以及各大模型的评测得分来做决策。
在通用场景,例如情感分析、机器翻译和文本摘要等,您可以选择通用大模型。可以查看一些评分排行榜,如 AlpacaEval,或其他排行榜如 MMLU、CMMLU、CEVAL 等,以了解一些性能良好的大模型。一旦选择了大模型,您也可以在大模型平台上重新运行评分以便进行进一步验证。
对于专业领域,如法务、医疗和编程等,您需要关注领域专用的大模型。例如,在编程领域,您可以查看大模型在 HuamEval 上的评分来作出选择。这将有助于确保模型在特定行业场景中的性能和适用性。
四、数据准备
大模型训练需要哪些数据
大模型的训练过程通常包括预训练、指令调优和偏好学习。在选择了预训练的大模型后,您通常只需要进行业务微调,即指令调优和偏好学习。实际上,在大多数情况下,只进行指令调优就足够了。 以 Alpaca 格式为例,指令调优的数据通常具有以下格式:
{
"instruction": "简单解释人工智能的概念。",
"input": "",
"output": "人工智能(Artificial Intelligence,简称AI)是指用计算机程序来模拟人类智能的过程。它是一种能让计算机或程序在执行任务时表现出类似人类智能的技术。人工智能包括了机器学习、自然语言处理、语音识别和计算机视觉等领埴。简言之,人工智能就是赋予计算机类似人类的思维和行为能力。"
}
在这个示例中,"instruction"表示输入的指令,"input"表示您的输入,而"output"则是由大模型生成的答复。因此,进行大模型的训练需要准备符合这种格式的指令调优数据,而这些数据应该与您的具体业务相关。
训练数据如何准备
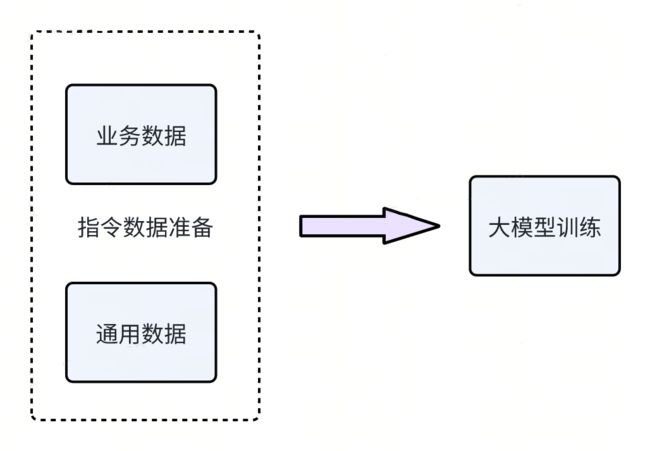
大模型的训练数据通常分为两类:通用数据和业务数据。通用数据,例如 GPT4-Cleaned 数据,主要用于提高大模型的泛化能力。另一类是业务数据,通常是业务方自己独有的数据。在训练过程中,通常会将这两种类型的数据按照一定的比例混合在一起进行训练。
此外,在数据准备过程中,强调一个非常重要的原则:数据质量将直接影响模型的效果。因此,确保数据的质量和准确性对于获得良好的模型性能至关重要。
五、大模型训练
大模型都有哪些训练方式
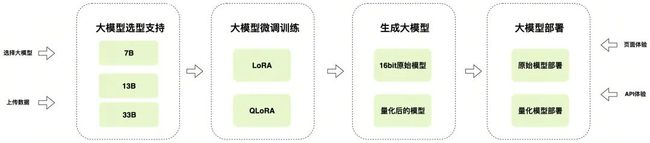
上图展示了一个完整的大模型训练过程,从大模型选择到应用于业务场景,通常包括三个阶段:
- 预训练:在这一阶段,大模型利用大量语料库进行自我学习,逐渐掌握自然语言处理的规律和技巧。这是为了建立一个通用的语言理解基础。
- 指令调优:这个阶段主要针对特定的业务场景进行训练。通过提供大量指令和相应的反馈,大模型逐渐适应并解决特定问题。这个阶段使模型更适应特定业务需求。
- 偏好学习:在大模型的训练过程中,还要考虑偏好学习,使大模型的回答更加贴近人类的偏好,遵循人类的意图。如语言风格和表达习惯等。
在前述步骤中,已经完成了基础大模型的选择,这些模型是经过预训练的。因此,在大多数情况下,您确实无需再次进行预训练。通常,您只需要准备好业务指令数据,然后进行指令调优即可,以使大模型适应和优化特定的业务场景和需求。这简化了训练流程,使其更加高效和针对性。
训练的过程
如何开启训练
![]()
