python命令大全及说明文档,python命令大全及说明
大家好,本文将围绕python命令大全及说明文档展开说明,python命令大全及说明是一个很多人都想弄明白的事情,想搞清楚python命令大全及效果需要先了解以下几个事情。

Source code download: 本文相关源码
1.变量类型
(1)数字数据类型用于存储数值。他们是不可改变的数据类型,这意味着改变数字数据类型的值会分配一个新的对象python画皮卡丘。有四种类型:int(有符号整型)long(长整型[也可以代表八进制和十六进制])float(浮点型)complex(复数)。
(2)字符串或串(String)是由数字、字母、下划线组成的一串字符。一般记为 :s="a1a2···an"(n>=0)。可以使用 [头下标:尾下标] 来截取相应的字符串。对字符串进行截取并通过+其他字符串进行连接
(3)列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。列表用 [ ] 标识。列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表。len(list)表示列表的长度,list.pop()返回列表最右边值,并在列表中删除
(4)元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表
2.可执行语句
(1) if else
(2)while … else 在循环条件为 false 时执行 else 语句块。
(3) for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
for letter in 'Python': # 第一个实例
print '当前字母 :', letter
(4)将Python中的所有字母输出。
(5)for … else 表示这样的意思,for 中的语句和普通的没有区别,else 中的语句会在循环正常执行完(即 for 不是通过 break 跳出而中断的)的情况下执行,while … else 也是一样。
(6)如果您使用嵌套循环,break语句将停止执行最深层的循环,并开始执行下一行代码。
(7)Python pass 是空语句,是为了保持程序结构的完整性。pass 不做任何事情,一般用做占位语句。
(8)捕捉异常可以使用try/except语句。try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。try语句块出现错误后,python就跳回到try并执行第一个匹配该异常的except子句,异常处理完毕,控制流就通过整个try语句
3. python中的数字
(1) Python 中数学运算常用的函数基本都在 math 模块、cmath 模块中。Python math 模块提供了许多对浮点数的数学运算函数。Python cmath 模块包含了一些用于复数运算的函数。
(2) Python中还包含数字函数、随机函数、数学常量π等
4.python中的字符
(1) 在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符,如\n,\f
Python字符串运算符,+,*,in,not in
(2)string模块包含了字符串常用方法
(3)Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串。
str = "-";
seq = ("a", "b", "c"); # 字符串序列
print str.join( seq );
结果是a-b-c
(4)[ : ] 截取字符串中的一部分,遵循左闭右开原则,str[0,2] 是不包含第 3 个字符的。
5.python中的列表
(1)列表的数据项不需要具有相同的类型。创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。
list1 = ['physics', 'chemistry', 1997, 2000]
list2 = [1, 2, 3, 4, 5 ]
list3 = ["a", "b", "c", "d"]
(2)使用append()方法来添加列表项,可以使用 del 语句来删除列表的元素del list1[2]
(3)列表对 + 和 *的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
(4)列表的函数,len(list),max(list),min(list),cmp(list0,list1),list(seq)将元祖装换成列表
list.append(obj)在列表末尾添加新的对象 list.count(obj) 统计某个元素在列表中出现的次数
list.index(obj)从列表中找出某个值第一个匹配项的索引位置
list.pop([index=-1])移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
list.index(obj)从列表中找出某个值第一个匹配项的索引位置
(5)extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。 extend()方法语法:list.extend(seq)
aList = [123, 'xyz', 'zara', 'abc', 123];
bList = [2009, 'manni'];
aList.extend(bList)
print "Extended List : ", aList ;
Extended List : [123, ‘xyz’, ‘zara’, ‘abc’, 123, 2009, ‘manni’]
(6) list(seq) 将元组转换为列表
dict.values() 以列表返回字典中的所有值
list(dict.values())
(7)判断list中全部为1个值
6.python中的字典
(1)字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中,d = {key1 : value1, key2 : value2 }
del dict['Name'] # 删除键是'Name'的条目
dict.clear() # 清空字典所有条目
del dict # 删除字典
(2)字典值可以没有限制地取任何python对象,既可以是标准的对象,也可以是用户定义的,但键不行,键必须不可变,所以可以用数字,字符串或元组充当,所以用列表就不行。
(3)字典的函数:cmp(dict1, dict2), len(dict),str(dict), dict.keys()以列表返回一个字典所有的键,dict.items() 以列表返回可遍历的(键, 值) 元组数组
7.python中的日期和时间
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。Python 的 time 模块下有很多函数可以转换常见日期格式。如函数time.time()用于获取当前时间戳
8.python中的函数
(1)函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
(2)函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
(3)任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
(4)函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
(5)函数内容以冒号起始,并且缩进。
(6)return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
(7)在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象。python的参数可以是可变类型的,也可以是不可变类型的,执行过程不一样。
9.python中的模块
(1)模块能定义函数,类和变量,模块里也能包含可执行的代码。模块定义好后,我们可以使用 import 语句来引入模块
(2)Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中。要导入模块 fib 的 fibonacci 函数,使用如下语句:from fib import fibonacci
(3)dir() 函数一个排好序的字符串列表,内容是一个模块里定义过的名字。返回的列表容纳了在一个模块里定义的所有模块,变量和函数。
10.python的文件I/O
(1)Python 提供了必要的函数和方法进行默认情况下的文件基本操作。你可以用 file 对象做大部分的文件操作。先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
fo = open("foo.txt", "w")
print "文件名: ", fo.name
print "是否已关闭 : ", fo.closed
print "访问模式 : ", fo.mode
print "末尾是否强制加空格 : ", fo.softspace
(2)当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
(3)write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
