百川2-大模型-论文笔记
文章目录
- 0.资料预览
- 1.模型特点速览
- 2.模型效果对比
-
- 2.1 对比BaiChuan 1
- 2.2 对比其它开源模型
-
- 2.2.1 通用基准测试-整体对比
- 2.2.2 垂直领域测试
-
- 2.2.2.1 法律
- 2.2.2.2 数学、编码
- 2.2.2.3 多语言领域
- 3. 预训练数据
-
- 3.0 数据分布
- 3.1数据源
- 3.2 数据处理
-
- 3.2.1 预训练数据处理流程
- 4. 模型结构&预训练
-
- 4.0 基础结构
- 4.1 输入
-
- 4.1.1 词表
- 4.1.2 字符编码
- 4.1.3 位置编码
- 4.2 中间结构
-
- 4.2.1 激活函数
- 4.2.2 注意力层
- 4.2.3 归一化层
-
- 4.2.3.1 层归一化
- 4.2.3.2 归一化头 NormHead
- 4.3 预训练
-
- 4.3.0 损失
- 4.3.1 优化器
- 4.3.2 数据精度
- 4.3.3 预训练损失变化
- 4.4 通过缩放得到大模型
- 5. 后续训练:SFT & RLHF
-
- 5.1 SFT: 监督微调
- 5.2 RLHF: 从人类反馈中强化学习
-
- 5.2.1 RLHF过程示意图
- 5.2.2 奖励模型 (Reward Model, RM)
- 5.2.3 PPO
- 5.2.4 RLHF 训练细节
- 6. 数据毒性
-
- 6.1 预训练阶段
- 6.2 SFT & RLHF 阶段
- 6.3 评估
-
- 6.3.1 Toxigen(Hartvigsen等人,2022)数据集
- 6.3.2 百川无害评价数据集(BHED)
- 7. ckpt
- 8. 设备
0.资料预览
- 论文位置:https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
- github: https://github.com/baichuan-inc/Baichuan2
- 同类文章:
– 精简:https://zhuanlan.zhihu.com/p/655984589
– 详细:
(1)https://mp.weixin.qq.com/s/gUBH7Q_lLPiliSRZed_GRA
(2)https://zhuanlan.zhihu.com/p/657487567
1.模型特点速览
-
模型名称 Baichuan2
-
参数量:7B、13B
-
训练token量:2.6T
-
开源:模型代码、ckpt
-
数据:
– 训练数据:
(1)预训练数据:聚类去重系统(详见 3.2.1节);
(2)SFT & RLHF 数据:10万个监督微调样本(详见 5.1节)、超200个三级类别数据给RM(详见 5.2节);
(3)安全性数据:(详见 6.节)
– 测试数据:
(1)通用基准测试(详见 2.2.1节)
(2)垂直领域测试(详见 2.2.2节)
(3)毒性(安全性)测试(详见 6.3节) -
模型结构(详见 4.节)
基于transformer
(1)词表大小:125696
(2)位置编码:7B使用RoPE 、13B使用 ALiBi
(3)激活函数:SwiGLU
(4)注意力层:由 xFormers2 实现的内存高效的注意力
(5)归一化层:RMS-LN;对embedding输出做了NormHead -
训练
– 预训练(详见 4.3节)
(1)损失:max-z loss
(2)优化器:AdamW
– 后续训练(详见 5.节)
关键词:SFT、RLHF、PPO
(注:开源模型简介 - LaMa (Touvron et al.,2023a)、OPT (Zhang et al.,2022)、Bloom (Scavocchini et al.,2022)、MPT (MosaicML,2023) 、Falcon (Penedo et al.,2023))
