Python(1)——初识Python
关注微信公众号“IT小组”,获取更多知识干货~
目录:
Python历史
编程语言的基础
Python特点(优点、注释、交互、变量)
Python中进制的转换
Python3与Python2的区别
一:Python的历史
Python的创始人为荷兰人吉多·范罗苏姆 (Guido van Rossum)。
1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,作为ABC 语言(吉多曾经参与过ABC语言的开发)的一种继承。之所以选中Python(大蟒蛇的意思)作为该编程语言的名字,是取自英国20世纪70年代首播的电视喜剧《蒙提.派森的飞行马戏团》(Monty Python’s Flying Circus)。
二:编程语言的基础
Python是一种解释型高级编程语言。
想要理解这一点,我们首先要知道计算机是如何运行程序的,在计算机的世界里只能识别0和1,但是我们在编程的时候并没有以0和1(二进制)来编程,这是为什么呢?因用二进制编写代码(机器语言)并不利于人们阅读。为了改变这种状况,人们发明了汇编语言,汇编语言更接近机器语言,但是汇编语言也只是对机器语言做了“标识”,使用汇编语言时只是利用简单的编译将汇编语言转为了机器语言,由于汇编语言本质并没有改变机器语言的难以阅读,编写困难等缺点,汇编语言也很快被开发人员抛弃。为了改变机器语言和汇编语言这种低级语言的缺点,人们又开发了高级语言(C,C++,Java,Python等),高级语言通过人类的自然语言(English)编写程序,有利于人们阅读,很快高级语言成为了编程的主流,比如C家族语言中的C,C++,C#,Java和脚本语言Python等。
高级语言里又可以分为两大类:
- 编译型语言
- 解释性语言
编译型语言和解释型语言的区别在于:
编译型语言要将源代码通过“编译器”编译成最终的可执行文件(机器语言),而解释型语言不需要将源代码通过编译器转为可执行文件,而是通过一个“解释器”逐行解释并运行每一行代码。编译型语言的运行速度比解释型语言高,因为在编译型语言中将源代码通过编译器转为可执行文件的过程并不在运行代码的时间范围内,我们直接运行可执行文件(二进制文件)即可,而解释型语言需要在运行的过程中逐行编译解释(一边解释一边运行),所以解释型语言的速度比编译型语言要慢。如下图:
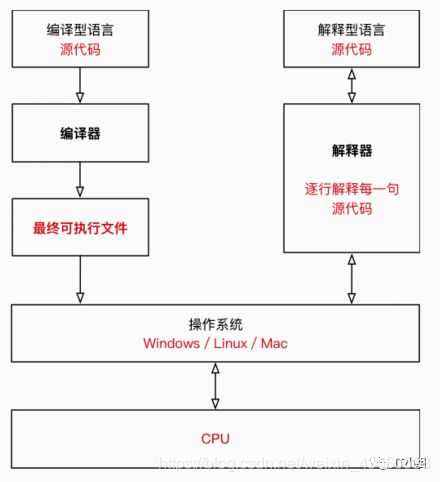
Python是属于解释型高级语言,而Python的解释器有多个语言实现,其中官方的是以C语言实现,每一行Python代码都通过Python的解释器进行编译,完成各个指令。
三:Python特点
Python的优点:
- 简单:Python是一种代表简单主义思想的语言,阅读一个良好的Python程序就像是在阅读英语一样。
- 易学:Python及其容易上手,对新人友好。
- 免费和开源:Python是FLOSS(自由/开放源码软件)之一。
- 高层语言:当用Python语言编写程序的时候,无需考虑管理内存等复杂的底层细节。
- 可移植性:Python能在大多数平台运行,这些平台如Linux,Windows,FrrBSD等等。
- 面向对象:Python支持面向过程,也支持面向对象的编程。
Python的交互:
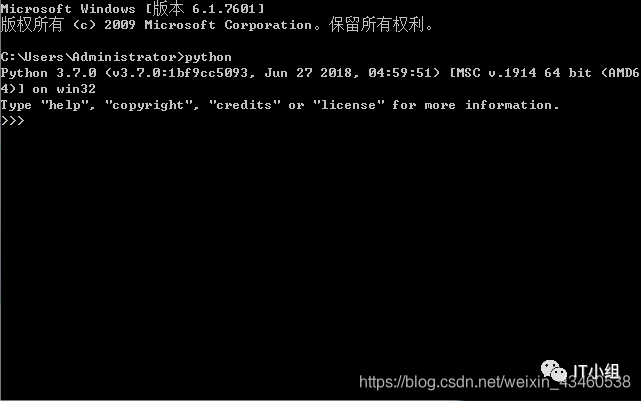
Python在安装完成后,以Windows为例,在CMD命令行中输入python,就进入了python交互页面。所谓的交互式编程是指直接在终端中运行解释器,而不使用文件名的方式来执行文件,这种交互的编程环境,我们也可以称之为REPL环境,即读取(Read)输入的内容,执行(Eval)用户输入的指令,打印(Print)执行的结果,然后进行循环(Loop)。
如图:
交互式编程的优缺点:
优点:适合于学习验证Python语法或者局部代码。
缺点:代码不能保存,不适合运行太大的程序。
在开发环境中,很少使用Python自带的交互式页面来编程,通常使用PyCharm等软件来进行Python的开发。
Python的注释:
任何一门编程语言都会有注释,不写注释的程序员不是一个合格的程序员,在Python中的注释是有三种形式来标示。
- 单行注释:单行注释是用“#”来标示。
- 多行注释:多行注释是用三对单引号或者三对双引号来标示。
如图:

写完注释后,对于注释的获取,我们可以通过一个特殊的属性(__doc__)来获取,例如我们想获取print函数(如果你不知道什么是print函数,不用担心,后面章节会谈到它)中的文档注释,可以用此代码:print (print.__doc__)
效果如下:
print(print__doc__)
