Hotspot 垃圾回收之ConcurrentMarkSweepGeneration(二) 源码解析
目录
一、ModUnionClosure / ModUnionClosurePar
二、CMSIsAliveClosure / CMSParKeepAliveClosure
三、CFLS_LAB
1、构造方法和modify_initialization
2、alloc
3、retire
4、 compute_desired_plab_size
四、ConcurrentMarkSweepGeneration
1、定义
2、构造方法和ref_processor_init
3、 ConcGCThreads / ParallelGCThreads
本篇博客继续上一篇《Hotspot 垃圾回收之ConcurrentMarkSweepGeneration(一) 源码解析》讲解其他相关类的实现和使用。
一、ModUnionClosure / ModUnionClosurePar
这两个类的定义都在concurrentMarkSweepGeneration.hpp中,用来遍历MemRegion,将其在BitMap对应的内存区域打标,其类继承关系如下:
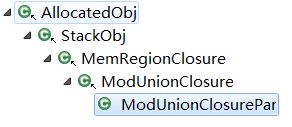
其核心do_MemRegion方法的实现如下:
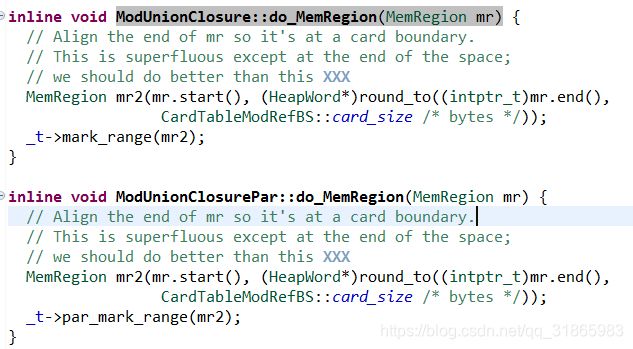
_t就是构造方法传入的CMSBitMap指针。
二、CMSIsAliveClosure / CMSParKeepAliveClosure
CMSIsAliveClosure用于判断某个对象是否是存活的,CMSParKeepAliveClosure用于将某个对象标记成存活的,底层都是依赖于BitMap,其实现如下:
CMSIsAliveClosure(MemRegion span,
CMSBitMap* bit_map):
_span(span), //span表示老年代对应的内存区域
_bit_map(bit_map) //CMSBitMap引用
{
assert(!span.is_empty(), "Empty span could spell trouble");
}
bool CMSIsAliveClosure::do_object_b(oop obj) {
HeapWord* addr = (HeapWord*)obj;
//BitMap中打标则认为其是存活的
return addr != NULL &&
(!_span.contains(addr) || _bit_map->isMarked(addr));
}
CMSParKeepAliveClosure::CMSParKeepAliveClosure(CMSCollector* collector,
MemRegion span, CMSBitMap* bit_map, OopTaskQueue* work_queue):
_span(span), //老年代对应的内存区域
_bit_map(bit_map), //老年代的BitMap
_work_queue(work_queue), //执行任务的队列
_mark_and_push(collector, span, bit_map, work_queue), //CMSInnerParMarkAndPushClosure实例
_low_water_mark(MIN2((uint)(work_queue->max_elems()/4),
//CMSWorkQueueDrainThreshold表示CMSWorkQueue的阈值,默认是10
(uint)(CMSWorkQueueDrainThreshold * ParallelGCThreads))) //_work_queue的最大容量
{ }
void CMSKeepAliveClosure::do_oop(oop* p) { CMSKeepAliveClosure::do_oop_work(p); }
void CMSKeepAliveClosure::do_oop(narrowOop* p) { CMSKeepAliveClosure::do_oop_work(p); }
void CMSParKeepAliveClosure::do_oop(oop obj) {
HeapWord* addr = (HeapWord*)obj;
//如果addr在老年代中且没有打标
if (_span.contains(addr) &&
!_bit_map->isMarked(addr)) {
//如果打标成功,因为其他线程可能已经完成打标了,所以可能返回false
if (_bit_map->par_mark(addr)) {
//将obj放入队列中
bool res = _work_queue->push(obj);
assert(res, "Low water mark should be much less than capacity");
//如果_work_queue中的oop超过指定容量了,则处理一部分
trim_queue(_low_water_mark);
} // Else, another thread got there first
}
}
void CMSParKeepAliveClosure::trim_queue(uint max) {
//如果待处理的oop过多
while (_work_queue->size() > max) {
oop new_oop;
//弹出一个待处理的oop
if (_work_queue->pop_local(new_oop)) {
assert(new_oop != NULL && new_oop->is_oop(), "Expected an oop");
assert(_bit_map->isMarked((HeapWord*)new_oop),
"no white objects on this stack!");
assert(_span.contains((HeapWord*)new_oop), "Out of bounds oop");
//遍历该oop所引用的其他oop
new_oop->oop_iterate(&_mark_and_push);
}
}
}
三、CFLS_LAB
CFLS_LAB定义在同目录下的compactibleFreeListSpace.hpp中,是老年代并行GC下本地线程的内存分配缓存,其包含的属性如下:
- CompactibleFreeListSpace* _cfls; //关联的CompactibleFreeListSpace实例
- AdaptiveFreeList
_indexedFreeList[CompactibleFreeListSpace::IndexSetSize]; //缓存的不同大小的FreeList数组 - static AdaptiveWeightedAverage _blocks_to_claim [CompactibleFreeListSpace::IndexSetSize]; //用来动态调整不同大小的FreeList中包含的FreeChunk内存块的个数
- static size_t _global_num_blocks [CompactibleFreeListSpace::IndexSetSize];//这两个属性用于promote结束后统计不同大小剩余的FreeChunk的个数和曾经获取对应大小的FreeChunk的GC线程数,是_blocks_to_claim用来动态调整填充FreeList时填充的FreeChunk的个数
- static uint _global_num_workers[CompactibleFreeListSpace::IndexSetSize];
- size_t _num_blocks [CompactibleFreeListSpace::IndexSetSize]; //用来记录不同大小的FreeList所包含的FreeChunk内存块的个数
重点关注以下方法的实现。
1、构造方法和modify_initialization
modify_initialization是当命令行显示修改了CMSParPromoteBlocksToClaim或者OldPLABWeight的默认值时才会调用,其调用链如下:

该方法修改的是静态属性_blocks_to_claim,所以可以在启动时执行,Arguments::set_cms_and_parnew_gc_flags方法中的调用如下图:

两者的实现如下:
