集群容器频繁OOMKilled的排查经历
背景
我司采用的是k8s治理编排容器服务
出现的问题:线上某个应用pod频繁重启,13天内每个pod重启约8~9次

排查步骤
1.查看pod重启原因和重启时间点
kubectl describe pods okr-indicator-deploy-84bc5779c-55xsn -n rishiqing-v2
State: Running
Started: Sat, 02 Dec 2023 13:55:58 +0800
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Fri, 01 Dec 2023 13:51:19 +0800
Finished: Sat, 02 Dec 2023 13:55:57 +0800
Ready: True
Restart Count: 9
Limits:
cpu: 1500m
memory: 3Gi
Requests:
cpu: 1500m
memory: 3Gi
可以看到
- 重启原因:OOMKilled
- 时间:12月02日13:55:57左右
由于pod有探针机制(容器健康度检测),如果容器unhealth会直接restart容器,所以无法在unhealth的状态下使用一些命令工具查看容器内存具体使用情况。
基于以上限制因素,只能先通过日志和监控看下有无线索。
2.日志(查看pod重启前最后一刻的)
kubectl logs -p xxxxx -n yyyy >/user/root
发现日志并无异样,也没有相关异常报错信息
3.监控
jvm监控
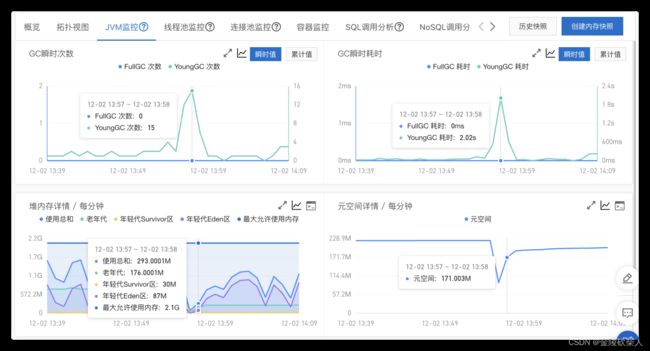
有突然上升的younggc次数,但是这个时间点58也可能是容器刚启动那一刻
4.查看pod所在k8s-node日志
找到pod当时所在node,查看日志路径
/var/log/messages
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: CPU: 0 PID: 2079469 Comm: http-nio-8080-e Tainted: G OE ------------ T 3.10.0-1127.19.1.el7.x86_64 #1
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: Hardware name: Alibaba Cloud Alibaba Cloud ECS, BIOS 449e491 04/01/2014
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: Call Trace:
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff8a17ffa5>] dump_stack+0x19/0x1b
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff8a17a8c3>] dump_header+0x90/0x229
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff89c9c4d8>] ? ep_poll_callback+0xf8/0x220
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff89bc251e>] oom_kill_process+0x25e/0x3f0
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff89b33a51>] ? cpuset_mems_allowed_intersects+0x21/0x30
