【Python机器学习】k近邻——k近邻回归
k近邻算法还可以用于回归任务,如果单一近邻,预测结果就是最近邻的目标值,使用多个近邻时,预测结果为这些邻居的平均值。
用于回归的k近邻算法在scikit-learn的KNeighborsRegressor类中实现。
import mglearn.datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
import matplotlib.pyplot as plt
X,y=mglearn.datasets.make_wave()
X_train,X_test,y_train,y_test=train_test_split(
X,y,random_state=0
)
reg=KNeighborsRegressor(n_neighbors=3)
reg.fit(X_train,y_train)
print('预测结果:\n{}'.format(reg.predict(X_test)))
预测结果:

对于一维数据集,可以查看所有特征取值对应的测试结果:
import mglearn.datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
import matplotlib.pyplot as plt
import numpy as np
X,y=mglearn.datasets.make_wave()
X_train,X_test,y_train,y_test=train_test_split(
X,y,random_state=0
)
plt.rcParams['font.sans-serif']=['SimHei']
fig,axes=plt.subplots(1,3,figsize=(15,4))
line=np.linspace(-3,3,1000).reshape(-1,1)
for n_neighbors,ax in zip([1,3,9],axes):
reg=KNeighborsRegressor(n_neighbors=n_neighbors)
reg.fit(X_train,y_train)
ax.plot(line,reg.predict(line))
ax.plot(X_train, y_train, '^', c=mglearn.cm2(0), markersize=8)
ax.plot(X_test, y_test, '^', c=mglearn.cm2(1), markersize=8)
ax.set_title('{} 近邻数\n 训练score:{:.2f}测试score:{:.2f}'.format(n_neighbors,reg.score(X_train,y_train),reg.score(X_test,y_test)))
ax.set_xlabel('Feature')
ax.set_ylabel('Targrt')
axes[0].legend(loc='best')
plt.show()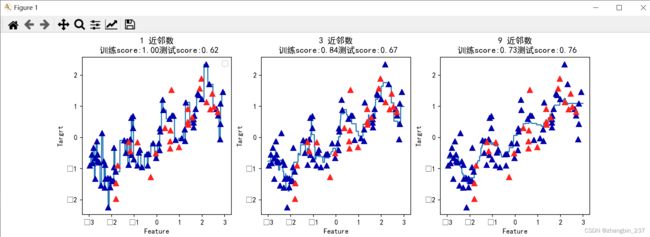
可以从图中看到,仅使用单一邻居,训练集中的每个店都对预测结果有很大影响,预测结果的图像经过所有数据点,导致预测结果非常不稳定。考虑更多邻居之后,预测结果变得更平滑,但对训练数据的拟合也不好