技术学习|CDA level I 描述性统计分析(常用的数据分布)
推断性统计分析方法的基础理论——常用的分布(两点分布、二项分布、正态分布[含标准正态分布]、χ2分布、t分布、F分布。
随机试验:结果不确定的实验,例如,进行一次抛硬币实验,结果是不确定的。对于随机试验的结果,称为随机事件。用于表示随机事件的变量称为随机变量,若随机变量的取值可一一列举,则称为离散型随机变量;若不可一一列举,则称为连续性随机变量。对于多个随机事件,若其结果互不影响,则称其相互独立。
概率(Probability):用于描述随机事件发生的可能性的大小,常用符号P表示,如事件X的概率表示为P(X)。概率的取值范围为[0,1],若随机事件是必然事件,则其概率为0,若是不可能事件,则其概率为0。
离散型随机变量X的n个取值为xi(i=1,2,…,n),对应的概率为pi;连续型随机变量X的取值为x,x∈(a,b),对应的概率为f(x)。
期望(Expect):也称平均数、均值,常用于研究和概率相关的问题中,是随机变量的重要特征值,博士随机取值的集中趋势。期望的计算方法如下:①对于离散型随机变量,期望=随机变量的取值与其对应概率的乘积,再求和,即期望E(X)=∑xipi;②对于连续型随机变量,期望=随机变量的取值与其对应概率密度的乘积,再求积分,即期望E(X)=∫(a-b)xf(x)dx。
离散型随机变量 E ( x ) = ∑ x i p i ; 连续型随机变量 E ( x ) = ∫ b a x f ( x ) d x 离散型随机变量E(x)=\sum x_ip_i;连续型随机变量E(x)=\int_b^axf(x)dx 离散型随机变量E(x)=∑xipi;连续型随机变量E(x)=∫baxf(x)dx
方差(Variance):是随机变量的另一个重要特征值,表示随机事件取值的离散程度。在概率相关的问题中,方差的计算方法如下:①对于离散型随机变量,方差=随机变量的取值与其期望离差的平方的期望,即方差Var(X)=E[xi-E(x)]2;②对于连续型随机变量,方差=随机变量的取值与其期望离差的平方的期望,即方差Var(X)=E[x-E(X)]2。此外,不管是离散型随机变量还是连续型随机变量,其方差也可以通过公式Var(X)=E(X2)-[E(X)]2来计算。
离散型随机变量 V a r ( X ) = E [ x i − E ( X ) ] 2 ; 连续型随机变量 V a r ( X ) = E [ x − E ( X ) ] 2 ; 公式 V a r ( X ) = E ( X 2 ) − [ E ( X ) ] 2 离散型随机变量Var(X)=E[x_i-E(X)]^2;连续型随机变量Var(X)=E[x-E(X)]^2;公式Var(X)=E(X^2)-[E(X)]^2 离散型随机变量Var(X)=E[xi−E(X)]2;连续型随机变量Var(X)=E[x−E(X)]2;公式Var(X)=E(X2)−[E(X)]2
一、两点分布与两项分布
在推断性统计分析方法中,总体比例是需要进行推断的重要参数,总体比例的推断需要用到两点分布和二项分布。
1、两点分布
两点分布是指只有两个结果的随机事件服从的分布,如抛硬币结果,满意情况。对于有多个结果的随机事件,可以通过构建对立事件来得到两点分布(如统计学专业and非统计学专业)。即可以借用"非"、“不”、“其他"等词来构造对立事件,对于两点分布的两个结果,在一次实验中,有且仅有一个结果发生,两个结果"非此即彼”。
用X表示需要研究的随机事件,其中X=1表示需要研究的结果,概率为p;X=0表示结果的对立面,概率为1-p。
两点分布用符号表示为X~B(1,p)
期望 E ( X ) = p ; 方差 V a r ( X ) = p ( 1 − p ) 期望E(X)=p;方差Var(X)=p(1-p) 期望E(X)=p;方差Var(X)=p(1−p)
2、二项分布
