【Win32准备】API,Win32入口程序,宽字符
文章目录
- 一.多字节字符与宽字节字符
-
- 1.宽字符的使用示例
- 2.如何使用宽字符和多字节
- 3.控制台打印
- 二.如何告诉编译器在控制台打印简体中文
- 三.C语言宽字符函数
-
- 1.字符串长度
- 2.字符串复制
- 3.其他宽字符函数
-
- <1>.wcscat函数
- <2>.wcscmp函数
- <3>.wcsstr函数
- 四.Win32API中的宽字符
-
- 1.什么是Win32API
- 2.重要的DLL
-
- <1>.Kernel32.dll
- <2>.User32.dll
- <3>.GDI32.dll
- 3.Win32API中的宽字符和多字节字符
-
- <1>.字符类型
- <2>.字符串指针类型
- 4.为字符数组赋值
- 5.为字符串指针赋值
- 五.各种类型的MessageBox
- 六.Win32入口程序
- 七.在Win32程序中打印信息
- 八.GetLastError函数
一.多字节字符与宽字节字符
在介绍多字符之前,向大家介绍ASCII编码,这里给出ASCII编码对照表(完整版)。ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。其中最后一位用于奇偶校验。
ASCII码存在的问题: 我们在使用ASCII表的时候,通常会出现乱码的问题,因为ASCII码只有256个字符,我们在使用ASCII码判断内容的时候,通常会出现误差。
类似于ASCII码的一张全是中文汉字的表: GB2312-80码。
UNICODE编码:
在前面我们提到了,在使用ASCII码的时候通常会出现各种各样的问题,那么有没有什么解决方法呢?这里就要给出我们的UNICODE表,Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。Unicode最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
多字节字符:在C语言和C++语言中,char表示多字节字符,我们知道char在内存中占据一个字节,那为什么叫做多字节字符呢?这是因为当要表示一个字时,他可能占用一个字节,也有可能占据好几个字节,比如说当表示中文的时候
其实当使用多字节的时候,编译器对应的是ASCII码表,在ASCII表中查找对应的字符。
宽字节字符:在C++中,wchar_t表示宽字节字符,当他表示一个字的时候,只能是两个字节
当使用宽字节的时候,编译器查找的是UNICODE表,我们前面介绍了,UNICODE表中每个字符都是两个字节(除了特殊情况)。
1.宽字符的使用示例
接下来我们通过示例来看看多字节和宽字节:
#include 我们来到内存窗口查看:
我们可以到ASCII编码表和Unicode表中查看,字符“中”在ASCII表中对应的十六进制编号为0xD0D6,在Unicode编码表中对应的十六进制编号为0x4E2D,而在我们的内存窗口中我们可以看到,以ASCII码的形式存储到内存的时候,只存储了低位一字节,而以Unicode码存储的时候,两个字节完整地存储到了内存中。
2.如何使用宽字符和多字节
我们上文已经介绍过,char类型为多字节,wchar_t类型为宽字符类型,我们来通过示例看看:
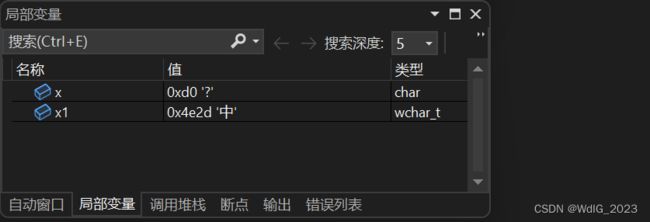
#include 我们来到局部变量窗口看看:
我们可以看到,多字节是以00 结尾,而宽字符是以00 00 结尾的。
3.控制台打印
那么宽字节和多字符在控制台如何打印呢?
多字节使用printf("%s\n",x); ,宽字符使用wprintf(L"%s\n",x1); 那么在上文中我们多次使用大写的” L “,那么它代表什么意思呢?这里编译器默认的是使用ASCII表来查找字符,我们使用” L “就是告诉编译器,使用Unicode码,这时候编译器就会使用Unicode表来替我们查找字符了。
二.如何告诉编译器在控制台打印简体中文
我们知道,Unicode表中记录了很多国家的文字,那么我们如何告诉编译器,在控制台打印的时候打印简体中文呢?
