【索引的数据结构】第1章节:B+Tree存储结构
目录结构
之前整篇文章太长,阅读体验不好,将其拆分为几个子篇章。
本篇章讲解 B+Tree 存储结构。
什么是索引
可以简单理解为索引好比一本书的目录,通过目录我们可以快速定位到我们要查看的章节。
MySQL 中的数据同样也是根据索引分类,通过索引可以快速高效的查询到我们想要的数据。
索引的优缺点
MySQL 官方对索引的定义:索引(Index)可以帮助 MySQL 高效获取数据的数据结构。
索引的本质:索引是一种数据结构。可以简单理解为索引是一组满足某种特定算法,排好序的快速查找的数据结构, 这种数据结构以某种方式指向数据,这样就可以在这些数据结构的基础上实现高级查找算法。
InnoDB 存储引擎底层默认采用 B+Tree 作为索引的数据结构
先看下二叉搜索树的结构(一个节点存放一条数据):
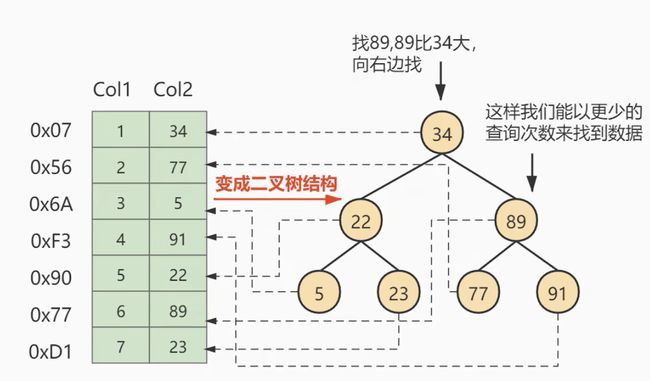
可以理解为 B+Tree 是从二叉搜索树的基础上演变而来的(一个节点存放多条数据)。
建立索引的目的是为了减少磁盘的 I/O 次数,加快查询效率。
索引是在存储引擎中实现的,不同的存储引擎支持的索引类型不一定相同。
存储引擎可以定义每张表的最大索引数和最大索引长度。 所有的存储引擎支持每个表至少 16 个索引,一个索引的长度为 16 个字节,所以支持的最少总索引长度为 256 个字节。
优点
- 提高数据检索效率,
降低数据库磁盘 I/O 成本 - 通过创建唯一索引,可以保证数据库中每一行的
数据的唯一性 加速表和表之间的连接,对于有依赖关系的子表和主表联合查询的时候,可以提高查询速度- 在使用分组和排序进行数据查询时,可以显著
减少查询中分组和排序的时间,大大降低了 CPU 的消耗
缺点
- 增加索引和维护索引要
耗费时间,并且随着数据量的增加,所耗费的时间会越来越大 - 除了数据表要占用空间之外,索引也需要占用
磁盘空间,并且不同的存储引擎,索引和数据的存储位置可能不同,InnoDB 存储引擎是将索引和数据存放在一个以.ibd结尾的文件中,MyISAM 存储引擎将索引和数据分开存储,索引存放在以.myi为结尾的文件中,数据存放在以.myd结尾的文件中 - 虽然索引大大提高了查询速度,但是却会
降低更新表的速度。当表中的数据要进行增删改的时候,索引也要动态维护(要重新动态分组归类排序数据的存储结构),这样就降低了数据的维护速度。
InnoDB 数据存储格式
区分记录
用户记录页和 目录项记录页如何区分?
使用记录头里的record_type属性,各个取值的含义如下:
- 0:普通的用户记录
- 1:目录项记录
- 2:最小记录
- 3:最大记录
假设有一张数据表 test_table有四个字段:c1、c2、c3
create table test_table (
c1 int,
c2 int,
c3 char,
PRIMARY KEY(c1)
) engine=InnoDB
由于页的编号可能不是物理连续的,只要求再逻辑上连续即可,向表中插入多条数据后,可能如下图所示:

但是挨个查找的话,数据量大的时候比较耗时。
为每个页建立一个目录项,每个目录项有一个 key(存储当前页最小的主键值)、page_no 存储页码,大致结构如下如下图所示:
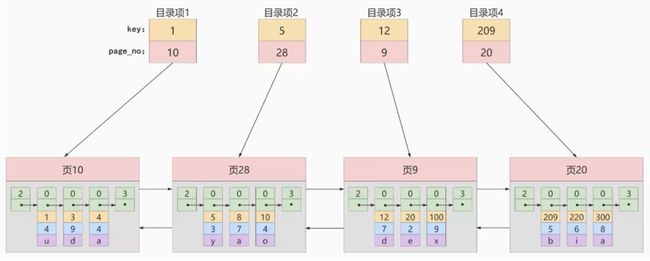