2.模型效果对比
2.1 对比BaiChuan 1
在通用基准测试,如 MMLU (Hendrycks et al., 2021a),CMMLU (Li et al., 2023),和 C-Eval (Huang et al., 2023) 中,BaiChuan2-7B 相比 BaiChuan 1-7B 实现了近 30% 的性能提升。具体来说,BaiChuan2 优化以提高解决数学和代码问题的能力。在 GSM8K (Cobbe et al., 2021) 和 HumanEval (Chen et al., 2021) 测试中,BaiChuan 2 将 BaiChuan 1 的结果提高了近一倍。此外,BaiChuan 2 在医学和法律领域的任务上也表现出强大的性能。
2.2 对比其它开源模型
在 MedQA (Jin et al., 2021) 和 JEC-QA (Zhong et al., 2020) 等基准测试中,BaiChuan 2 比其他开源模型表现得更好,使其成为适合特定领域优化的基础模型。
2.2.1 通用基准测试-整体对比

论文表1
测试集(8个):
- MMLU( Hendrycks et al.,2021a)大规模多任务语言理解包含一系列关于学术主题的多项选择题。
- C-Eval(黄等,2023年)是一个综合性的中文评估基准,包括超过1万个多项选择题。
- CMMLU(李等,2023年)也是一个通用的评估基准,专门用于评估在中文语言和文化背景下知识推理能力的语言模型。
- AGIEval(钟等,2023年)是一个以人类为中心的基准,专门用于评估一般能力,如人类认知和问题解决。
- GaoKao 高考(张等,2023年)是一种利用中国高中入学考试问题的评估框架。
- BBH(苏兹古恩等,2022年)是一套挑战性 BIG-Bench( Srivastava 等,2022 年)任务,语言模型的表现没有优于平均人类评分者。
- GSM8K( Cobbe 等,2021 年)是一个专注于数学的评估基准。
- HumanEval(陈等,2021年)是一个代码到文档的数据集,其中包含164个编程逻辑的各个方面进行测试的问题。
对比模型:
- LLAMA (Touvron等人,2023b)
- LLAMA 2(Touvron等人,2023c)
- 百川1
- ChatGLM 2-6B(Zeng等人,2022)
- MPT-7B(MosaicML,2023)
- Falcon-7B(Penedo等人,2023)
- Vicuna-13B(Chiang等人,2023)
- 中文阿尔帕卡加13B(崔等人,2023年)
- XVERSE-13B
(注:原文“对于CMMLU和MMLU,我们采用官方实现,并采用5-shots进行评估。 对于BBH,我们采用3-shots评估。 对于C-Eval、高考和AGIEval,我们只选择四个选项的多选题以获得更好的评估结果。 对于GSM8K,我们使用了来自OpenCompass(OpenCompass,2023)的4-shots测试。 我们还合并了GPT-46和GPT-3.5-Turbo7的结果。 除非另有说明,本文中的所有结果都是通过我们的内部评估工具获得的。”)
2.2.2 垂直领域测试
2.2.2.1 法律
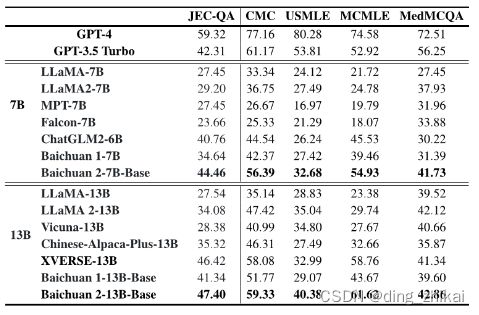
论文表5
2.2.2.2 数学、编码

论文表6
2.2.2.3 多语言领域
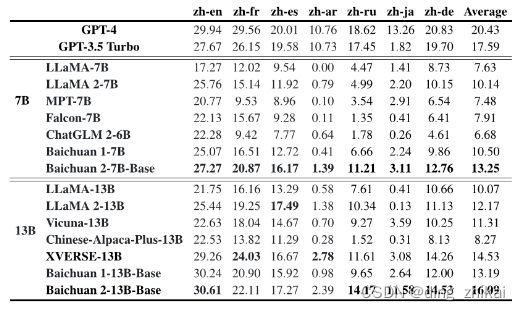
论文表7
3. 预训练数据
3.0 数据分布

论文图1
3.1数据源
从包括 普通互联网网页、书籍、研究论文、代码库等在内的多种来源收集数据。目标是追求全面的数据可扩展性和代表性.