CFLS_LAB::CFLS_LAB(CompactibleFreeListSpace* cfls) :
_cfls(cfls)
{
assert(CompactibleFreeListSpace::IndexSetSize == 257, "Modify VECTOR_257() macro above");
//CompactibleFreeListSpace::set_cms_values方法把IndexSetStart初始化成MinChunkSize,IndexSetStride初始化成MinObjAlignment
for (size_t i = CompactibleFreeListSpace::IndexSetStart;
i < CompactibleFreeListSpace::IndexSetSize;
i += CompactibleFreeListSpace::IndexSetStride) {
_indexedFreeList[i].set_size(i);
_num_blocks[i] = 0;
}
}
static bool _CFLS_LAB_modified = false;
//实际调用时n传入的是OldPLABSize,wt传入的是OldPLABWeight
//OldPLABSize表示老年代中用于promotion的LAB的大小,默认值是1024
//OldPLABWeight表示重置CMSParPromoteBlocksToClaim时指数衰减的百分比,默认值是50
//CMSParPromoteBlocksToClaimb表示并行GC时重新填充LAB需要声明的内存块的个数
void CFLS_LAB::modify_initialization(size_t n, unsigned wt) {
assert(!_CFLS_LAB_modified, "Call only once");
_CFLS_LAB_modified = true;
for (size_t i = CompactibleFreeListSpace::IndexSetStart;
i < CompactibleFreeListSpace::IndexSetSize;
i += CompactibleFreeListSpace::IndexSetStride) {
_blocks_to_claim[i].modify(n, wt, true /* force */);
}
}
#define VECTOR_257(x) \
/* 1 2 3 4 5 6 7 8 9 1x 11 12 13 14 15 16 17 18 19 2x 21 22 23 24 25 26 27 28 29 3x 31 32 */ \
{ x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, x, \
x }
//初始化
AdaptiveWeightedAverage CFLS_LAB::_blocks_to_claim[] =
VECTOR_257(AdaptiveWeightedAverage(OldPLABWeight, (float)CMSParPromoteBlocksToClaim));
size_t CFLS_LAB::_global_num_blocks[] = VECTOR_257(0);
uint CFLS_LAB::_global_num_workers[] = VECTOR_257(0);
构造方法的调用链如下:

2、alloc
alloc方法用于分配指定大小的内存,如果大于IndexSetSize则尝试从_dictionary中分配,否则从本地的对应大小的FreeList中分配,如果对应FreeList中的空闲内存块的个数为0,则重新填充。其实现如下:
HeapWord* CFLS_LAB::alloc(size_t word_sz) {
FreeChunk* res;
assert(word_sz == _cfls->adjustObjectSize(word_sz), "Error");
if (word_sz >= CompactibleFreeListSpace::IndexSetSize) {
//如果超过IndexSetSize,则获取_parDictionaryAllocLock锁,从_dictionary中分配
MutexLockerEx x(_cfls->parDictionaryAllocLock(),
Mutex::_no_safepoint_check_flag);
res = _cfls->getChunkFromDictionaryExact(word_sz);
//分配失败返回NULL
if (res == NULL) return NULL;
} else {
//获取对应大小的FreeList
AdaptiveFreeList* fl = &_indexedFreeList[word_sz];
if (fl->count() == 0) {
//如果fl是空则尝试重新填充
get_from_global_pool(word_sz, fl);
//填充失败返回Null
if (fl->count() == 0) return NULL;
}
//获取链表头的FreeChunk
res = fl->get_chunk_at_head();
assert(res != NULL, "Why was count non-zero?");
}
//标记成非空闲的
res->markNotFree();
assert(!res->is_free(), "shouldn't be marked free");
assert(oop(res)->klass_or_null() == NULL, "should look uninitialized");
return (HeapWord*)res;
}
void CFLS_LAB::get_from_global_pool(size_t word_sz, AdaptiveFreeList* fl) {
//获取需要填充的FreeChunk的个数
size_t n_blks = (size_t)_blocks_to_claim[word_sz].average();
assert(n_blks > 0, "Error");
//ResizeOldPLAB表示是否动态调整用于promote的LAB的个数,默认是true
assert(ResizeOldPLAB || n_blks == OldPLABSize, "Error");
//CMSOldPLABResizeQuicker默认为false
if (ResizeOldPLAB && CMSOldPLABResizeQuicker) {
size_t multiple = _num_blocks[word_sz]/(CMSOldPLABToleranceFactor*CMSOldPLABNumRefills*n_blks);
n_blks += CMSOldPLABReactivityFactor*multiple*n_blks;
n_blks = MIN2(n_blks, CMSOldPLABMax);
}
assert(n_blks > 0, "Error");
//从_cfls中申请最多n_blks个指定大小的内存块并放到fl中
_cfls->par_get_chunk_of_blocks(word_sz, n_blks, fl);
//更新_num_blocks中对应大小的内存块的个数
_num_blocks[word_sz] += fl->count();
}
3、retire
retire是promote执行完成后由VMThread调用,用于归还不同大小的FreeList中所有未使用的空闲内存块的,并将对应FreeList和num_blocks重置成初始状态,其实现如下:
void CFLS_LAB::retire(int tid) {
//VMThread 执行GC时才会调用此方法
assert(Thread::current()->is_VM_thread(), "Error");
for (size_t i = CompactibleFreeListSpace::IndexSetStart;
i < CompactibleFreeListSpace::IndexSetSize;
i += CompactibleFreeListSpace::IndexSetStride) {
//_num_blocks只有在填充FreeList才会改变,而count是只要分配出去一个内存块就减1,所以前者大于等于后者
