Torchvison数据集dataset和dataloader使用
Torchvison-dataset的使用
这里介绍的时是Torchvision中关于数据库Dataset的一些使用方法。
首先我们可以在Pytorch观望中看到Torchvision中的很多数据集:

以CIFAR为例,点进去后可以了解到更多关于该数据集的一些信息:

在这里介绍了调用该数据库时的一些参数的设置及其功能。
Dataset的使用:
首先,我们需要导入torchvision库,为后面调用数据库提供库,同时导入SummaryWriter库,使用tersorboard可视化过程:
import torchvision
from torch.utils.tensorboard import SummaryWriter
我们定义train_set用于调用CIFAR10数据集:
torchvision.datasets.CIFAR10()
train_set = torchvision.datasets.CIFAR10(root='./dataset_learn',train=True,transform=dataset_transform,download=True)
①root=’'为该数据集保存的目录位置
②train为True代表该数据集用于训练,否则用于测试集
③transform为用于使用的将PIL图像数据转化为tensor类型的函数操作,可以自己定义操作内容(可以参照官方文档:transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop)
④download为True代表如果该数据集不存在的话,自动下载;数据集存在的话不下载
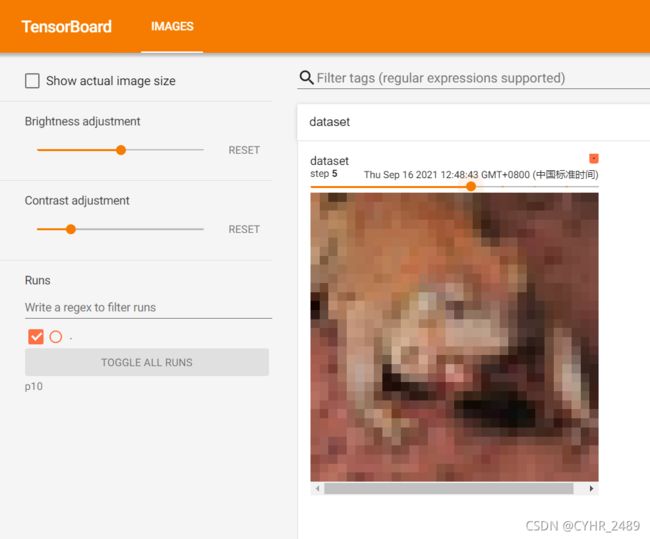
用一个for循环将数据集中的前10个样本展示在tersorboard上:
writer = SummaryWriter("p10")
for i in range(10):
img,target=train_set[i]
writer.add_image('dataset',img,i)
tensorboard上展示结果为:
完整实现代码:
import torchvision
from torch.utils.tensorboard import SummaryWriter
#定义dataset_transform,完成将PIL文件转化为tensor类型的compose()
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root='./dataset_learn',train=True,transform=dataset_transform,download=True)
writer = SummaryWriter("p10")
for i in range(10):
img,target=train_set[i]
writer.add_image('dataset',img,i)
writer.close()
Data Loader的使用
首先导入模块:
import torchvision
#准备的测试集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
使用上文中的CIFAR数据集:
test_data = torchvision.datasets.CIFAR10(root='./dataset_learn',train=False,transform=torchvision.transforms.ToTensor())
使用DataLoader()函数:
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
在此处各个参数所代表的意思为:
①dataset:使用的目标数据集
②batch_size:指的是每一个batch加载多少个样本
③shuffle:如果为True的话,表示在每一个epoch进行时都将数据进行打乱
④num_works:表示的是在加载过程中yong用多少个子进程进行加载数据
⑤drop_last:设置为Ture时 如果最后剩余的样本个数少于batch_size不足以分为一个组时,就会把剩余的样本数舍弃
使用for循环将数据集中的样本按照batch_size=64进行分组,并将其展示在tensorboard上:
writer = SummaryWriter('dataloader')
for epoch in range(2):
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images('epoch:{}'.format(epoch),imgs,step)
step=step+1
writer.close()
结果展示:

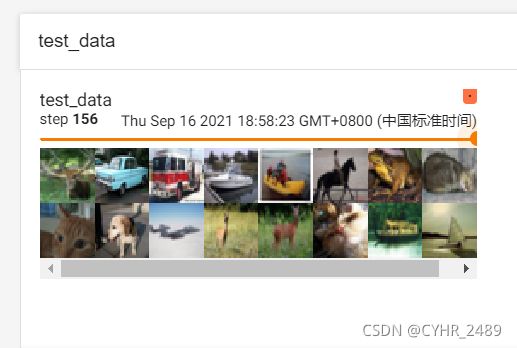
我们通过对比来了解shuffle参数的作用:
此时我们将shuffle=True,代表着每次新的epoch,也就是每次新的训练时,都会将原始数据集的顺序打乱,我们可以看见epoch0和epoch1在同一个step下的样本顺序已经发生改变:

我们通过对比来了解drop_last参数的作用:
drop_last:设置为Ture时 如果最后剩余的样本个数少于batch_size不足以分为一个组时,就会把剩余的样本数舍弃.
当我们将参数设置False时,第156步迭代时样本图片数量已经不够batch_size 64个,所以只显示了两行16个样本数量:
当我们将drop_last参数设置为True时,再次运行,我们发现最后一步不满足batch_size大小的图片被舍弃,所以只存在155个step:

完整实现代码:
import torchvision
#准备的测试集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10(root='./dataset_learn',train=False,transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
'''drop_last 设置为Ture时 如果最后剩余的样本个数少于64不足以分为一个组时,就会把剩余的样本数舍弃 '''
'''shuffle 设置为Ture时 每次选取的样本将会被打乱 '''
writer = SummaryWriter('dataloader')
for epoch in range(2):
step = 0
for data in test_loader:
imgs,targets = data
writer.add_images('epoch:{}'.format(epoch),imgs,step)
step=step+1
writer.close()
总结:
Dataset数据库调用的核心语句(参数解释在上面):
import torchvision
train_set = torchvision.datasets.CIFAR10(root='./dataset_learn',train=True,transform=dataset_transform,download=True)
Dataloader数据库调用的核心语句(参数解释在上面):
import torchvision
from torch.utils.data import DataLoader
test_loader = DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)