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff89c40c56>] mem_cgroup_oom_synchronize+0x546/0x570
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff89c400d0>] ? mem_cgroup_charge_common+0xc0/0xc0
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff89bc2dc4>] pagefault_out_of_memory+0x14/0x90
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff8a178dd3>] mm_fault_error+0x6a/0x157
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff8a18d8d1>] __do_page_fault+0x491/0x500
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff8a18da26>] trace_do_page_fault+0x56/0x150
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff8a18cfa2>] do_async_page_fault+0x22/0xf0
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [<ffffffff8a1897a8>] async_page_fault+0x28/0x30
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: Task in /kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod943d7e40_3a14_4519_b7a7_a2b6ee3576fb.slice/docker-928e0ea07906597976057ef044c3766df7867e3c629ee6312a5dd1683b545720.scope killed as a result of limit of /kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod943d7e40_3a14_4519_b7a7_a2b6ee3576fb.slice
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: memory: usage 3145728kB, limit 3145728kB, failcnt 498567
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: memory+swap: usage 3145728kB, limit 9007199254740988kB, failcnt 0
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: kmem: usage 0kB, limit 9007199254740988kB, failcnt 0
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: Memory cgroup stats for /kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod943d7e40_3a14_4519_b7a7_a2b6ee3576fb.slice: cache:0KB rss:0KB rss_huge:0KB mapped_file:0KB swap:0KB inactive_anon:0KB active_anon:0KB inactive_file:0KB active_file:0KB unevictable:0KB