assert(_num_blocks[i] >= (size_t)_indexedFreeList[i].count(),
"Can't retire more than what we obtained");
//_num_blocks等于0的说明未进行填充,对应的FreeList肯定是空的
if (_num_blocks[i] > 0) {
//获取FreeList中剩余的空闲内存块个数
size_t num_retire = _indexedFreeList[i].count();
assert(_num_blocks[i] > num_retire, "Should have used at least one");
{
//累加使用的内存块个数
_global_num_blocks[i] += (_num_blocks[i] - num_retire);
_global_num_workers[i]++;
//因为一个GC线程对应一个CFLS_LAB实例,所以不会超过ParallelGCThreads
assert(_global_num_workers[i] <= ParallelGCThreads, "Too big");
if (num_retire > 0) {
//将剩余的空闲内存块归还到_cfls中对应大小的FreeList中
_cfls->_indexedFreeList[i].prepend(&_indexedFreeList[i]);
// 重置FreeList
_indexedFreeList[i] = AdaptiveFreeList();
_indexedFreeList[i].set_size(i);
}
}
if (PrintOldPLAB) {
gclog_or_tty->print_cr("%d[" SIZE_FORMAT "]: " SIZE_FORMAT "/" SIZE_FORMAT "/" SIZE_FORMAT,
tid, i, num_retire, _num_blocks[i], (size_t)_blocks_to_claim[i].average());
}
//将_num_blocks置为0
_num_blocks[i] = 0;
}
}
}
其调用链如下:

4、 compute_desired_plab_size
compute_desired_plab_size方法会综合某个大小的FreeList的剩余FreeChunk的个数和曾经获取该大小的GC线程的数量以及其他配置参数来动态调整FreeList填充时的填充的FreeChunk的个数,其实现如下:
void CFLS_LAB::compute_desired_plab_size() {
for (size_t i = CompactibleFreeListSpace::IndexSetStart;
i < CompactibleFreeListSpace::IndexSetSize;
i += CompactibleFreeListSpace::IndexSetStride) {
//这两个条件要么同时成立,要么不成立
assert((_global_num_workers[i] == 0) == (_global_num_blocks[i] == 0),
"Counter inconsistency");
if (_global_num_workers[i] > 0) {
//如果大于0,说明有GC线程获取过对应大小的内存块
//ResizeOldPLAB默认值为true
if (ResizeOldPLAB) {
//CMSOldPLABMin的默认值是16,CMSOldPLABMax的默认值是1024,表示CMS下老年代为promote提前分配空闲内存块的个数的最小值和最大值
_blocks_to_claim[i].sample(
MAX2((size_t)CMSOldPLABMin,
MIN2((size_t)CMSOldPLABMax,
_global_num_blocks[i]/(_global_num_workers[i]*CMSOldPLABNumRefills))));
}
//重置成初始状态
_global_num_workers[i] = 0;
_global_num_blocks[i] = 0;
if (PrintOldPLAB) {
gclog_or_tty->print_cr("[" SIZE_FORMAT "]: " SIZE_FORMAT, i, (size_t)_blocks_to_claim[i].average());
}
}
}
}
其调用链如下:

四、ConcurrentMarkSweepGeneration
1、定义
ConcurrentMarkSweepGeneration表示CMS的老年代,其定义同样在concurrentMarkSweepGeneration.hpp中,包含的属性如下:
- static CMSCollector* _collector; //封装了老年代垃圾回收的相关属性和实现逻辑
- CompactibleFreeListSpace* _cmsSpace; //老年代对应的Space实现
- size_t _direct_allocated_words; //直接从老年代分配而非promote时间接分配的内存的大小,是一个累加值,CMSStats使用的
- bool _incremental_collection_failed; //是否增量收集失败,iCMS模式下使用
- CMSParGCThreadState** _par_gc_thread_states; //实际是一个CMSParGCThreadState指针数组,元素个数就是ParallelGCThreads,即并行GC的线程数,CMSParGCThreadState是执行老年代promote时使用的
- CMSExpansionCause::Cause _expansion_cause; //老年代扩展的原因,shouldConcurrentCollect()方法据此判断是否应该GC
- const double _dilatation_factor;
- CollectionTypes _debug_collection_type;
- bool _did_compact; //是否完成压缩
- double _initiating_occupancy;//触发老年代GC的内存占用百分比,是一个两位的小数
CMSExpansionCause表示CMS老年代扩展的原因,其定义如下:

to_string方法返回Cause对应的字符串描述,打印GC日志使用。
CollectionTypes是一个枚举,定义如下:

CMSParGCThreadState是一个简单的数据结构,是执行老年代promote时用来给GC线程提前分配内存使用,相当于GC线程的TLAB,避免每次promote复制对象时都从堆内存中申请空间,提升promote效率,如下:
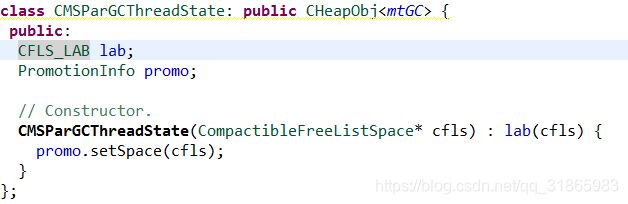
注意CMSParGCThreadState的两个属性都是public的,调用方可以直接访问这两个属性的public方法的。PromotionInfo的讲解参考《Hotspot 垃圾回收之CompactibleFreeListSpace(一) 源码解析》。
CMSCollector的定义在同一个文件中,这两个类密切相关,因此放在一起讲解,其包含的属性如下:
- jlong _time_of_last_gc;
- OopTaskQueueSet* _task_queues; //各GC线程用来保存oop的栈,每个GC线程对应一个OopTaskQueue
- oop _overflow_list;
- Stack
- Stack
- int* _hash_seed; //保存hash种子的int数组,所有元素都是17,初始化_task_queues时使用
- YieldingFlexibleWorkGang* _conc_workers; //并行GC的线程池
- bool _completed_initialization; //用来标记CMSCollector是否完成初始化
- static bool _full_gc_requested; //是否显示的请求(System.gc())导致的Full GC
- static GCCause::Cause _full_gc_cause; //Full GC的原因