3.2 数据处理
关注 数据频率 和 质量。
数据频率依赖于聚类和去重。构建了一个大规模的去重和聚类系统,支持LSH类似特征和密集嵌入特征。该系统可以在数小时内对万亿级别的数据进行聚类和去重。
3.2.1 预训练数据处理流程
精确重复数据消除 -> 启发式方法 -> 逐句质量过滤器 -> 逐句、逐段重复数据消除
-> 文档式重复数据消除
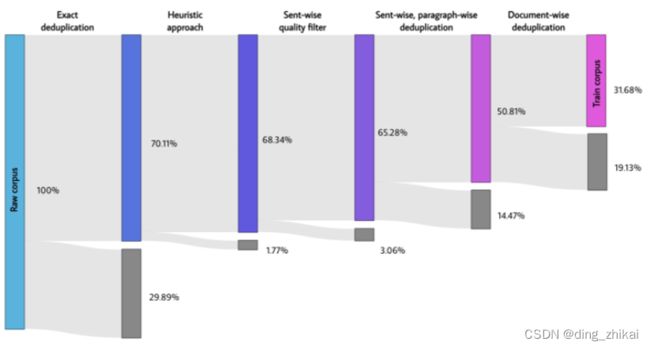
论文图2
4. 模型结构&预训练
4.0 基础结构
-
基于transformer
-
结构&参数 预览

论文表3
4.1 输入
4.1.1 词表
模型 词表 & 文本压缩率

论文表2
- 最大标记长度为32,以考虑长汉语短语
- 百川2分词器的训练数据来自百川2预训练语料库,包含更多样本代码示例和学术论文以提高覆盖率(Taylor等人,2022)。
4.1.2 字符编码
- 使用字节对编码(BPE)(Shibata等人,1999)从SentencePiece(Kudo和Richardson,2018)。
- 不对接收的文本进行任何归一化。
- 没有像baichuan 1中那样 添加哑令牌前缀。
- 将数字拆分为单个数字,以更好地编码数值数据。
- 为了处理包含多余空格的代码数据,Tokenizer添加了仅包含空格的标记。
- 字符覆盖率设置为0.9999。
- 罕见字符退化到UTF-8字节。
4.1.3 位置编码
- 白川2-7B:使用旋转位置嵌入(RoPE)(Su等人,2021) 。
- 白川2-13B:使用ALiBi (Press等人,2021)。
4.2 中间结构
4.2.1 激活函数
- 基本结构:SwiGLU(Shazeer,2020)激活函数
- 论文修改:调整了隐藏层大小
(注:原文“然而,SwiGLU 具有一个“双线性”层,并且包含三个参数矩阵,不同于具有两个矩阵的标准变压器前馈层,因此我们将隐藏大小从隐藏大小的四倍减少到83个隐藏大小,并四舍五入为128的乘积。”)
4.2.2 注意力层
采用了由 xFormers2 实现的内存高效的注意力(Rabe 和 Staats,2021)
(注:原文“通过利用 xFormers 具有偏差能力的优化注意力,我们可以高效地合并 ALiBi 的基于偏差的位置编码,同时减少内存开销。这为 Baichuan2 的大规模训练提供了性能和效率方面的优势。”)
4.2.3 归一化层
4.2.3.1 层归一化
RMS-LN(不去中心的 层归一化)
4.2.3.2 归一化头 NormHead
对输出embeddings(也称为“头”)进行了归一化。
理由如下:
- 显著地稳定训练过程
(注:原文“在我们的预研工作中,我们发现头部的范数容易不稳定。在训练过程中,稀有标记的嵌入范数变小,扰乱了训练动力学”) - 缓解欧氏距离对语义的干扰
(注:原文“我们发现语义信息主要由嵌入的余弦相似度编码,而不是L2距离。由于当前线性分类器通过点积计算 logit,它是L2距离和余弦相似度的混合。归一化头缓解了在线性分类器中计算logit时L2距离的干扰。”)
有无 NormHead, 对训练过程的影响:
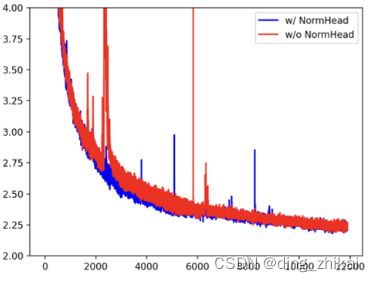
论文图9
4.3 预训练
4.3.0 损失
最大z损失(max-z loss)
(注:原文“通过这种方式收缩非常大的对数可以显著改变softmax之后的概率,使模型对重复惩罚超参数的选择变得敏感。受NormSoftmax(Jiang等人,2023年b)和PaLM(Chowdhery等人,2022年)的辅助z损失的启发,我们在对数上添加了一个最大z损失来归一化对数”)