# 打印结果如下:
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
# Prints the values to a stream, or to sys.stdout by default.
# Optional keyword arguments:
# file: a file-like object (stream); defaults to the current sys.stdout.
# sep: string inserted between values, default a space.
# end: string appended after the last value, default a newline.
# flush: whether to forcibly flush the stream.
Python中的变量:
在任何一个高级编程语言中都有变量这种类型,变量变量意味着它不是一个固定的量,变量实际上是一个带有地址的“箱子”。在Python中我们可以向变量里放入Python支持的数据类型,类似于如下,我们定义了一个变量a,给它赋值(=)为’hello,world’(字符串)。那就意味着a就是’hello , world’(字符串)。
如下:
a = 'hello,world' # 定义了一个变量a,并给它赋值为‘hello ,world’
print (a) # 打印a
# 打印结果
hello,world
使用变量的好处是可以更加灵活的编写代码,如果没有使用变量a,我们想打印5遍‘hello,world’就不得用如下的方法:
# 当然可以使用循环,但是这里不使用,为了更好的介绍变量的优点
print ('hello,world')
print ('hello,world')
print ('hello,world')
print ('hello,world')
print ('hello,world')
你可能认为这没有什么,但是如果我们想改变打印,将输出’hello,world’变为打印’你好,世界’。我们就不得不连续将这五行代码改变,这是非常让人不爽的。如果我们使用了变量,我们仅仅将变量a赋值改变即可:
print ('hello,world')
print ('hello,world')
print ('hello,world')
print ('hello,world')
print ('hello,world')
# 使用了变量后,如改变打印,仅仅改变a的赋值即可
a = '你好,世界'
print (a)
print (a)
print (a)
print (a)
print (a)
变量的好处远远不止这些,因为有了变量我们的代码才能如此简洁明了。
上面我们通过赋值给了a指定的值,这里我们要强调一下,在Python中用“=”代表赋值,赋值是将右边的值赋值给左边,但是等号的左边不能是常量和表达式。
# 错误:2 = 'hello'
# 错误:1+2 = 3
在Python中支持如下写法,这是在大多数高级语言中所不支持的。可以连续赋值给多个变量,在Python中这是拆包(后面我们会谈)。
a = b = 3
# 错误:a = b = 3 = c
在Python中,变量名,函数名,类名,模块名等都可以称为标识符,它们的命名是有一定的规则的。
Python的标识符命名规则和绝大多数高级语言一样,都是以数字、字母、下划线构成,但是不能使用关键字和以数字开头并且严格区分大小写。
a = 3 # 正确
a2 = 'hello' # 正确
a_3 = 'nihao' # 正确
12 = 3 # 错误
1a = 3 # 错误
_a = 34 # 错误
if = 'hello' # 错误因为在Python中if属于关键字
If = 'hello' # 正确,因为If不是关键字
上面是变量的命名规则,规则是必须要遵守的。
而Python中还有命名规范(规范意味着你可以不遵守,但是建议你要遵守)Python中变量的命名规范如下:
- 使用下划线连接每个单词:user_name 。
- 函数名采用小驼峰命名法:userName,所谓小驼峰命名法是除了第一个单词的首字母小写以外,其余单词首字母大写。
- 类名采用大驼峰命名法:StudentModel,所谓的大驼峰命名法是每个单词的首字母大写。
当然了,这是建议如此,因为这样会让你的代码看起来美观和易阅读。
四:进制的转换方式
在计算机中只能处理0和1,这就意味着我们的所有数据最终都会转为二进制来进行处理或存储。
但是计算机也支持八进制和十六进制等(当然,它们都会以0和1来保存)。
在Python中二进制的表示方式:
a = 0b1001 # 在Python中使用0b表示二进制(二进制中由0-1组成,逢二进一)
在Python中八进制的表示方式:
b = 0o14 # 在Python中使用0o表示八进制(八进制中由0-7组成,逢八进一)
在Python中十六进制的表示方式:
c = 0x1f # 在Python中使用0x表示十六进制(十六进制中由0-f组成,逢十六进一)
进制转换公式:
将要转换的数值从右往左分别乘与基数的次方,我们以十六进制为例:
0x1f = 1*16^1 + 15*16^0
# 即结果为31
五:Python3与Python2的区别
因为Python2(Python2现在已不再更新)与Python3都是并行开发的,他们之间也是有很大的不同的,具体不同如下:
- long数据:Python2中保留了long数据类型,而Python3则废弃了此类型。
- 八进制表示的不同:Python2中八进制的表示以0开头,例如:0100代表八进制中的64。(Python3只支持0o表示d)
- 输入语句的不同:Python3使用input作为输入语句,而Python2使用ra_input作为输入语句。
- 算术运算的区别:Python2默认不保留小数,向下取整,而Python3默认保留一位小数,这也就是说,在Python2中如果两个整数做算数运算,得到的是一个整数,而Python3中两个整数做算数运算则得到一个浮点数。
- 比较运算符的区别:Python2支持两种“不等于”写法,“<>”和“!=”。而Python3只支持“!=”。
- 字典key方法的不同:python2中字典有一个判断key是否存在的方法has_key( ),而Python3取消了该方法,但可以通过in运算符来判断key是否存在。
以上只是常见的不同,Python2和Python3更多具体细节的不同可以参考官网的Python手册。