- unsigned int _collection_count_start; // GC开始前的Full GC的次数
- bool _should_unload_classes; //表示是否应该卸载Class
- unsigned int _concurrent_cycles_since_last_unload; //表示上一次Class卸载后GC的次数
- int _roots_scanning_options;
- CMSBitMap _verification_mark_bm;
- bool _verifying;
- ConcurrentMarkSweepPolicy* _collector_policy; //老年代GC策略
- elapsedTimer _inter_sweep_timer; // 表示非GC时的计时器
- elapsedTimer _intra_sweep_timer; // 表示GC期间的计时器
- AdaptivePaddedAverage _inter_sweep_estimate;
- AdaptivePaddedAverage _intra_sweep_estimate;
- CMSTracer* _gc_tracer_cm; //GC的跟踪器,打印日志
- ConcurrentGCTimer* _gc_timer_cm; //GC的计时器
- bool _cms_start_registered; //为true已通知GC开始,GC结束后将其置为false
- GCHeapSummary _last_heap_summary; //最近一次GC前的堆内存使用情况
- MetaspaceSummary _last_metaspace_summary; //最近一次GC前的元空间使用情况
- ConcurrentMarkSweepGeneration* _cmsGen; // old gen (CMS)
- MemRegion _span; //老年代对应的内存区域
- CardTableRS* _ct; // card table
- CMSBitMap _markBitMap; //用来标记对象存活的,某个地址打标了则认为该地址上的对象是存活的
- CMSBitMap _modUnionTable; //用来标记脏的卡表项,一个卡表项对应一个位,打标表示该卡表项是脏的
- CMSMarkStack _markStack; //当GC线程对应的OopTaskQueue满了的时候,将待处理的oop放入_markStack中,标记时stack overflow的情形 就是指_markStack也满了
- HeapWord* _restart_addr; // 标记时出现stack overflow的情形,通过_restart_addr来记录重新开始标记的起始位置
- size_t _ser_pmc_preclean_ovflw; //记录PushAndMarkClosure处理survivor区oop的数量
- size_t _ser_pmc_remark_ovflw; //同上,不过PushAndMarkClosure的_concurrent_precleaning属性为false
- size_t _par_pmc_remark_ovflw;
- size_t _ser_kac_preclean_ovflw; //ser就是单线程的意思,par就是并行的意思,该属性用来记录CMSKeepAliveClosure处理Reference实例的数量
- size_t _ser_kac_ovflw; //同上,不过CMSKeepAliveClosure的_concurrent_precleaning属性为false
- size_t _par_kac_ovflw;
- ReferenceProcessor* _ref_processor; //Reference实例的处理器
- CMSIsAliveClosure _is_alive_closure; //ReferenceProcessor使用的判断某个对象是否存活的Closure
- ConcurrentMarkSweepThread* _cmsThread; // the thread doing the work
- ModUnionClosure _modUnionClosure; //用来将指定MemRegion在BitMap中对应的内存打标的Closure
- ModUnionClosurePar _modUnionClosurePar; //同上_modUnionClosure,支持在并发环境下使用
- static CollectorState _collectorState; //当前垃圾回收器的状态,初始为Idling
- bool _between_prologue_and_epilogue; //为true表示CMSCollector::gc_prologue方法已经调用过一次了,不需要二次调用
- static bool _foregroundGCIsActive; //为true,表示前台GC激活了,想要接替CMSThread完成剩下的GC步骤,前台GC由VMThread执行,当_foregroundGCShouldWait为true时,会不断在GC_Lock上等待直到_foregroundGCShouldWait变成false。
- static bool _foregroundGCShouldWait; //为true,表示后台GC正在执行,即CMSThread正在执行某个GC步骤
- bool _abort_preclean; //是否需要abort_preclean,当eden区已使用内存占总内存的50%时,将abort_preclean置为true,参考sample_eden方法的实现
- bool _start_sampling; //是否在preclean时需要采集eden区的top地址,只有CMSEdenChunksRecordAlways为false时才采集,该属性默认为true,在eden区内存分配时就会采集eden区的top地址
- int _numYields;
- size_t _numDirtyCards;
- size_t _sweep_count;
- uint _full_gcs_since_conc_gc; //自上一次conc GC以后的Full GC的总次数
- double _bootstrap_occupancy; //触发第一次老年代GC的内存占用百分比
- elapsedTimer _timer;
- CMSStats _stats; //用来收集内存分配,对象复制等GC的相关数据
- HeapWord* _icms_start_limit; //iCMS模式下使用的年轻代内存分配的起止位置,当年轻代分配内存达到soft_end时会通知老年代,老年代会返回一个新的soft_end地址,并做必要的启停CMS Thread
- HeapWord* _icms_stop_limit;
- Generation* _young_gen; // 年轻代的引用
- HeapWord** _top_addr; // eden区的top属性的地址,top之前的内存都是已经分配出去的
- HeapWord** _end_addr; // eden区的end属性的地址
- Mutex* _eden_chunk_lock; //操作_eden_chunk_array的锁
- HeapWord** _eden_chunk_array; // 用来记录eden区的top地址,即已分配内存区的边界,每次调用allocate方法都会记录分配成功后的top地址,参考CMSCollector::sample_eden_chunk方法
- size_t _eden_chunk_index; // _eden_chunk_array已经使用的元素个数
- size_t _eden_chunk_capacity; // _eden_chunk_array数组的最大容量
- HeapWord** _survivor_chunk_array; //与上面一致,不过是survivor区
- size_t _survivor_chunk_index;
- size_t _survivor_chunk_capacity;
- size_t* _cursor; //保存_survivor_plab_array中单个元素ChunkArray大小的数组
- ChunkArray* _survivor_plab_array; //保存plab的ChunkArray数组,元素个数为ParallelGCThreads