二项分布也称伯努利分布,将两点分布的实验独立重复进行多次,其结果就服从二项分布。设实验次数为n,两点分布中X=1的概率为p,则**二项分布可以记作XB(n,p)**,其中B指伯努利实验(伯努利提出的一种独立重复只有两个结果的实验)。故两点分布可以看作二项分布的特殊情况,可以看作只有一次实验的二项分布,故两点分布可以用符号记作XB(1,p)。
若两点分布中X=1的概率为p,X=0的概率为1-p,则在二项分布中,随机变量X有n+1个可能得取值结果:X=0到X=n
概率 P ( X = k ) = C n k p k ( 1 − p ) n − k ; 期望 E ( X ) = n p ; 方差 V a r ( X ) = n p ( 1 − p ) 概率P(X=k)=C_n^kp^k(1-p)^{n-k};\quad 期望E(X)=np;\quad 方差Var(X)=np(1-p) 概率P(X=k)=Cnkpk(1−p)n−k;期望E(X)=np;方差Var(X)=np(1−p)
两点分布和二项分布的应用:在比例的研究中,比例实际上是服从二项分布的。以估计全校男生比例为例,估计全校男生的比例需要全校抽取100个人进行调查,抽到的每个人要不是男生,要不就是女生,即每个人的性别均服从两点分布,故独立重复100次,抽到100个人,这100人中男生的比例就是二项分布。
二、正态分布与标准正态分布
1、正态分布
正态分布,也称常态分布、高斯分布。最早是在二项分布的渐近公式中得到,后由高斯在研究测量误差时,推到得到其概率密度函数公式。
在数据分析中,如不确定数据的分布形态,常假定数据服从正态分布。
正态分布是一个连续型分布、设随机变量X服从正态分布,其期望为μ,方差为σ2,则其概率密度函数f(x)为:
f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 , − ∞ < x < + ∞ f(x)=\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}},-\infty

X服从正态分布,记作X~N(μ,σ2)
性质:①概率密度函数在x轴上方,即f(x)>0;②正态曲线的最高点对应的x值为期望μ,它也是分布的中位数和众数;③正态分布是一个分布族,每个特定正态分布都通过期望μ和方差σ2来区分;期望μ决定曲线最高点的位置,方差σ2决定曲线的平缓程度,即宽度;④曲线f(x)相对于期望μ对称,尾端向两个方向无限延伸,且理论上永远不会与横轴相交;⑤正态曲线下的总面积(概率)等于1
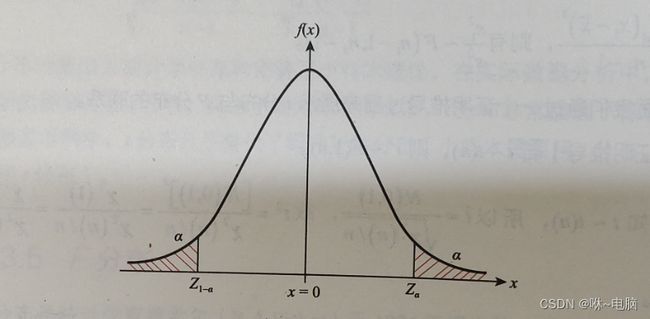
正态曲线下某两点之间的面积(概率),如P(a 正态分布的分布函数F(x)表示在正态分布N(μ,σ2),曲线中,X=x左侧的面积(概率),计算公式如下 2、标准正态分布 标准正态分布是一种重要的特殊分布,常用一些特定的表示符号来表示其概率密度函数和分布函数。标准正态分布的概率密度函数通常用符号φ(x)表示,分布函数用Φ(x)表示,普通正态分布的概率密度函数通常用f(x)表示,分布函数用F(x)表示。 标准正态分布是正态分布中最简化的正态分布,取正态分布中的期望μ=0,方差σ2=1,得到标准正态分布的概率密度函数φ(x)为 标准正态分布的函数和图像与普通正态分布有相似的性质,不同的是:①标准正态曲线的最高点对应的x值在期望0处,即标准正态分布关于x=0,也就是y轴对称;②标准正态分布是唯一的、确定的、其对称轴是确定的,宽度也是确定的。 