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: Memory cgroup stats for /kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod943d7e40_3a14_4519_b7a7_a2b6ee3576fb.slice/docker-fe1d7dae3ef237940616fe625a5c520d2de9b2d2f9379b039dc9e42535e8f0d7.scope: cache:0KB rss:40KB rss_huge:0KB mapped_file:0KB swap:0KB inactive_anon:0KB active_anon:40KB inactive_file:0KB active_file:0KB unevictable:0KB
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: Memory cgroup stats for /kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod943d7e40_3a14_4519_b7a7_a2b6ee3576fb.slice/docker-928e0ea07906597976057ef044c3766df7867e3c629ee6312a5dd1683b545720.scope: cache:156KB rss:3145532KB rss_huge:1538048KB mapped_file:44KB swap:0KB inactive_anon:0KB active_anon:3145500KB inactive_file:36KB active_file:32KB unevictable:0KB
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [ pid ] uid tgid total_vm rss nr_ptes swapents oom_score_adj name
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [285292] 0 285292 239 1 2 0 -998 pause
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: [2076520] 0 2076520 4999026 787017 1968 0 953 java
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: Memory cgroup out of memory: Kill process 4113092 (Java2D Disposer) score 1955 or sacrifice child
Dec 2 13:55:56 iZ2ze2ih1s2cnx3x31dpdeZ kernel: Killed process 2076520 (java), UID 0, total-vm:19996104kB, anon-rss:3134504kB, file-rss:13564kB, shmem-rss:0kB
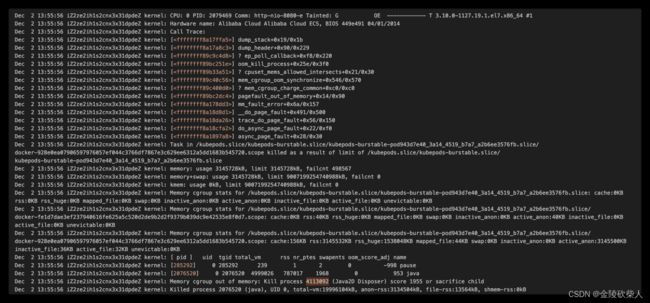
线索信息:
- 内存多次达到limit

- 内核态确认杀死进程 kill process

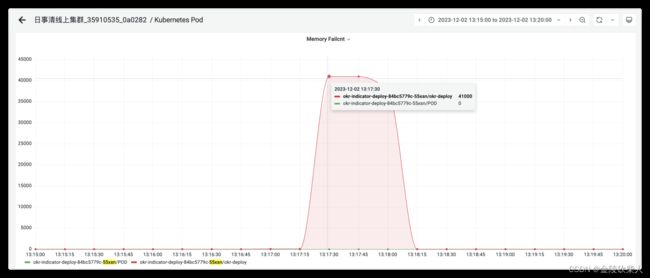
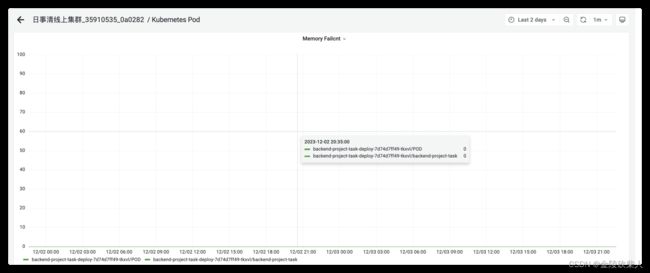
5.观测pod(使用prometheus观测)