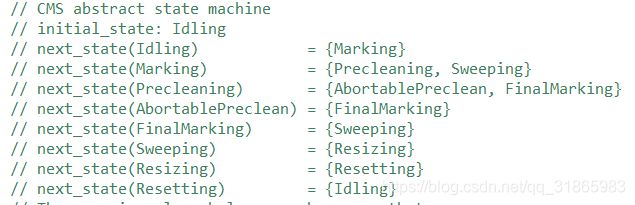
CollectorState是一个描述GC状态的枚举值,其定义如下:

状态的流转如下:
CMSStats就是一个数据结构用来保存CMS内存分配,垃圾回收相关统计数据的,其定义的属性如下:
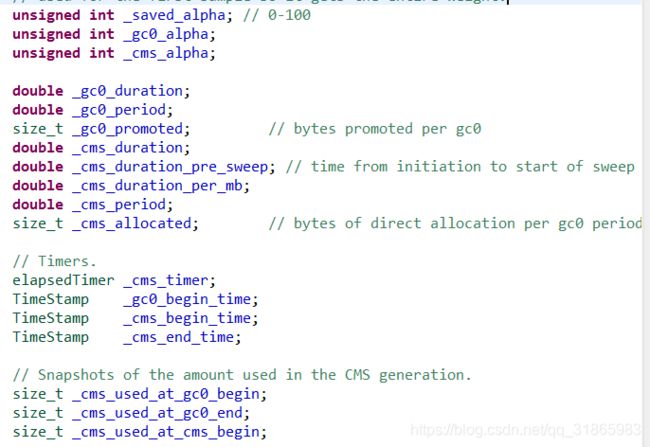
重点关注以下方法的实现
2、构造方法和ref_processor_init
ConcurrentMarkSweepGeneration::ConcurrentMarkSweepGeneration(
ReservedSpace rs, size_t initial_byte_size, int level,
CardTableRS* ct, bool use_adaptive_freelists,
FreeBlockDictionary::DictionaryChoice dictionaryChoice) :
CardGeneration(rs, initial_byte_size, level, ct),
//MinChunkSize在CompactibleFreeListSpace::set_cms_values方法中完成初始化
_dilatation_factor(((double)MinChunkSize)/((double)(CollectedHeap::min_fill_size()))),
_debug_collection_type(Concurrent_collection_type),
_did_compact(false)
{
HeapWord* bottom = (HeapWord*) _virtual_space.low();
HeapWord* end = (HeapWord*) _virtual_space.high();
_direct_allocated_words = 0;
//初始化cmsSpace
_cmsSpace = new CompactibleFreeListSpace(_bts, MemRegion(bottom, end),
use_adaptive_freelists,
dictionaryChoice);
if (_cmsSpace == NULL) {
vm_exit_during_initialization(
"CompactibleFreeListSpace allocation failure");
}
_cmsSpace->_gen = this;
_gc_stats = new CMSGCStats();
if (CollectedHeap::use_parallel_gc_threads()) {
typedef CMSParGCThreadState* CMSParGCThreadStatePtr;
//创建一个CMSParGCThreadStatePtr数组
_par_gc_thread_states =
NEW_C_HEAP_ARRAY(CMSParGCThreadStatePtr, ParallelGCThreads, mtGC);
if (_par_gc_thread_states == NULL) {
vm_exit_during_initialization("Could not allocate par gc structs");
}
//初始化数组元素
for (uint i = 0; i < ParallelGCThreads; i++) {
_par_gc_thread_states[i] = new CMSParGCThreadState(cmsSpace());
if (_par_gc_thread_states[i] == NULL) {
vm_exit_during_initialization("Could not allocate par gc structs");
}
}
} else {
_par_gc_thread_states = NULL;
}
_incremental_collection_failed = false;
assert(MinChunkSize >= CollectedHeap::min_fill_size(), "just checking");
assert(_dilatation_factor >= 1.0, "from previous assert");
}
void ConcurrentMarkSweepGeneration::ref_processor_init() {
assert(collector() != NULL, "no collector");
collector()->ref_processor_init();
}
void CMSCollector::ref_processor_init() {
if (_ref_processor == NULL) {
// Allocate and initialize a reference processor
_ref_processor =
new ReferenceProcessor(_span, // span
(ParallelGCThreads > 1) && ParallelRefProcEnabled, // mt processing,ParallelRefProcEnabled表示是否并行处理Reference,默认为false
(int) ParallelGCThreads, // mt processing degree
_cmsGen->refs_discovery_is_mt(), // mt discovery
(int) MAX2(ConcGCThreads, ParallelGCThreads), // mt discovery degree
_cmsGen->refs_discovery_is_atomic(), // discovery is not atomic
&_is_alive_closure); // closure for liveness info
_cmsGen->set_ref_processor(_ref_processor);
}
}
bool refs_discovery_is_mt() const {
return ConcGCThreads > 1;
}
bool refs_discovery_is_atomic() const { return false; }
static size_t min_fill_size() {
return size_t(align_object_size(oopDesc::header_size()));
}
CompactibleFreeListSpace* cmsSpace() const { return _cmsSpace; }
CMSCollector::CMSCollector(ConcurrentMarkSweepGeneration* cmsGen,
CardTableRS* ct,
ConcurrentMarkSweepPolicy* cp):
_cmsGen(cmsGen),
_ct(ct),
_ref_processor(NULL), // will be set later
_conc_workers(NULL), // may be set later
_abort_preclean(false),
_start_sampling(false),
_between_prologue_and_epilogue(false),
_markBitMap(0, Mutex::leaf + 1, "CMS_markBitMap_lock"), //shifter为0
_modUnionTable((CardTableModRefBS::card_shift - LogHeapWordSize),
-1 /* lock-free */, "No_lock" /* dummy */), //shifter为CardTableModRefBS::card_shift - LogHeapWordSize,前者取值为9,后者取值为3
_modUnionClosure(&_modUnionTable),
_modUnionClosurePar(&_modUnionTable),
_span(cmsGen->reserved()),
_is_alive_closure(_span, &_markBitMap),
_restart_addr(NULL),
_overflow_list(NULL),