# 打开一个文件
fo = open("foo.txt", "w")
fo.write( "www.runoob.com!\nVery good site!\n")
# 关闭打开的文件
fo.close()
(4)文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:所以open完后必须close,但是由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try … finally来实现:
try:
f = open('/path/', 'r')
print(f.read())
finally:
if f:
f.close()
Python引入了with语句来自动帮我们调用close()方法,这和前面的try … finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。
with open('/path/to/file', 'r') as f:
print(f.read())
(5)读取文件内容
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for… in … 结构进行处理。如果碰到结束符 EOF 则返回空字符串。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开文件
fo = open("runoob.txt", "r")
print "文件名为: ", fo.name
for line in fo.readlines(): #依次读取每行
line = line.strip() #去掉每行头尾空白
print "读取的数据为: %s" % (line)
# 关闭文件
fo.close()
文件名为: runoob.txt
读取的数据为: 1:www.runoob.com
读取的数据为: 2:www.runoob.com
读取的数据为: 3:www.runoob.com
读取的数据为: 4:www.runoob.com
读取的数据为: 5:www.runoob.com
11.python中常用的模块介绍
(1)os 模块提供了非常丰富的方法用来处理文件和目录。
1)rename()方法需要两个参数,当前的文件名和新文件名。
import os
# 重命名文件test1.txt到test2.txt。
os.rename( "test1.txt", "test2.txt" )
2)remove()方法删除文件,需要提供要删除的文件名作为参数。
import os
# 删除一个已经存在的文件test2.txt
os.remove("test2.txt")
3)mkdir()方法在当前目录下创建新的目录们
import os
# 创建目录test
os.mkdir("test")
4)chdir()方法来改变当前的目录。chdir()方法需要的一个参数是你想设成当前目录的目录名称
import os
# 将当前目录改为"/home/newdir"
os.chdir("/home/newdir")
5)getcwd()方法显示当前的工作目录。
6)rmdir()方法删除目录,目录名称以参数传递。
7)os.path 模块主要用于获取文件的属性。
os.path.exists(path) 如果路径 path 存在,返回 True;如果路径 path 不存在,返回 False
os.path.abspath(path) 返回绝对路径
os.path.basename(path) 返回文件名
8)Execute the command (a string) in a subshell. This is implemented by calling the Standard C function system(), and has the same limitations. Changes to sys.stdin, etc. are not reflected in the environment of the executed command.
system函数可以将字符串转化成命令在服务器上运行;其原理是每一条system函数执行时,其会创建一个子进程在系统上执行命令行,子进程的执行结果无法影响主进程
9)分立文件名、扩展名和路径
import os
file_path = "D:/test/test.py"
(filepath, tempfilename) = os.path.split(file_path)
(filename, extension) = os.path.splitext(tempfilename)
(2) argparse
1)命令
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("echo")
args = parser.parse_args()
print args.echo
The ArgumentParser object will hold all the information necessary to parse the command line into Python data types。import后第一句用来创建一个ArgumentParser object。
add_argument方法用来说明这个python脚本程序可以接受的命令行选项,在上面的例子中,将这个操作命令为“echo”。调用这个python脚本程序时要求我们可以声明一个选项。
parse_args方法当操作执行后从指定的选项返回数据,当执行python python_name foo打印foo
2)add_argument方法
1》选项包含位置选项指定了一定要有,和可选选项(执行命令时可以有也可以没有)
2》由于argparse将输入的参数均视为strings类型,而有时我们需要的是int类型,如下操作 parser.add_argument("square", help="display a square of a given number",type=int)
3》可选命令:可以出现在命令行也可以不出现在命令行中。
当没加action==“store_true”,必须在–verbosity后面加一些值,–verbosity可以用任何用户定义的字符串代替。
当加了action==“store_true”,–verbosity后面必须不能加东西。parser.add_argument("--verbose", help="increase output verbosity", action="store_true")
action=store_ture/store_false 保存相应的布尔值,args.verbose的值为true
4》短选项
-v和上面的–verbosity一样,加没加action=“store_true”行为不一样,parser.add_argument("-v", "--verbose", help="increase output verbosity", action="store_true")。且-v也是可选的。
12 系统函数
只要程序在执行过程中调用到exit()函数,程序立即终止运行。exit()函数常用在程序错误时退出结束或调试代码
13 获取外部参数
Sys.argv[ ]其实就是一个列表,里边的项为用户输入的参数,关键就是要明白这参数是从程序外部输入的,而非代码本身的什么地方
如执行test.py 0指代码(即此.py程序)本身的意思
14 常用函数
class int(x, base=10) x – 字符串或数字 base – 进制数,默认十进制
int(‘12’,16) # 如果是带参数base的话,12要以字符串的形式进行输入,12 为16进制
15 numpy
1 arange
numpy.arange(start, stop, step, dtype = None)在给定间隔内返回均匀间隔的值。
值在半开区间 [开始,停止]内生成(换句话说,包括开始但不包括停止的区间),返回的是 ndarray 。
start —— 开始位置,数字,可选项,默认起始值为0
stop —— 停止位置,数字
step —— 步长,数字,可选项, 默认步长为1,如果指定了step,则还必须给出start。
dtype —— 输出数组的类型。 如果未给出dtype,则从其他输入参数推断数据类型。
2 empty
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
numpy.empty(shape, dtype = float, order = ‘C’)
import numpy as np
x = np.empty([3,2], dtype = int)
print (x)
结果:
[[ 6917529027641081856 5764616291768666155]
[ 6917529027641081859 -5764598754299804209]
[ 4497473538 844429428932120]]
16 pandas
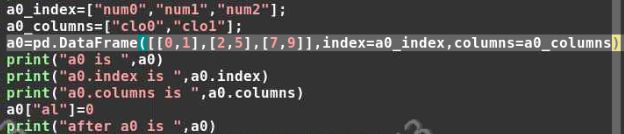
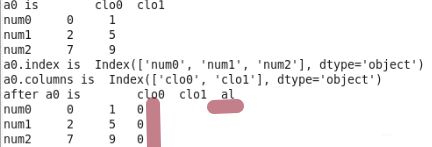
a0[“al”]=0,在dataframe中加入了一个名为al的column
17 将字符串转化成字典
(1)方式一:使用json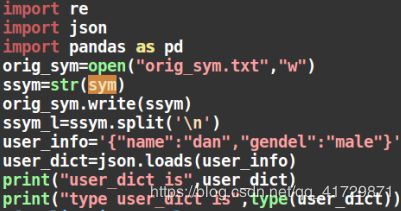

