异常检测(无监督,生成模型)—SimpleNet: A Simple Network for Image Anomaly Detection and Localization
论文:https://arxiv.org/pdf/2303.15140v2.pdf
代码:GitHub - DonaldRR/SimpleNet
异常检测与定位就是在每个像素点进行二分类,0为正常,1为异常
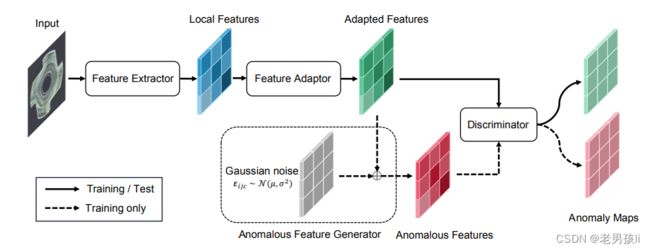 网络四大模块:
网络四大模块:
1.一个预训练(在imageNet上预训练)的特征提取器,生成本地特征
使用在imageNet上预训练的Resnet来提取特征,此主干一直被冻结,不进行训练
可以使用从网络中某几层抽取特征,比如从Resnet50的block3,block4抽取特征,抽取的这两层特征大小不一样,但可以将特征进行裁剪,然后拼接
2.一个浅层特征适配器,将本地特征转移到目标域
代码中使用的是线性层(Projection)映射,将提取出来的特征进行线性映射,使特征转移到目标域。
3.一个简单的异常特征生成器,通过向正常特征添加高斯噪声来伪造异常特征
4.一个二分类异常鉴别器,将异常特征与正常特征区分开来。
此算法优点:
1、不用在目标领域预训练backbone,而是建议使用一个特征适配器(线性层(Projection)映射)来产生面向目标的特征,以减少领域偏差。(liner+BN+LeakyReLU)
2、通过向正常特征添加高斯噪声来伪造异常特征, 在特征空间中合成异常,而不是直接在图像上合成。也就是说训练阶段只使用正常样本,通过高斯噪声产生异常,解决了异常样本不足的问题。
测试阶段将正常,异常样本一块喂进网络去判断。
代码阅读:(main.py文件中主要为数据集加载,网络结构参数,主要阅读simplenet.py中的train方法)
将图片输入到backbone中,提取出backbone中某一层[参数layers_to_extract_from]的特征,参数中可以是某两层。比如提取出特征如下:
# torch.Size([8, 512, 36, 36]) , torch.Size([8, 1024, 18, 18])(从backbone中某两层提取的)
提取出特征之后将特征切成小片(PatchMaker类实现)特征如下
#torch.Size([8, 1296, 512, 3, 3]), torch.Size([8, 324, 1024, 3, 3])
分别对应切片大小[36, 36], [18, 18]
变化过程:x: [ bs , c , w ,h] -> [ bs * w//patchsize * h//patchsize ,c, patchsize, patchsize]
将这些小片特征经过一系列变换,然后将他们堆叠起来(self.forward_modules["preprocessing"])
然后采用池化self.forward_modules["preadapt_aggregator"],池化后的最大值拼接起来形成二维特征,此使特征形状为[bs,n],但是好像代码中是[bs*k,m],
然后将此特征通过全连接层(Projection)(注: pre_proj参数大于0时才有此全连接层,此全连接层的参数要在训练集上训练),此特征记为true_feat
训练Discriminator:
Discriminator为几个liner+BN+Relu的组合,再加一个输出为一层的线性层
生成和此特征true_feat同样shape的噪声noise,则缺陷特征false_feat = true_feat+noise
将true_feat与false_feat特征拼接cat,送进Discriminator去训练,与真实标签求loss,然后反向传播更新参数
网络预测:
Discriminator输出的特征比如为(10368, 1),其中10368为 bs*图片像素值,根据此tensor按照不同的规则分别生成图像层级的异常置信度scores,与像素层次的异常置信度mask
因此scores 与mask的最优阈值不一样,可视化时要注意
可视化代码参考论文——PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
论文:https://arxiv.org/pdf/2011.08785v1.pdf
代码:https://github.com/xiahaifeng1995/PaDiM-Anomaly-Detection-Localization-master
(main.py中的plot_pig函数,224行)