_stats(cmsGen),//CMSStats实例,用来收集内存分配,对象复制等GC相关数据
_eden_chunk_lock(new Mutex(Mutex::leaf + 1, "CMS_eden_chunk_lock", true)),
_eden_chunk_array(NULL), // may be set in ctor body
_eden_chunk_capacity(0), // -- ditto --
_eden_chunk_index(0), // -- ditto --
_survivor_plab_array(NULL), // -- ditto --
_survivor_chunk_array(NULL), // -- ditto --
_survivor_chunk_capacity(0), // -- ditto --
_survivor_chunk_index(0), // -- ditto --
_ser_pmc_preclean_ovflw(0),
_ser_kac_preclean_ovflw(0),
_ser_pmc_remark_ovflw(0),
_par_pmc_remark_ovflw(0),
_ser_kac_ovflw(0),
_par_kac_ovflw(0),
_collection_count_start(0),
_verifying(false),
_icms_start_limit(NULL),
_icms_stop_limit(NULL),
_verification_mark_bm(0, Mutex::leaf + 1, "CMS_verification_mark_bm_lock"),
_completed_initialization(false),
_collector_policy(cp),
_should_unload_classes(CMSClassUnloadingEnabled),//CMSClassUnloadingEnabled表示使用CMS GC算法时是否允许类卸载,默认为true
_concurrent_cycles_since_last_unload(0),
_roots_scanning_options(GenCollectedHeap::SO_None),//根节点扫描的选项
_inter_sweep_estimate(CMS_SweepWeight, CMS_SweepPadding),//CMS_SweepWeight的默认值是75,CMS_SweepPadding的默认值是1
_intra_sweep_estimate(CMS_SweepWeight, CMS_SweepPadding),
_gc_tracer_cm(new (ResourceObj::C_HEAP, mtGC) CMSTracer()),
_gc_timer_cm(new (ResourceObj::C_HEAP, mtGC) ConcurrentGCTimer()),
_cms_start_registered(false)
{
//ExplicitGCInvokesConcurrentAndUnloadsClasses只在CMS下使用,默认为false,为true表示当调用System.gc()就会执行并行GC并且卸载class
if (ExplicitGCInvokesConcurrentAndUnloadsClasses) {
ExplicitGCInvokesConcurrent = true;
}
//设置cmsSpace的_collector属性
_cmsGen->cmsSpace()->set_collector(this);
//获取_markBitMap的锁,完成_markBitMap和_modUnionTable两个CMSBitMap的初始化
{
MutexLockerEx x(_markBitMap.lock(), Mutex::_no_safepoint_check_flag);
if (!_markBitMap.allocate(_span)) {
warning("Failed to allocate CMS Bit Map");
return;
}
assert(_markBitMap.covers(_span), "_markBitMap inconsistency?");
}
{
_modUnionTable.allocate(_span);
assert(_modUnionTable.covers(_span), "_modUnionTable inconsistency?");
}
//MarkStackSize表示markStack的初始容量,默认值是4M,初始化_markStack
if (!_markStack.allocate(MarkStackSize)) {
warning("Failed to allocate CMS Marking Stack");
return;
}
//CMSConcurrentMTEnabled表示是否允许并行GC,默认为true
if (CMSConcurrentMTEnabled) {
//ConcGCThreads表示并行GC的线程数,默认值是0
if (FLAG_IS_DEFAULT(ConcGCThreads)) {
//如果是默认值,则重置,ParallelGCThreads也是表示并行GC的线程数,默认值为0
FLAG_SET_DEFAULT(ConcGCThreads, (ParallelGCThreads + 3)/4);
}
if (ConcGCThreads > 1) {
_conc_workers = new YieldingFlexibleWorkGang("Parallel CMS Threads",
ConcGCThreads, true);
if (_conc_workers == NULL) {
warning("GC/CMS: _conc_workers allocation failure: "
"forcing -CMSConcurrentMTEnabled");
CMSConcurrentMTEnabled = false;
} else {
//初始化多个GC线程
_conc_workers->initialize_workers();
}
} else {
CMSConcurrentMTEnabled = false;
}
}
if (!CMSConcurrentMTEnabled) {
ConcGCThreads = 0;
} else {
//CMSCleanOnEnter选项默认为true,是减少脏的卡表项的优化,如果开启并行GC则重置为false
CMSCleanOnEnter = false;
}
assert((_conc_workers != NULL) == (ConcGCThreads > 1),
"Inconsistency");
{
uint i;
//取ParallelGCThreads和ConcGCThreads的最大值
uint num_queues = (uint) MAX2(ParallelGCThreads, ConcGCThreads);
//CMSParallelRemarkEnabled表示是否允许并行Remark,默认为true
//ParallelRefProcEnabled表示是否允许并行的处理Reference实例,默认为false
if ((CMSParallelRemarkEnabled || CMSConcurrentMTEnabled
|| ParallelRefProcEnabled)
&& num_queues > 0) {
//初始化任务队列
_task_queues = new OopTaskQueueSet(num_queues);
if (_task_queues == NULL) {
warning("task_queues allocation failure.");
return;
}
//初始化一个保存hash种子的数组
_hash_seed = NEW_C_HEAP_ARRAY(int, num_queues, mtGC);
if (_hash_seed == NULL) {
warning("_hash_seed array allocation failure");
return;
}
typedef Padded PaddedOopTaskQueue;
for (i = 0; i < num_queues; i++) {
PaddedOopTaskQueue *q = new PaddedOopTaskQueue();