Φ ( x ) = P ( X ≤ x ) = ∫ − ∞ x ϕ ( t ) d t = ∫ − ∞ x 1 2 π e − t 2 2 d t \Phi(x)=P(X\leq x)=\int^x_{-\infty}\phi(t)dt=\int^x_{-\infty}\frac{1}{\sqrt{2\pi}}e^{-\frac{t^2}{2}}dt Φ(x)=P(X≤x)=∫−∞xϕ(t)dt=∫−∞x2π1e−2t2dt P ( X ≤ x ) = Φ ( x ) P ( x 1 < X ≤ x 2 ) = Φ ( x 2 ) − Φ ( x 1 ) P ( X > x 1 ) = 1 − P ( X ≤ x 1 ) = 1 − Φ ( x 1 ) P ( X < − x 1 ) = P ( X > x 1 ) = 1 − P ( X ≤ x 1 ) = 1 − Φ ( x 1 ) P ( ∣ X ∣ < x i ) = Φ ( x i ) − Φ ( − x i ) P(X\leq x)=\Phi(x)\\P(x_1 三、 χ 2 \chi^2 χ2分布 χ 2 \chi^2 χ2分布(卡方分布)。可以通过标准正态分布来定义 χ 2 \chi^2 χ2分布:若随机变量X1,X2,……,Xi相互独立,且都服从标准正态分布N(0,1)。则它们的平方和 Y = ∑ i = 1 n X i 2 Y=\sum^n_{i=1}X_i^2 Y=∑i=1nXi2都服从自由度为n的 χ 2 \chi^2 χ2分布,记作Y~ χ 2 ( n ) \chi^2(n) χ2(n)。 χ 2 \chi^2 χ2分布的概率密度分布图如下。 性质: 由于 χ 2 \chi^2 χ2分布是标准正态分布的平方和,故其变量值始终为正。 分布的形状取决于自由度的大小,通常为不对称的正偏分布,但随着自由度的增大逐渐趋于对称,当 n → ∞ n \to \infty n→∞时, χ 2 \chi^2 χ2分布的极限分布是正态分布。 可以证明得到, χ 2 \chi^2 χ2分布的期望 E ( χ 2 ) = n E(\chi^2)=n E(χ2)=n,方差 V a r ( χ 2 ) = 2 n Var(\chi^2)=2n Var(χ2)=2n,n是自由度。 可加性:若U和V是两个相互独立的 χ 2 \chi^2 χ2分布, U ∽ χ 2 ( n 1 ) U \backsim \chi^2(n_1) U∽χ2(n1), V ∽ χ 2 ( n 2 ) V \backsim \chi^2(n_2) V∽χ2(n2),则U+V服从自由度为 n 1 + n 2 n_1+n_2 n1+n2的 χ 2 \chi^2 χ2分布。 若 X ∽ N ( 0 , 1 ) X \backsim N(0,1) X∽N(0,1),则 χ 2 ∽ χ 2 ( 1 ) \chi^2 \backsim \chi^2(1) χ2∽χ2(1)。 若总体为正态分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2),则有 ( n − 1 ) s 2 σ 2 ∽ χ 2 ( n − 1 ) \frac{(n-1)s^2}{\sigma^2} \backsim \chi^2(n-1) σ2(n−1)s2∽χ2(n−1)。 证明:若总体为正态分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2),则有 ( n − 1 ) s 2 σ 2 ∽ χ 2 ( n − 1 ) \frac{(n-1)s^2}{\sigma^2}\backsim\chi^2(n-1) σ2(n−1)s2∽χ2(n−1)。 证:因为 s 2 = ∑ ( x i − x ˉ ) 2 n − 1 s^2=\frac{\sum(x_i-\bar x)^2}{n-1} s2=n−1∑(xi−xˉ)2,所以 ( n − 1 ) s 2 = ∑ ( x i − x ˉ ) 2 (n-1)s^2=\sum(x_i-\bar x)^2 (n−1)s2=∑(xi−xˉ)2,所以 ( n − 1 ) s 2 σ 2 = ∑ ( x i − x ˉ ) 2 σ 2 = ∑ ( x i − x ˉ σ ) 2 \frac{(n-1)s^2}{\sigma^2}=\frac{\sum(x_i-\bar x)^2}{\sigma^2}=\sum ( \frac {x_i-\bar x}{\sigma} )^2 σ2(n−1)s2=σ2∑(xi−xˉ)2=∑(σxi−xˉ)2。