我们需要加入预编译:#include 在程序中加入:setlocale(LC_ALL,""); 这个函数,这个函数就是告诉控制台:使用控制台默认的编码,我们在该函数第二个参数中为传入值,这时候就会使用操作系统中的地域,比如你的操作系统为中国,那么它就会设置为简体中文。
#include 这样一番操作下来之后,我们在控制台就可以正确地打印了:

三.C语言宽字符函数
1.字符串长度
我们知道在C语言中我们可以使用strlen函数来计算字符串长度,那么我们的多字节和宽字符如何计算字符串长度?
对于多字节,我们仍然可以使用strlen(); 函数来计算字符串长度(不包含末尾的\00)。
对于宽字符,我们可以使用wcslen(); 函数来计算字符串长度(不包含末尾的\00 \00)。
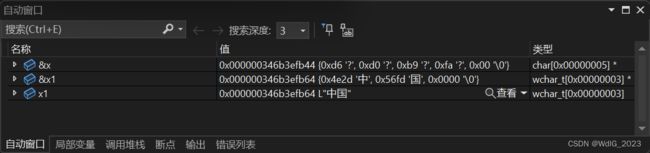
#include 我们来到局部变量窗口观察:

我们可以看到,使用多字节保存”中国“时,字符串长度为4,使用宽字节保存”中国“时,字符串长度为4,这也很好的验证了多字节为单个字节存储,宽字符为两个字符存储。
2.字符串复制
我们知道在C语言中,我们可以使用strcpy();函数来进行字符串的复制和赋值,那么宽字符我们该如何赋值?
对于宽字符,我们可以使用wcscpy();函数来进行字符串的复制:
#define _CRT_SECURE_NO_WARNINGS
#include 其中#define _CRT_SECURE_NO_WARINGS可谓是非常经典的问题了,加入这个宏后,程序会少了对很多不安全的问题报错,我们来到局部变量窗口查看:

我们可以看到对于多字节和宽字符,都成功复制。
3.其他宽字符函数
这里我们介绍几个其他的不常用的宽字符函数:
<1>.wcscat函数
函数原型:wchar_t *wcscat(wchar_t *strDestination, const wchar_t *strSource);
函数功能:把strSource所指字符串添加到strDestination结尾处,覆盖strDestination结尾处的’\0’并添加’\0’。
说明:strSource和strDestination所指内存区域不可以重叠且strDestination必须有足够的空间来容纳strSource的字符串。
返回值:返回指向strDestination的指针.。
备注:因为wcscat在strDestination追加strSource前不进行检查,这是一个缓冲区溢出的潜在原因。故使用时应注意。推荐使用wcscat_s替代。
<2>.wcscmp函数
函数原型:int wcscmp(const wchar_t *_Str1, const wchar_t *_Str2);
函数功能:比较字符串_Str1和_Str2
说明:
当_Str1<_Str2时,返回值<0
当_Str1=_Str2时,返回值=0
当_Str1>_Str2时,返回值>0
即:两个字符串自左向右逐个字符相比(按ASCII值大小相比较),直到出现不同的字符或遇’\0’为止。
如: “A”<“B” “a”>“A” “computer”>“compare”
<3>.wcsstr函数
函数原型:const wchar_t* wcsstr (const wchar_t* wcs1, const wchar_t* wcs2);
查找宽字符串wcs1的子字符串wcs2。
返回一个指针,该指针指向wcs1中的wcs2首次出现的位置,或则,如果wcs2不是wcs1的一部分,则返回null。
匹配的过程不包括结尾的null宽字符,但是它在那儿结束。
四.Win32API中的宽字符
1.什么是Win32API
Win32 API即为Microsoft 32位平台的应用程序编程接口(Application Programming Interface)。所有在Win32平台上运行的应用程序都可以调用这些函数。
使用Win32 API,应用程序可以充分挖掘Windows的32位操作系统的潜力。 Mircrosoft的所有32位平台都支持统一的API,包括函数、结构、消息、宏及接口。使用 Win32 API不但可以开发出在各种平台上都能成功运行的应用程序,而且也可以充分利用每个平台特有的功能和属性。
在具体编程时,程序实现方式的差异依赖于相应平台的底层功能的不同。最显著的差异是某些函数只能在更强大的平台上实现其功能。例如,安全函数只能在Windows NT操作系统下使用。另外一些主要差别就是系统限制,比如值的范围约束,或函数可管理的项目个数等等。
标准Win32 API函数可以分为以下几类:
窗口管理