在大模型平台上,用户可以按照以下步骤迅速启动大模型训练并进行自动部署:
- 选择大模型。基于之前提到的大模型选择原则,在大模型平台上选择您需要的大模型。
- 上传训练数据。按照上述数据准备方法,将您准备好的数据上传到大模型平台。
- 配置训练参数。通常情况下,选择默认配置参数,如 Lora 即可。这些参数通常经过优化以获得最佳的训练效果。
- 训练。点击相应按钮,启动训练过程。大模型平台将自动处理训练任务,以便您专注于业务应用的开发和部署。
训练结果评估

在前面的大模型选型过程中,我们介绍了如何使用通用数据集进行大模型的通用评测。类似地,一旦业务方完成了微调训练,他们需要设置业务相关的测试集,并进行与业务相关的指标评测,以确保模型在特定业务场景下的性能和效果。这个业务相关的评测是确保模型在实际应用中能够满足预期需求的关键步骤。
六、大模型部署
目前的推理加速方案有哪些
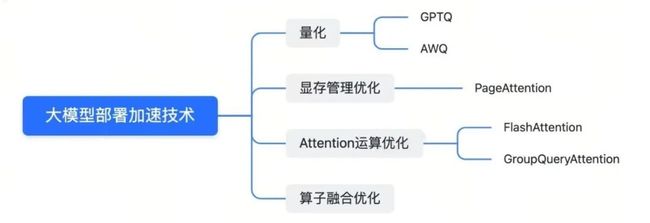
当前业界对大模型部署加速的技术如下:
- 量化:通过将模型参数量化为 8 位或 4 位,可以在保持模型效果的同时,加速推理过程,减少计算和内存开销。一些常见的量化框架包括 AWQ 和 GPTQ。
- 显存管理优化:大模型的运算通常会占用大量显存,特别是 KV Cache。通过显存管理优化,如 Page Attention 技术,可以减少显存碎片,提高显存利用率。
- Attention 运算优化:Attention 运算在计算时耗时较长,而且会导致大量的内存访问。通过结合 GPU 硬件的特点,减少内存访问和缓存,可以加速 Attention 运算。一些技术如 Flash Attention 和 Group Query Attention 可以改进 Attention 性能。
- 算子融合优化:通过合并大模型运算过程中的算子,可以减少计算和内存开销,从而提高推理速度。
一些常见的优化框架,如 AWQ(用于量化)、GPTQ(用于量化)、VLLM(包括PageAttention)、TGI(包括PageAttention和FlashAttention)、Tensorrt-llm(用于算子融合和 PageAttention)等,可以帮助加速大模型的部署,并提高性能。这些技术和框架是业界在大模型部署方面的一些关键进展。
如何选择推理加速方案
在大模型平台上,您实际上无需担心选择加速方案。这是因为平台会根据业界的技术进展和业务中所需的大模型场景进行评估,并自动为您选择当前最优的推理方案。比如 VLLM,Tensorrt-llm 等。
七、总结与展望
我们在前面的内容中详细分享了大模型的选择、数据准备、训练以及部署等方面的最新技术。未来,我们将进一步深入探讨这些技术的细节。
目前,我们已经与超过 10 个业务领域合作,涵盖了自然语言处理、文本生成、智能问答等领域,并取得了显著的业务成果。我们鼓励大家积极探索大模型平台,以提高业务效果。
由于大模型社区持续发展,未来必定会涌现出更先进的微调训练和量化部署技术。我们将密切关注这些进展,如果发现新方法在效果和性能方面优于目前支持的方法,我们将及时将其整合到平台的框架中。
*文/linggong
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!