因为总体分布为正态分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2),所以 x i − u σ ∽ N ( 0 , 1 ) \frac{x_i-u}{\sigma}\backsim N(0,1) σxi−u∽N(0,1),则有 ∑ ( x i − μ σ 2 ) ∽ χ 2 ( n ) \sum(\frac{x_i-\mu}{\sigma}^2)\backsim \chi^2(n) ∑(σxi−μ2)∽χ2(n),用 x ˉ \bar x xˉ替换 μ \mu μ会损失一个自由度,故有 ∑ ( x i − x ˉ σ ) 2 ∽ χ 2 ( n − 1 ) \sum(\frac{x_i-\bar x}{\sigma})^2\backsim\chi^2(n-1) ∑(σxi−xˉ)2∽χ2(n−1),所以 ( n − 1 ) s 2 σ 2 ∽ χ 2 ( n − 1 ) \frac{(n-1)s^2}{\sigma^2}\backsim\chi^2(n-1) σ2(n−1)s2∽χ2(n−1)。 χ 2 \chi^2 χ2分布是相互独立的标准正态分布的平方和,故常用于离差平方和的研究中,如方差的计算、方差的假设检验、列联分析等问题。 四、t分布 t分布也称为、学生氏分布,在研究小样本问题时,标准正态分布存在较大误差,用t分布结果更为精确。 通过标准正态分布和 χ 2 \chi^2 χ2分布来定义t分布:设 X ∽ N ( 0 , 1 ) , Y ∽ χ 2 ( n ) X \backsim N(0,1),Y \backsim \chi^2(n) X∽N(0,1),Y∽χ2(n),且X与Y相互独立,则 t = X { Y n } ∽ t ( n ) t=\frac{X}{\sqrt\{\frac{Y}{n}\}}\backsim t(n) t={nY}X∽t(n)。其分布的概率密度分布图如下。 性质: 证明:因为 x ˉ ∽ N ( μ , σ 2 n ) \bar x \backsim N(\mu,\frac{\sigma^2}{n}) xˉ∽N(μ,nσ2),所以KaTeX parse error: Undefined control sequence: \backsimN at position 34: …\sigma/\sqrt n}\̲b̲a̲c̲k̲s̲i̲m̲N̲(0,1),故 x ˉ − μ s / n = ( x ˉ − μ ) ( σ / n ) ( s / n ) σ / n = N ( 0 , 1 ) s / σ = N ( 0 , 1 ) s 2 / σ 2 = N ( 0 , 1 ) ( n − 1 ) s 2 / σ 2 n − 1 = N ( 0 , 1 ) χ 2 ( n − 1 ) n − 1 ∽ t ( n − 1 ) \frac{\bar x-\mu}{s/\sqrt n}=\frac{\frac{(\bar x-\mu)}{(\sigma/\sqrt n)}}{\frac{(s/\sqrt n)}{\sigma/\sqrt n}}=\frac{N(0,1)}{s/\sigma}=\frac{N(0,1)}{\sqrt{s^2/\sigma^2}}=\frac{N(0,1)}{\sqrt{\frac{(n-1)s^2/\sigma^2}{n-1}}}=\frac{N(0,1)}{\sqrt{\frac{\chi^2(n-1)}{n-1}}}\backsim t(n-1) s/nxˉ−μ=σ/n(s/n)(σ/n)(xˉ−μ)=s/σN(0,1)=s2/σ2N(0,1)=n−1(n−1)s2/σ2N(0,1)=n−1χ2(n−1)N(0,1)∽t(n−1)。 