看到一个很有意思的指标 memory failcnt
在13:15的时候有明显突刺
在13:55重启之间也会有不同程度的数值
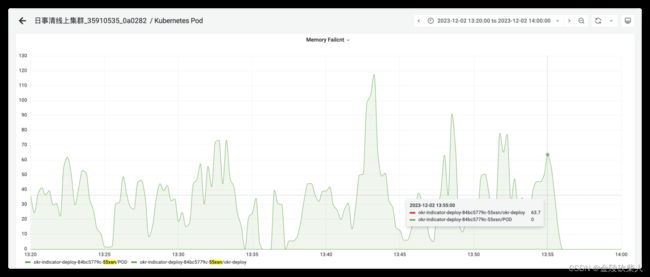
然后搜索该指标含义,在linux内核官网上有这么一番描述
memory.failcnt # show the number of memory usage hits limits
memory.failcnt 表示内存使用击中限制的次数。
看样子像是代表容器的内存使用率一直处于很高的状态,
于是我对比看了下另一个小组从未重启过的pod的使用情况,果然别人家的孩子一直都是0。
基于此,有观测到了几个有意思的指标
- wss:working set size 使用内存大小
- rss:resident set size 占用内存大小
k8s偏注重wss,此说法的依据:
- 阿里云解释 container_memory_working_set_bytes是容器真实使用的内存量,也是资源限制limit时的重启判断依据
- k8s官方解释 The working set metric typically also includes some cached (file-backed) memory, because the host OS cannot always reclaim pages
结论:
container_memory_usage_bytes > container_memory_working_set_bytes > container_memory_rss
基于此结论,将观测时间线拉长,发现内存的rss指标总体一直呈上升趋势,直到最后容器重启
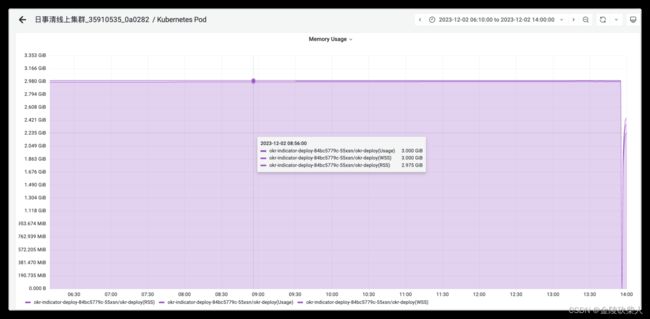
难道是内存泄漏吗?
再次回到上面的jvm监控信息上,发现只有非堆在不停增长,已知jdk8将元空间的实现放在非堆内存中,所以决定限制元空间大小观测几天
-XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m
至此该应用没问题了,但是另一个应用自从限制之后开始频繁fullgc,根源还是metaspace空间不够触发的fullgc
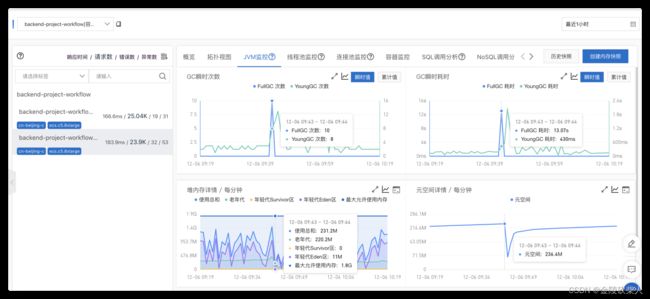
至此有两种方案
- 提升metaspace
-XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m
- 缩小堆空间,不限制元空间大小,间接提升metaspace
-XX:InitialRAMPercentage=50.0 -XX:MaxRAMPercentage=50.0
但是以上两种方案尝试过后均没有根治重启的问题,元空间增长到一定程度之后pod还是会重启。
至此基本可以推断出存在一定的内存泄漏问题
内存泄漏:程序分配内存后,该内存区域无法再次使用或释放
可能性1:netty线程池优化导致的内存泄漏问题
运行一段时间后,dump出heapdump文件
借助mat工具查看
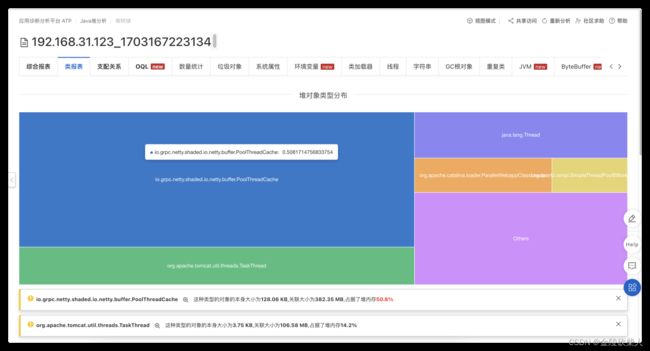
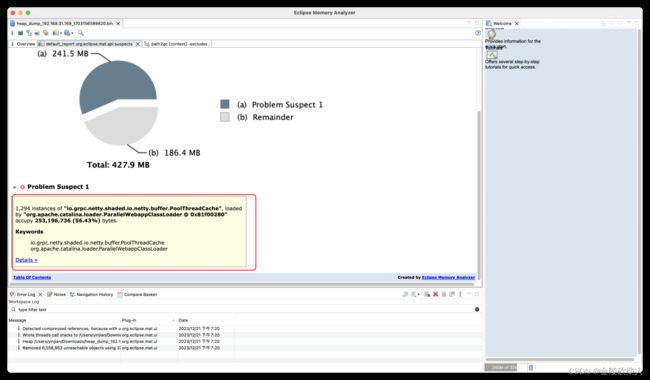
io.grpc.netty.shaded.io.netty.buffer.PoolThreadCache
github讨论对应的issue
https://github.com/grpc/grpc-java/issues/5671
怀疑通过线程缓存产生了大量的垃圾,解决方案关闭对应缓存
Dio.netty.allocator.useCacheForAllThreads=false
可能netty内存泄漏问题,但有如下疑虑点:
- grpc的netty版本不好确定,因为grpc的netty不是通过pom的方式引入的jar包,而是直接复制源码引入的