论文公式1
4.3.1 优化器
- AdamW(Loshchilov和Hutter,2017)优化器
- 参数设置
– β1 和 β2 分别设置为0.9和0.95
– 使用0.1的权重衰减,并对梯度范数截断到0.5
– 通过2,000个线性步长进行预热,达到最大学习率,然后应用余弦退火至最小学习率
4.3.2 数据精度
BFloat16混合精度
(注:原文“与Float16相比,BFloat16具有更好的动态范围,使其在训练大型语言模型时对大值更加稳健。然而,BFloat16 的低精度会在某些情况下造成问题。例如,在一些公共RoPE 和ALibi实现中,当整数超过256时, torch.arange 操作会因碰撞而失败,导致无法区分附近的位置。因此,我们在一些对数值敏感的操作(如位置嵌入)上使用全精度。”)
4.3.3 预训练损失变化
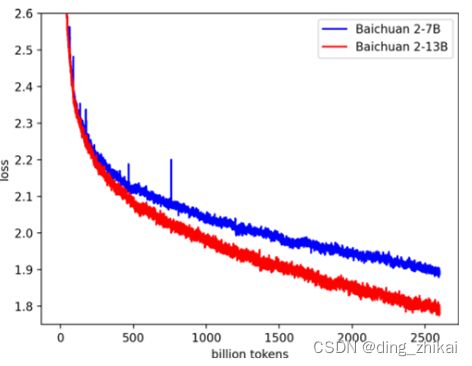
论文图3
4.4 通过缩放得到大模型
- 神经网络的规模法则:误差随着训练集大小、模型大小或两者同时增加而呈幂次方下降。
- 文章使用了Henighan等人(2020年)给出的公式,拟合的缩放法则高精度地预测了Baichuan 2 (7B、13B)的最终损失。

论文图4
5. 后续训练:SFT & RLHF
5.1 SFT: 监督微调
收集了超过10万个监督微调样本。
收集过程如下:
- 使用人工标注者对来自各种数据源的提示进行注释。
- 每个提示都根据类似于克劳德(2023)的关键原则被标记为有用或无害。
- 使用交叉验证来验证数据质量(一个权威的注释者会检查由特定的众包工人组注释的样本批次的质量,并拒绝任何不符合我们的质量标准的批次)。
5.2 RLHF: 从人类反馈中强化学习
5.2.1 RLHF过程示意图
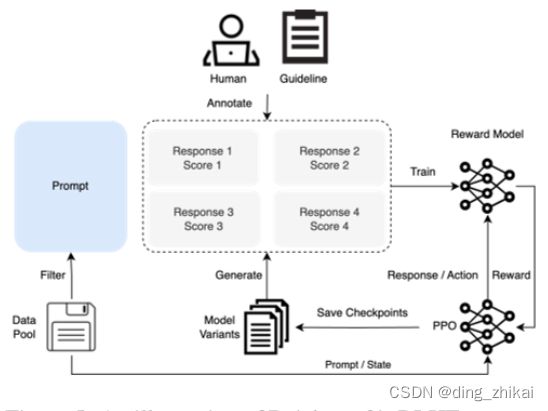
论文图5
5.2.2 奖励模型 (Reward Model, RM)
- 为所有提示设计了一个三层次的分类系统,由6个主要类别、30个次要类别和超过200个三级类别组成。
- 在奖励训练中,仅使用 Baichuan 2 模型家族生成的响应。(注:原文“来自其他开源数据集和专有模型的响应不会提高奖励模型的准确性。这也从另一个角度强调了 Baichuan 系列模型的内在一致性。”)
- 用于训练奖励模型的损失函数与 InstructGPT (Ouyang 等人,2022) 中的一致。
5.2.3 PPO
获得奖励模型后,使用PPO(Schulman等人,2017年)算法训练语言模型。
使用四个模型:
- 演员模型(负责生成响应)the actor model,
- 参考模型(用于计算具有固定参数的KL惩罚)the reference model,
- 奖励模型(为整个响应提供总体奖励,并且具有固定参数)the reward model,
- 评论家模型(设计用于学习每个标记值)critic model。
5.2.4 RLHF 训练细节
(1)步骤
- 20步训练对批评家模型进行预热。
- 使用标准PPO算法更新了批评者和演员模型。
(2)参数
- 梯度裁剪值为0.5
- 恒定学习率为5e-6
- PPO剪切阈值e = 0.1
- KL惩罚系数β设置为0.2,并在步骤中衰减到0.005
- 所有的聊天模型训练了350个周期
(3)产物
“百川2-7B聊天”、“百川2-13B聊天”
6. 数据毒性
6.1 预训练阶段
- 设计了一套规则和模型来消除有害的内容,如暴力、色情、种族歧视、仇恨言论等