t分布的提出为统计学补充和完善了小样本理论,在实际数据分析中,小样本问题的研究需要用到t分布,且由于在大样本情况下,t分布非常接近标准正态分布,在很多学科中,t分布集合替代了标准正态分布(小样本需要用t分布,大样本也可以用t分布) 五、F分布 可以通过 χ 2 \chi^2 χ2分布来定义F分布:设 U ∽ χ 2 ( m ) , V ∽ χ 2 ( n ) U \backsim\chi^2(m),V \backsim \chi^2(n) U∽χ2(m),V∽χ2(n),且U和V相互独立,则 F = U / m V / n ∽ F ( m , n ) F=\frac{U/m}{V/n} \backsim F(m,n) F=V/nU/m∽F(m,n)。 F分布的概率密度分布图如下。 性质: 证明:已知 t ∽ t ( n ) t \backsim t(n) t∽t(n),所以 t = N ( 0 , 1 ) χ 2 ( n ) / n t=\frac{N(0,1)}{\sqrt{\chi^2(n)/n}} t=χ2(n)/nN(0,1),故 t 2 = [ N ( 0 , 1 ) ] 2 χ 2 ( n ) / n = χ 2 ( 1 ) χ 2 ( n ) / n = χ 2 ( 1 ) / 1 χ 2 ( n ) / n = F ( 1 , n ) t^2=\frac{[N(0,1)]^2}{\chi^2(n)/n}=\frac{\chi^2(1)}{\chi^2(n)/n}=\frac{\chi^2(1)/1}{\chi^2(n)/n}=F(1,n) t2=χ2(n)/n[N(0,1)]2=χ2(n)/nχ2(1)=χ2(n)/nχ2(1)/1=F(1,n)。 证明:因为总体为正态分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2),所以 ( n 1 − 1 ) s 1 2 σ 2 ∽ χ 2 ( n 1 − 1 ) , ( n 2 − 1 ) s 2 2 σ 2 ∽ χ 2 ( n 2 − 1 ) , 故 s 1 2 s 2 2 = ( n 1 − 1 ) s 1 2 σ 2 / ( n 1 − 1 ) ( n 2 − 1 ) s 2 2 σ 2 / ( n 2 − 1 ) = χ 2 ( n 1 − 1 ) / ( n 1 − 1 ) χ 2 ( n 2 − 1 ) / ( n 2 − 1 ) ∽ F ( n 1 − 1 , n 2 − 1 ) \frac{(n_1-1)s_1^2}{\sigma^2}\backsim \chi^2(n_1-1),\frac{(n_2-1)s^2_2}{\sigma^2}\backsim \chi^2(n_2-1),故\frac{s_1^2}{s_2^2}=\frac{\frac{(n_1-1)s_1^2}{\sigma^2}/(n_1-1)}{\frac{(n_2-1)s^2_2}{\sigma^2}/(n_2-1)}=\frac{\chi^2(n_1-1)/(n_1-1)}{\chi^2(n_2-1)/(n_2-1)}\backsim F(n_1-1,n_2-1) σ2(n1−1)s12∽χ2(n1−1),σ2(n2−1)s22∽χ2(n2−1),故s22s12=σ2(n2−1)s22/(n2−1)σ2(n1−1)s12/(n1−1)=χ2(n2−1)/(n2−1)χ2(n1−1)/(n1−1)∽F(n1−1,n2−1)。 F分布广泛应用于离差平方和的比较问题中,在比较中采用除法,结果会服从F分布。在方差分析、回归方程的显著性检验中都应用F分布。 六、分位点(是一个点) 分布函数表示了分布中某个点左侧的面积(概率),与此同时,用右侧面积来定义(分位点) 以标准正态分布为例,其分位点记为 Z α Z_{\alpha} Zα, Z α Z_{\alpha} Zα表示在标准正态分布N(0,1)中,右侧分布(概率)为α的点。 