(2)方式二使用eval函数

18 查看数据类型
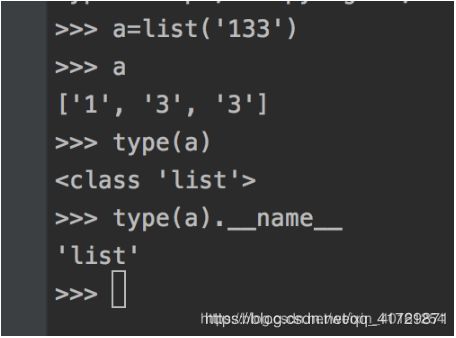
19 列表转换成字典
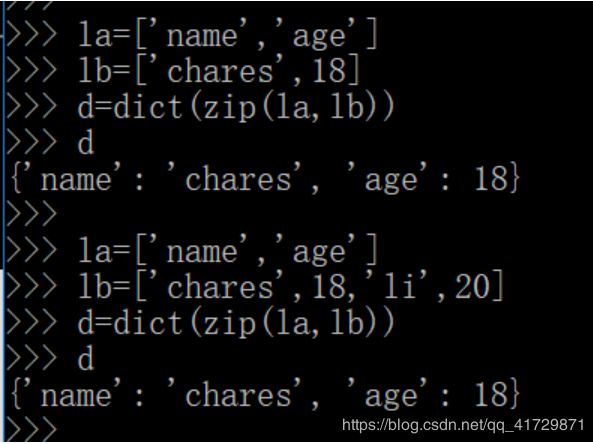
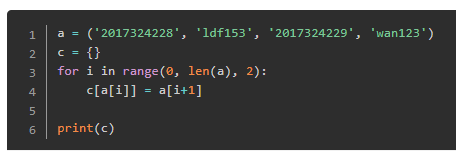
print打印多个变量
20 正则表达式

21 print所有的dataframe或者series,不会用…省略

22 两个series合并成一个
用pandas自带的concat命令可以实现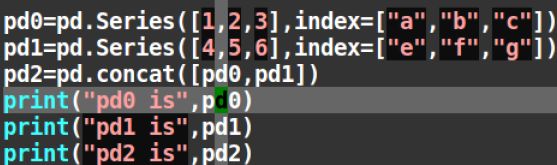
参考:
https://www.cnblogs.com/liyujie1978/p/9542495.html
https://blog.csdn.net/weixin_40161254/article/details/84613902
https://junyiseo.com/python/215.html
https://blog.csdn.net/qq_42110481/article/details/81104182