if (q == NULL) {
warning("work_queue allocation failure.");
return;
}
_task_queues->register_queue(i, q);
}
for (i = 0; i < num_queues; i++) {
_task_queues->queue(i)->initialize();
_hash_seed[i] = 17; // copied from ParNew
}
}
}
//CMSInitiatingOccupancyFraction表示触发老年代垃圾回收时的堆内存占用百分比,即属性initiating_occupancy,默认是-1,如果是-1则使用参数CMSTriggerRatio
//CMSTriggerRatio表示MinHeapFreeRatio的百分比,默认值是80,MinHeapFreeRatio的默认值40,据此算出触发老年代垃圾回收时的堆内存占用百分比
_cmsGen ->init_initiating_occupancy(CMSInitiatingOccupancyFraction, CMSTriggerRatio);
//CMSBootstrapOccupancy表示触发第一次老年代垃圾回收的内存使用量占比,默认值是50
_bootstrap_occupancy = ((double)CMSBootstrapOccupancy)/(double)100;
//Full GC的次数
_full_gcs_since_conc_gc = 0;
//设置collecter属性
ConcurrentMarkSweepGeneration::set_collector(this);
//初始化ConcurrentMarkSweepThread和CGC_lock
_cmsThread = ConcurrentMarkSweepThread::start(this);
assert(cmsThread() != NULL, "CMS Thread should have been created");
assert(cmsThread()->collector() == this,
"CMS Thread should refer to this gen");
assert(CGC_lock != NULL, "Where's the CGC_lock?");
GenCollectedHeap* gch = GenCollectedHeap::heap();
//获取年轻代的引用
_young_gen = gch->prev_gen(_cmsGen);
//年轻代是否支持线性内存分配,DefNewGeneration支持
if (gch->supports_inline_contig_alloc()) {
//获取年轻代的起止地址
_top_addr = gch->top_addr();
_end_addr = gch->end_addr();
assert(_young_gen != NULL, "no _young_gen");
_eden_chunk_index = 0;
//CMSSamplingGrain表示eden区中两个CMS samples之间的最小间隔,默认为4k
//计算eden区容纳的Chunk的个数
_eden_chunk_capacity = (_young_gen->max_capacity()+CMSSamplingGrain)/CMSSamplingGrain;
//初始化一个保存eden区 Chunk地址的数组
_eden_chunk_array = NEW_C_HEAP_ARRAY(HeapWord*, _eden_chunk_capacity, mtGC);
if (_eden_chunk_array == NULL) {
//数组初始化失败,将_eden_chunk_capacity置为0
_eden_chunk_capacity = 0;
warning("GC/CMS: _eden_chunk_array allocation failure");
}
}
assert(_eden_chunk_array != NULL || _eden_chunk_capacity == 0, "Error");
//CMSParallelSurvivorRemarkEnabled表示Survivor区是否允许并行remark,默认为true
//CMSParallelInitialMarkEnabled表示是否使用并行初始标记,默认为true
if ((CMSParallelRemarkEnabled && CMSParallelSurvivorRemarkEnabled) || CMSParallelInitialMarkEnabled) {
const size_t max_plab_samples =
((DefNewGeneration*)_young_gen)->max_survivor_size() / plab_sample_minimum_size();
//初始化三个数组
_survivor_plab_array = NEW_C_HEAP_ARRAY(ChunkArray, ParallelGCThreads, mtGC);
_survivor_chunk_array = NEW_C_HEAP_ARRAY(HeapWord*, 2*max_plab_samples, mtGC);
_cursor = NEW_C_HEAP_ARRAY(size_t, ParallelGCThreads, mtGC);
//如果其中有任何一个初始化失败
if (_survivor_plab_array == NULL || _survivor_chunk_array == NULL
|| _cursor == NULL) {
warning("Failed to allocate survivor plab/chunk array");
if (_survivor_plab_array != NULL) {
FREE_C_HEAP_ARRAY(ChunkArray, _survivor_plab_array, mtGC);
_survivor_plab_array = NULL;
}
if (_survivor_chunk_array != NULL) {
FREE_C_HEAP_ARRAY(HeapWord*, _survivor_chunk_array, mtGC);
_survivor_chunk_array = NULL;
}
if (_cursor != NULL) {
FREE_C_HEAP_ARRAY(size_t, _cursor, mtGC);
_cursor = NULL;
}
} else {
//都初始化成功
_survivor_chunk_capacity = 2*max_plab_samples;
for (uint i = 0; i < ParallelGCThreads; i++) {
//初始化_survivor_plab_array数组,元素类型是ChunkArray
HeapWord** vec = NEW_C_HEAP_ARRAY(HeapWord*, max_plab_samples, mtGC);
if (vec == NULL) {
warning("Failed to allocate survivor plab array");
for (int j = i; j > 0; j--) {
FREE_C_HEAP_ARRAY(HeapWord*, _survivor_plab_array[j-1].array(), mtGC);
}
FREE_C_HEAP_ARRAY(ChunkArray, _survivor_plab_array, mtGC);
FREE_C_HEAP_ARRAY(HeapWord*, _survivor_chunk_array, mtGC);
_survivor_plab_array = NULL;
_survivor_chunk_array = NULL;
_survivor_chunk_capacity = 0;
break;
} else {
ChunkArray* cur =
::new (&_survivor_plab_array[i]) ChunkArray(vec,
max_plab_samples);
assert(cur->end() == 0, "Should be 0");