分位点 Z α Z_{\alpha} Zα与分布函数 Φ ( x ) \Phi(x) Φ(x)不一样,前者根据右侧面积(概率)来确定X的值,后者根据X的值来确定其左侧面积(概率)。两者已知条件和目标刚好相反,故可根据分布函数表来确定求解分位点 Z α Z_{\alpha} Zα。 已知 Z α Z_{\alpha} Zα右侧面积为 α \alpha α,求解 Z α Z_{\alpha} Zα:① Z α Z_{\alpha} Zα右侧面积为 α \alpha α,则左侧面积为 1 − α 1-\alpha 1−α;②从表中找面积 1 − α 1-\alpha 1−α,则对应对应的最外侧列十行的值为 Z α Z_{\alpha} Zα。 同理有 t α 、 χ α 2 、 F α t_{\alpha}、\chi_{\alpha}^2、F_{\alpha} tα、χα2、Fα分位点实际上是分布中的临界值,在参数估计和假设检验等方法中非常常用。
F ( x ) = P ( X ≤ x ) = ∫ − ∞ x f ( t ) d t = ∫ − ∞ x 1 σ 2 π e − ( t − μ ) 2 2 σ 2 d t F(x)=P(X\leq x)=\int^x_{-\infty}f(t)dt=\int^x_{-\infty}\frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{(t-\mu)^2}{2\sigma^2}}dt F(x)=P(X≤x)=∫−∞xf(t)dt=∫−∞xσ2π1e−2σ2(t−μ)2dt
正态分布的概率密度函数和分布函数
ϕ ( x ) = 1 2 π e − x 2 2 , − ∞ < x < + ∞ \phi(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}},-\infty
记作X~N(0,1)
标准正态分布的分布函数里面没有了μ和σ,因为μ为0,σ为1。标准正态分布的分布函数图是确定的。
普通正态分布转变为标准正态分布:对于任何普通正态分布N(μ,σ2),若XN(μ,σ2),则Z=(X-μ)/σN(0,1),将其转换成标准正态分布(这里的Z表示经过标准化后,服从正态分布的随机变量。
如 X ∽ N ( 1 , 4 ) , 则有 P ( X ≤ 2.16 ) = P ( X − 1 2 ≤ 2.16 2 ) = P ( Z ≤ 0.58 ) = Φ ( 0.58 ) = 0.7190 如X\backsim N(1,4),则有P(X\leq2.16)=P(\frac{X-1}{2}\leq \frac{2.16}{2})=P(Z\leq0.58)=\Phi(0.58)=0.7190 如X∽N(1,4),则有P(X≤2.16)=P(2X−1≤22.16)=P(Z≤0.58)=Φ(0.58)=0.7190
若X~N(μ,σ2),则有
P ( μ − k σ < X < μ + σ ) = P ( − k < X − μ σ < k ) = P ( − k < Z < k ) = 2 Φ ( k ) − 1 若 k = 1 , 则有 P ( μ − σ < X < μ + σ ) = 2 Φ ( 1 ) − 1 = 0.6826 ; 若 k = 2 , 则有 P ( μ − 2 σ < X < μ + 2 σ ) = 2 Φ ( 2 ) − 1 = 0.9544 ; 若 k = 3 , 则有 P ( μ − 3 σ < X < μ + 3 σ ) = 2 Φ ( 3 ) − 1 = 0.9974 ; P(\mu-k\sigma
常用均值加减3个标准差作为异常值的判断,因为99.74%的数据是在这个范围内的,只有极少数据落在这个范围内,故可以判断为异常值。