【Webpack】资源输入输出 - 配置资源入口
资源处理流程
Webpack 中的资源处理流程
在一切流程的最开始,首先需要指定一个或多个人口(entry),也就是告诉Webpack具体从源码目录下的哪个文件开始打包。如果把工程中各个模块的依赖关系当作一棵树,那么入口就是这棵依赖树的根
这些存在依赖关系的模块会在打包时被封装为一个 chunk。chunk字面的意思是代码块,在 Webpack 中可以理解成被抽象和包装过后的一些模块。根据具体配置不同,一个工程打包时可能会产生一个或多个chunk。
从上面的步骤可以看到,Webpack 会从人口文件开始检索,并将具有依赖关系的模块生成一棵依赖树,最终得到一个chunk。由这个chunk得到的打包产物我们一般称之为bundle。
entry 形成module 组合成chunk 打包成bundle
在工程中可以定义多个人口,每一个人口都会产生一个结果资源。比如我们工程中有两个人口src/index.js和src/lib.js,在一般情形下会打包生成dist/index.js和dist/lib.js.因此可以说,entry与bundle存在着对应关系
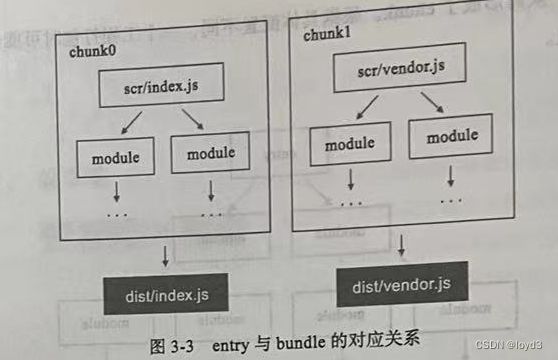
在一些特殊情况下,一个人口也可能产生多个chunk并最终生成多个bundle
配置资源入口
Webpack通过context和entry这两个配置项来共同决定人口文件的路径。在配置人口时,实际上做了两件事:
- 确定人口模块位置,告诉Webpack从哪里开始进行打包。
- 定义chunk name。如果工程只有一个入口,那么默认其chunk name为“main”;如果工程有多个入口,我们需要为每个入口定义chunk name,来作为该chunk的唯一标识。
context
context可以理解为资源入口的路径前级,在配置时要求必须使用绝对路径的形式
//以下两种配置达到的效果相同,入口都为 <工程根路径>/src/scripts/index.js
module.exports = {
context: path.join(__dirname, './src'),
entry: './scripts/index.js',
};
module.exports = {
context: path.join(__dirname, './src/scripts'),
entry: './index.js',
};
配置context的主要目的是让entry 的编写更加简洁,尤其是在多人口的情况下context可以省略,默认值为当前工程的根目录。
entry
与context 不同,**entry的配置可以有多种形式:字符串、数组、对象函数。**可以根据不同的需求场景来选择。
1.字符串类型入口
module.exports = {
entry:./src/index.js',
output: {
filename: 'bundle.js' ,
},
mode: 'development',
};
2.数组类型入口
传人一个数组的作用是将多个资源预先合并,在打包时 Webpack 会将数组中的最后一个元素作为实际的入口路径。
module.exports = {
entry:['babel-polyfill','./src/index,js'],
};
上面的配置等同于:
// webpack.config.js
module.exports ={
entry: './src/index,js',
};
// index.js
import 'babel-polyfill';
3.对象类型入口
如果想要定义多人口,则必须使用对象的形式。对象的属性名 (key)是 chunk name,属性值(value)是入口路径。如:
module.exports = {
entry:{
// chunk name为index,入口路径为./erc/index.js
index: './src/index.js',
// chunk name为lib,入口路径为./src/lib.js
lib: './src/lib.js'
}
}
对象的属性值也可以为字符串或数组。如:
module.exports = {
entry:{
index: ['babel-polyfill','./src/index,js'],
lib: './src/lib.js'
}
}
在使用字符串或数组定义单人口时,并没有办法更改chunk name,只能为默认的“main”。在使用对象来定义多人口时,则必须为每一个人口定义chunk name。
4函数类型入口
用函数定义人口时,只要返回上面介绍的任何配置形式即可,如:
// 返回一个字符串型的入口
module.exports=(
entry: () => './src/index.js',
};
//返回一个对象型的入口
module.exports = {
entry:() => {
index: ['babel-polyfill','./src/index,js'],
lib: './src/lib.js'
}
}
传人一个函数的优点在于我们可以在函数体里添加一此动态的逻辑来获取工程的人口。另外,函数也支持返回一个Promise对象来进行异步操作。
//返回一个对象型的入口
module.exports = {
entry: ()=>new Promise((resolve) => (
//棋拟异步操作
setTimeout(() =>{
resolve('.src/index.js');
},1000);
}),
};
实例
单页应用
对于单页应用(SPA)来说,一般定义单一人口即可
module.exports=(
entry: './src/app.js',
};
无论是框架、库,还是各个页面的模块,都由 app.js单一的人口进行引用。这样做的好处是只会产生一个JS文件,依赖关系清晰。而这种做法也有弊端,即所有模块都打包到一起,当应用的规模上升到一定程度之后会导致产生的资源体积过大,降低用户的页面渲染速度。
提取 vendor
试想一下,假如工程只产生一个JS文件并且它的体积很大,一旦产生代码更新即便只有一点点改动,用户都要重新下载整个资源文件,这对于页面的性能是非常不友好的。
为了解决这个问题,我们可以使用提取vendor 的方法。vendor的意思是“供应商在Webpack中vendor一般指的是工程所使用的库框架等第三方模块集中打包而产的 bundle。请看下面这个例子:
module.exports=(
context: path.join(__dirname,'./src'),
entry: {
app: './src/app.js',
vendor: ['react','react-dom','react-router']
}
};
这里添加了一个新的chunk name为vendor 的人口,并通过数组的形式把工程所依赖的三方模块放了进去。
Webpack会采用optimization.splitChunks,将app与vendor这两个chunk中的公共模块提取出来。
通过这样的配置,app.js产生的bundle将只包含业务模块,其依赖的第三方模块将会被抽取出来生成一个新的 bundle,这也就达到了我们提取vendor的目标。由于vendor仅仅包含第三方模块,这部分不会经常变动,因此可以有效地利用客户端缓存,在用户后续请求页面时会加快整体的渲染速度。
多页应用
对于多页应用的场景,为了尽可能减小资源的体积,我们希望每个页面都只加载各自必要的逻辑,而不是将所有页面打包到同一个bundle中。因此每个页面都需要有一个独立的bundle,这种情形我们使用多入口来实现。看下面的例子
module.exports = {
entry: {
pageA: './src/pageA.js',
pageB: './src/pageB.js',
pageC: './src/pageC.js',
}
}
在上面的配置中,人口与页面是一一对应的关系,这样每个HTML 只要引入各自的JS就可以加载其所需要的模块
另外,对于多页应用的场景,我们同样可以使用提取 vendor的方法,将各个页面之间的公共模块进行打包。
module.exports = {
entry: {
pageA: './src/pageA.js',
pageB: './src/pageB.js',
pageC: './src/pageC.js',
vendor: ['react','react-dom'],
}
}
可以看到,将react和react-dom打包进了vendor,之后再配置optimization.
splitChunks,将它们从各个页面中提取出来,生成单独的 bundle即可。