- 同时引入的是grpc-netty-shaded,非官方的包,这个包能保证不和其他中间件的netty版本冲突。所以不确定是不是netty版本过低导致的类似问题
观察几天后发现容器还是会有类似问题出现,继续排查。
可能性2:继续观察元空间,大概率还是元空间类加载的问题
晚上配置打印出类加载信息
-XX:+TraceClassLoading -XX:+TraceClassUnloading
早上峰值来看:大量类似信息,而且一直在加载类似类,且在gc后无任何unload信息
- 加载关键字:Loaded
- 卸载关键字:Unloading
加载
[Loadedma.glasnost.orika.generated.Orika_FieldVO_FieldDetailDTO_Mapper62812963418674919$3899fromfile:/usr/local/tomcat/webapps/task%23workflow/WEB-INF/lib/orika-core-1.5.4.jar]
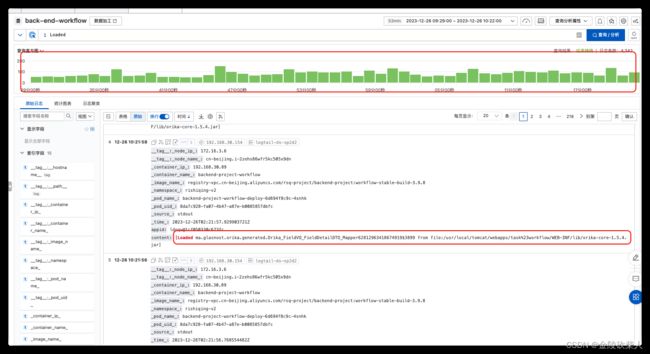
卸载
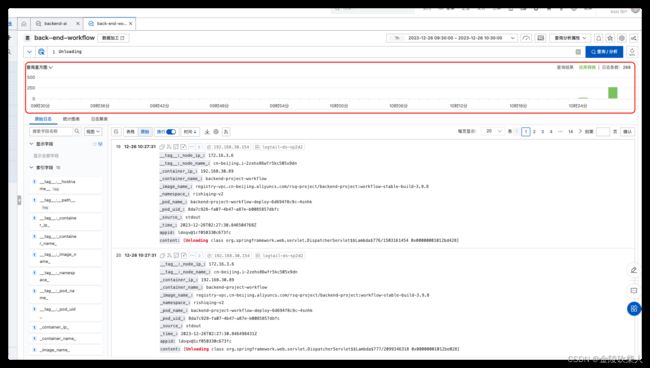
查看gc情况:(此处略去,大致提现是元空间持续增长)
结合验证:
1.jmap -clstats 查看元空间加载的类是否有大量重复的
2.arthas的classloader
(错误,这个是查看的类加载器,和加载的类信息是两个概念,粗心)
实际上应该是sc命令
sc ma.glasnost.orika.generated.*
一个刚启动30min的pod,已经加载类似类750+

另一个从昨晚12点左右启动到今早10:50左右,简单说可以是近2个小时,已经近5000个类似的重复类

3.用mat工具查看下dump文件:主要看加载的类信息
这里其实犯了个很低级的错误 Duplicate Classes :重复类,与本次想要观测的指标不是一个东西
4.结合具体代码定位最终问题:通过动态代理生成了很多mapper转换类
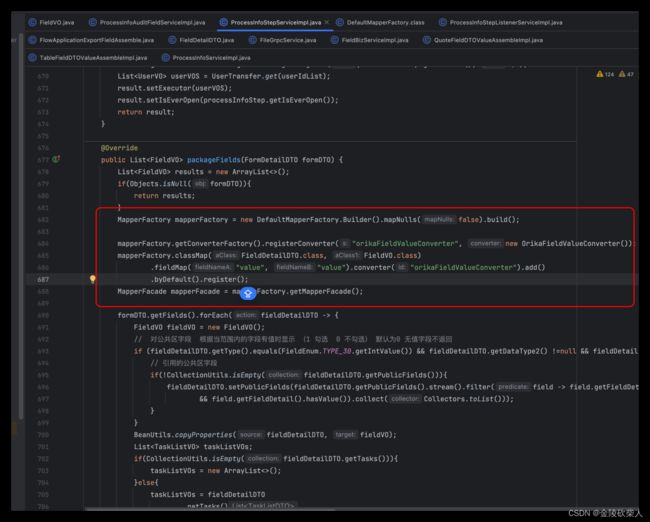
至此修改代码提交测试上线。
QA
问:为什么没有触发fullgc来回收元空间的类?
因为没有限制元空间大小,而元空间属于非堆内存,基本可以理解为宿主机控制。所以pod的oomkilled优先于元空间引发的fullgc,提前一步kill容器,所以一直没有fullgc回收已加载类信息
问:为什么不限制元空间大小?
尝试限制过,但是会引发另一个问题:
- 导致fullgc耗时过长,导致pod的探针健康检测机制触发unhealth,还是会kill容器。
- 这里有考虑过加大探针超时时间,但是考虑到目前配置的是:超时5s,不健康3s。继续加大的话,线上性能肯定会受影响。
- 同时这也只是个治标不治本的方案,因为从观测内存结果来看,内存整体还是一直呈上升趋势
问:为什么这些已加载类没有被gc回收?
- 监控没有触发fullgc,大概率是因为pod的oomkill机制优先于jvm元空间导致的fullgc
- 同时一个已加载类信息要被回收需要同时满足如下条件(相当苛刻)
- 该类所有实例已经被回收:堆中不存在该类任何实例
- 加载该类的类加载器已经被回收:这条几乎很难满足,除非是精心设计过的,如osgi,jsp的重加载
- 该类的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
总结
- 排查问题
细致!注意分析工具的英文解释,每一个英文都得关注(粗心)
- 日常开发
- 引入jar包一定要深入理解最佳实践后才使用,切勿浅尝辄止能用就行
- 一个已经加载的类被卸载的几率是很小的同时被卸载的时间也是不确定的
- 工具方面
- mat似乎不太好查看已加载类信息,比较侧重不同类加载器加载同一个类导致的重复类问题
- visualvm也不太好查看已加载类信息
- arthas不错 功能全面