行和行之间以单链表存储,页和页之间以双向链表存储。
记录与记录之间以单链表存储,叶子节点与叶子节点之间以双向链表存储。
迭代优化 1:目录项记录的页
为每个页新建一个目录项之后,考虑到后续数据量会越来越大,如果目录项在物理空间中连续存储,对于新增页或删除页时,目录项也会随之发生,这样就会消耗大量的时间,所以将目录项也简单理解为一个行记录,目录项之间也用单项列表形式存储,也就是为多个目录项建立一个页,这样新增或者删除时,直接改变指针指向即可,效率客观的很,如下图所示:
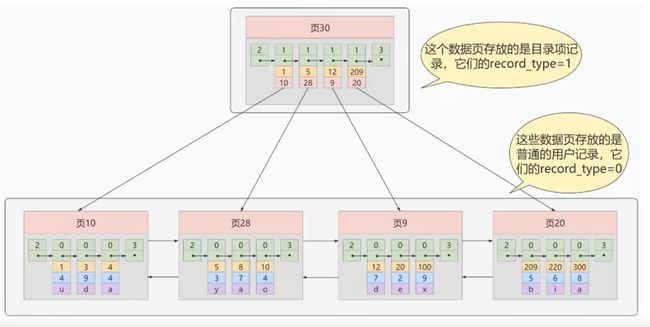
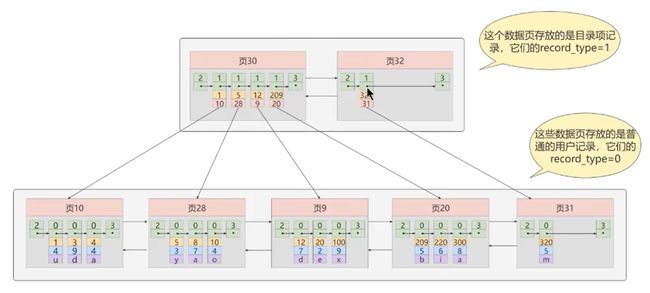
迭代优化 2:多个目录项记录的页
多个目录项记录页之间的关联如下图所示:
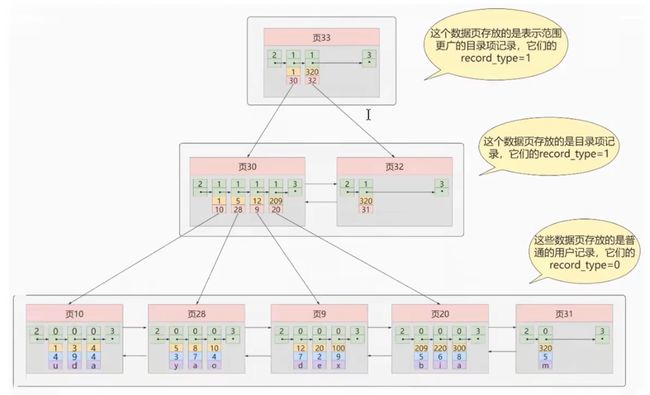
迭代优化 3:多个目录项记录页记录的页
多个目录项记录页组成的也目录页,如下图所示
B+Tree 结构
层层往上汇聚之后,最终形成了一个 B+Tree 的结构:
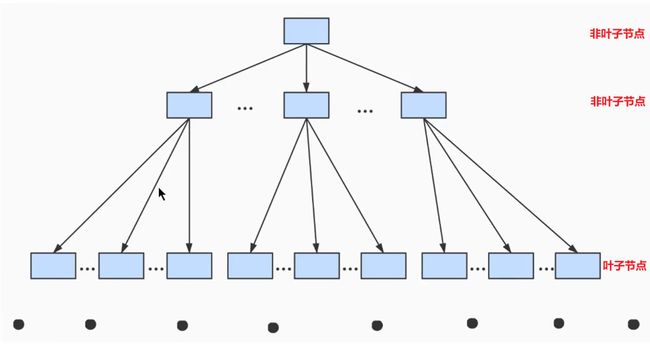
不论是存放用户记录的数据页,还是存放 目录项记录的数据页,最终都存放在 B+Tree 的结构中,所以我们撑这些数据页为节点。
实际用户记录都存放最下面的节点上,这些节点称为 叶子结点,其余用来存储 目录项的节点被称为 非叶子节点或 内节点,其中 B+Tree 最上边的节点也称为 根节点(可能会有多个根节点)。
一个 B+Tree 的结构可以分为很多层,规定最下面的层,也就是存放实际用户记录的那一层为第 0层,之后依次往上加。
上述的例子中我们假设存放实际记录的页 最多存 3 条记录,存放目录项记录的页 最多存放 4 条记录,其实真实的开发环境中存放的记录数非常大,假设存放实际记录的数据页(最下层的叶子节点)最多可以存放 100 条记录,存放目录项的数据页(上层的非叶子节点)最多可以存放 1000 调记录,那么计算方式如下:
- 如果 B+Tree 有 1 层,也就是只有一个存放用户记录的节点,最多能存放 100 条记录
- 如果 B+Tree 有 2 层,最多能存放
1000 * 100 = 10,0000条记录 - 如果 B+Tree 有 3 层,最多能存放
1000 * 1000 * 100 = 1,0000,0000条记录 - 如果 B+Tree 有 4 层,最多能存放
1000 * 1000 * 1000 * 100 = 1000,0000,0000条记录
到达 4 层的时候,就可以存放 1000,0000,00001000 亿条记录了,但是真实的环境中几乎不可能存到 1000 亿条,所以我们用到的 B+Tree 一般都不会超过 4 层。
假设我们是精确查找某一行数据,那在每一层通过二分法或者其他算法找到目录数据页,一次 I/O,然后再查找第二层的数据页,也是一次 I/O,所以精确查找某一行数据最多会经历四次 I/O,如果是范围查询就会有很多次 I/O 了。
本文内容总结借鉴于康师傅的 MySQL 视频课:https://www.bilibili.com/video/BV1iq4y1u7vj

一起学编程,让生活更随和!
如果你觉得是个同道中人,欢迎关注博主gzh:【随和的皮蛋桑】。
专注于Java基础、进阶、面试以及计算机基础知识分享。偶尔认知思考、日常水文。