- 从数百个权威网站中精心挑选了数百万网页的双语数据集,这些网站代表了各种正面价值领域,包括政策、法律、弱势群体、一般价值观、传统美德等等。提高了此数据集的采样概率
6.2 SFT & RLHF 阶段
-
专家团队:拥有传统互联网安全经验的10人专家注释团队
-
标注团队:专家注释团队通过初始对齐模型引导一个外包的50人的注释团队
-
数据构造方式:
– 标注:标注团队进行红蓝对抗
– 采样:多值监督采样方法
– DPO (Rafailov等人,2023年)方法:有效地利用了有限数量的标记数据来提高针对特定漏洞问题的性能
– 模型:融合有益目标和无害目标的奖励模型 -
数据种类:包括六种攻击类型和100多个粒度安全价值类别
-
数据量:
– 专家标注:1K个注释的数据用于初始化,
– 标注团队:20万个攻击提示
6.3 评估
6.3.1 Toxigen(Hartvigsen等人,2022)数据集
- Toxigen(Hartvigsen等人,2022)数据集评估预训练模型的安全性
(注:原文“使用清理过的来自SafeNLP项目8的版本,对13个少数族裔群体进行区分中立和仇恨类型,形成一个与原始Toxigen提示格式一致的6-shots数据集。我们的解码参数使用温度为0.1和top-p 0.9nucleus采样。”) - 测试结果:

论文表8
6.3.2 百川无害评价数据集(BHED)
-
数据类别(7类)
– 偏见/歧视:涵盖各种形式,如国籍、种族、肤色、群体、职业、性别、地区、行业等,以确保数据多样性。
– 侮辱/亵渎:包括明确和隐含的侮辱以及网络言语虐待。
– 非法/不道德的内容:包括刑法、民法、经济法、国际法、交通法规、地方行政法规等。
– 身体健康:包括健康知识、医疗建议以及与身体健康相关的歧视。
– 心理健康:包括情感健康、认知和社会健康、自尊和自我价值、应对压力和适应能力、心理建议以及针对有心理健康问题的群体的歧视。
– 财务隐私:包括房地产、个人债务、银行信息、收入、股票推荐等。隐私包括个人信息、家庭信息、职业信息、联系方式、私生活等。
– 敏感话题:包括种族仇恨、 国际政治问题、 法律漏洞, -
测试结果:
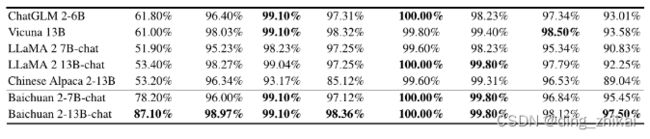
论文表9
7. ckpt
- 将发布 7B 模型的中间检查点
- 从 2200 亿个标记的检查点到 2640 亿个标记的检查点
- 部分ckpt的评估
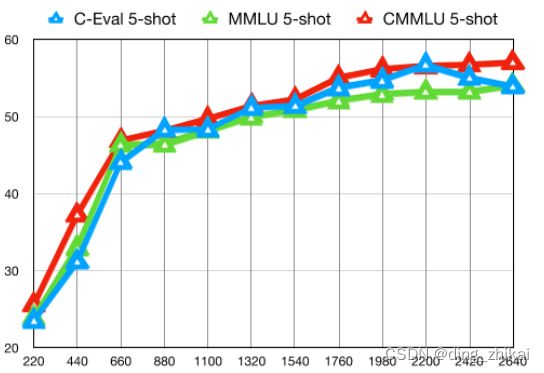
论文图7
8. 设备
以下整理自原文:
设计了一种弹性训练框架的协同设计方法以及智能集群调度策略。训练框架的主要设计标准是机器级别的弹性,它支持动态修改任务资源。系统能够在 1,024 台 NVIDIA A800GPU 上高效地训练白川2-7B 和白川2-13B 模型,计算效率超过 180 TFLOPS。
- 为了满足需求,训练框架集成了张量并行(Narayanan等人,2021)和ZeRO驱动的数据并行(Rajbhandari等人,2020):在每台机器中设置张量并行,并使用ZeRO共享数据并行来实现跨机器的弹性扩展。
- 此外,使用张量拆分技术(Nie等人,2022),将某些计算拆分为减少峰值内存消耗,例如大词汇表的交叉熵计算。这种方法能在不增加计算和通信的情况下满足内存需求,从而使系统更有效率。
- 为了进一步加速训练,同时不损失模型精度,我们实现了混合精度训练,在其中我们在Bfloat16中执行前向和反向计算,而在浮点数32中进行优化器更新。
- 为了有效地将我们的训练集群扩展到数千个 GPU,我们集成了以下技术来避免通信效率的降低:(1)考虑拓扑结构的分布式训练。(2)ZeRO的混合和分层分区。