窗口通用控制
Shell特性
图形设备接口
系统服务
国际特性
网络服务
2.重要的DLL
<1>.Kernel32.dll
最核心的功能模块,比如管理内存,进程和线程相关的函数。
<2>.User32.dll
是Windows用户界面相关应用程序接口,如创建窗口和发送消息等。
<3>.GDI32.dll
全程Graphical Device Interface(图形设备接口),包含用于画图和显示文本的函数,比如要显示一个程序窗口,就调用了其中的函数来画这个窗口。
3.Win32API中的宽字符和多字节字符
Windows是C语言开发的,WIn32API同时支持宽字符和多字节字符。
<1>.字符类型
| C语言 | API |
|---|---|
| char | CHAR |
| wchar_t | WCHAR |
| 宏 | TCHER |
<2>.字符串指针类型
- PSTR(LPSTR)
- PWSTR(LPWSTR)
- 宏 PTSTR(LPTSTR)
其实这些类型都是C语言中的基本数据类型,只是使用typedef关键字进行了重命名。
其中使用后宏的时候,编译器会自动匹配正确的格式,就像C++中的模板。
4.为字符数组赋值
CAHR cha[] = "中国";
WCHAR chw[] = "中国";
TCHER cht[] = TEXT"中国";
5.为字符串指针赋值
PSTR pszChar = "China";
PWSTR pszWCher = "Chaina";
PTSTR pszTchar = TEXT"China";
五.各种类型的MessageBox
MessageBoxA(0,"内容多字节“,”标题“,MB_OK);MessageBoxW(0,"内容宽字符“,”标题“,MB_OK);MessageBox(0,TEXT"由字符集决定“,TEXT”标题“,MB_OK);
WIndows提供的API,凡是需要传递字符串参数的函数,都会提供两个版本和一个宏。
六.Win32入口程序
我们创建Win32入口程序,我们会看到一个入口函数:
// Win32.cpp : Defines the entry point for the application.
//
#include "stdafx.h"
int APIENTRY WinMain(HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpCmdLine,
int nCmdShow)
{
// TODO: Place code here.
return 0;
}
我们看到入口函数中有很多参数,我们来简单解释一下这几个参数:
-
hInstance:
表示该程序当前运行的实例句柄,是一个数值标识。当程序在Windows下运行时,它唯一标识运行中的实例(注意,只有运行中的程序实例,才有实例句柄)。一个应用程序可以运行多个实例,每运行一个实例,系统都会给该实例分配一个实例句柄,并通过hInstance参数传递给WinMain函数。 -
hPrevInstance:
表示当前实例的前一个实例的句柄。通过查看MSDN我们可以知道,在Win32环境下,这个参数总是NULL,即在Win32环境下,这个参数不再起作用。 -
lpCmdLine:
是一个以空字符结尾的字符串,内容为命令行的参数。 -
nCmdShow:
指定程序的窗口应该如何显示,例如最大化、最小化、隐藏等。这个参数的值由该程序的调用者所指定,应用程序通常不需要去理会这个参数的值。
WinMain函数前的修饰符APIENTRY,其实是被使用typedef关键字重命名的,它是WINAPI,而WINAPI也是被使用typedef重命名的,它其实就是__stdcall。
在这几个参数中,最重要的是hInstance,我们在前面章节中学习过PE文件格式,其实它就是可选PE头中的ImageBase。
七.在Win32程序中打印信息
#include 我们可以通过OutputDebugString()函数来打印信息。
我们可以看到在输出窗口输出了Hello World!

八.GetLastError函数
但是我们发现一个很严重的问题:我们在写Win32程序的时候,编译器不会报错这时候就需要我们使用OutLastError()函数了:
GetLastError:返回上一次的错误代码,当我们在调用第三方(MFC,Word。。。。)提供的接口时,有时候只能得到返回值是true还是false的时候是不是很苦恼?此时就可以通过GetLastError函数来获取错误代码。
我们会得到一个错误代码,我们通过查询错误代码就可以知道我们程序中的错误了。