assert(cur->array() == vec, "Should be vec");
assert(cur->capacity() == max_plab_samples, "Error");
}
}
}
}
assert( ( _survivor_plab_array != NULL
&& _survivor_chunk_array != NULL)
|| ( _survivor_chunk_capacity == 0
&& _survivor_chunk_index == 0),
"Error");
_gc_counters = new CollectorCounters("CMS", 1);
_completed_initialization = true;
_inter_sweep_timer.start(); // start of time
}
void ConcurrentMarkSweepGeneration::init_initiating_occupancy(intx io, uintx tr) {
assert(io <= 100 && tr <= 100, "Check the arguments");
if (io >= 0) {
_initiating_occupancy = (double)io / 100.0;
} else {
_initiating_occupancy = ((100 - MinHeapFreeRatio) +
(double)(tr * MinHeapFreeRatio) / 100.0)
/ 100.0;
}
}
static void set_collector(CMSCollector* collector) {
assert(_collector == NULL, "already set");
_collector = collector;
}
bool GenCollectedHeap::supports_inline_contig_alloc() const {
return _gens[0]->supports_inline_contig_alloc();
}
HeapWord** GenCollectedHeap::top_addr() const {
return _gens[0]->top_addr();
}
HeapWord** GenCollectedHeap::end_addr() const {
return _gens[0]->end_addr();
}
HeapWord** DefNewGeneration::top_addr() const { return eden()->top_addr(); }
HeapWord** DefNewGeneration::end_addr() const { return eden()->end_addr(); }
//返回eden区的最大容量
size_t DefNewGeneration::max_capacity() const {
const size_t alignment = GenCollectedHeap::heap()->collector_policy()->space_alignment();
const size_t reserved_bytes = reserved().byte_size();
return reserved_bytes - compute_survivor_size(reserved_bytes, alignment);
}
size_t CMSCollector::plab_sample_minimum_size() {
//取参数MinTLABSize,默认为2k,如果被改写了依然返回2k
return MAX2(ThreadLocalAllocBuffer::min_size() * HeapWordSize, 2 * K);
} 其调用链如下:



先调用构造方法创建 ConcurrentMarkSweepGeneration实例,然后调用create_cms_collector方法创建CMSCollector实例,CMSCollector的构造方法执行时会将自己设置到ConcurrentMarkSweepGeneration的collector属性。ref_processor_init方法是最后调用的,用来初始化ReferenceProcessor并将其设置到ConcurrentMarkSweepGeneration的_ref_processor属性上。
3、 ConcGCThreads / ParallelGCThreads
第一个参数是指并行标记时的并行线程数,只有CMS和G1使用,第二个参数是指执行引用遍历,promote等GC动作时的并行线程数,各个GC算法都在使用,通常情况前者要小于后者,初始状态下这两个参数都默认为0,参考runtime\globals.hpp中的定义,如下:


搜索ConcGCThreads的调用链,如下:
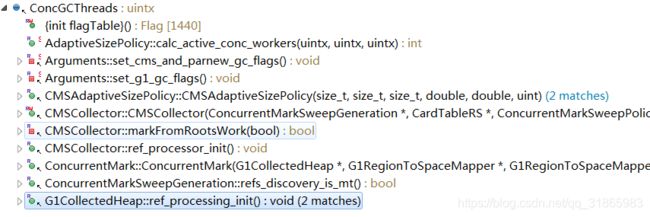
其中修改ConcGCThreads参数的只有一个地方,CMSCollector的构造方法,如下:

即ConcGCThreads如果是默认值0,就会被重置为(ParallelGCThreads + 3)/4。
ParallelGCThreads的调用链很多,这里只截取一部分与CMS相关的,如下:

不同的GC是算法调用的set_flags的方法稍有差异,以set_parallel_gc_flags为例,设置ParallelGCThreads的实现如下:
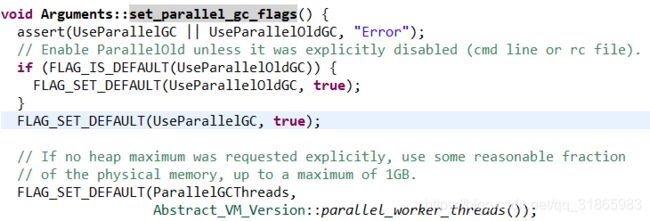
Abstract_VM_Version::parallel_worker_threads方法的实现如下:
unsigned int Abstract_VM_Version::parallel_worker_threads() {
//如果_parallel_worker_threads_initialized未初始化
if (!_parallel_worker_threads_initialized) {
//如果ParallelGCThreads是默认值
if (FLAG_IS_DEFAULT(ParallelGCThreads)) {
_parallel_worker_threads = VM_Version::calc_parallel_worker_threads();
} else {
_parallel_worker_threads = ParallelGCThreads;
}
_parallel_worker_threads_initialized = true;
}
return _parallel_worker_threads;
}
unsigned int Abstract_VM_Version::calc_parallel_worker_threads() {
return nof_parallel_worker_threads(5, 8, 8);
}
unsigned int Abstract_VM_Version::nof_parallel_worker_threads(
unsigned int num,
unsigned int den,
unsigned int switch_pt) {
if (FLAG_IS_DEFAULT(ParallelGCThreads)) {
//如果ParallelGCThreads是默认值,则必须等于0
assert(ParallelGCThreads == 0, "Default ParallelGCThreads is not 0");
//initial_active_processor_count返回当前机器CPU的有效核数
//如果ncpus小于等于8,则返回ncpus,如果大于8,比如72,则返回8 + (72 - 8) * (5/8) == 48
unsigned int ncpus = (unsigned int) os::initial_active_processor_count();
return (ncpus <= switch_pt) ?
ncpus :
(switch_pt + ((ncpus - switch_pt) * num) / den);
} else {
return ParallelGCThreads;
}
}即默认设置下,ParallelGCThreads会自动根据当前机器的CPU核数自动调整,ConcGCThreads会根据ParallelGCThreads自动调整。