深度学习笔记
激活函数
- 激活函数可以让神经网引入非线性性质,去除线性相关
- 特征映射,是网络捕获数据中的不同特征;
- relu =max(0,x)输出为0到正无穷
- sigmod输出为0-1 形状为s
- relu 输出为-1-1 以0为中心,形状为s
Numpy广播机制
1:两个tensor维度完全相同
2:两个tensor维度不同,此时从最后一维开始比较,若其中一个tensor最后一维为1则可以进行广播,继续比较倒数第二维,若有一个为1或者不存在则可以继续广播,否则不行;

Batch noemalization
由于上层网络层的输出是下一层网络层的输入,但是由于不同的网络层不同导输出的差异较大,这会导致每次训练的结果差别较大,因此将每层的输出进行归一化也就是均值为0方差为1的标准分布(减去均值,除以方差即可),这样可以加快收敛,减少训练时间;

IOU
Intersection over Union,交并比,表示的是检测框与实际框的重叠程度,重叠程度越高越好;计算方法为先计算交集在计算并集最后交集/并集
过拟合
在训练集表现良好,但在未见过的数据集力里表现较差,一般两种原因:
1:模型拥有大量的参数,表现力较强;
2:训练数据集较少
解决办法:
1:权值衰减:在学习过程中对较大的权重进行惩罚,因为很多过拟合就是因为权值较大的参数导致的;具体做法就是在损失函数中引入一个额外的项,这个项通常表示为 L2 范数(欧几里德范数)的平方,其目标是使模型的权重趋向于接近零
损失函数 = 原始损失项 + λ * ||权重||^2
λ 是权值衰减系数,通常是一个非负实数,用于控制正则化项的强度。λ 的选择通常需要进行超参数调优。
2:dropout:在学习的过程中进行神经元的随机删除

残差链接
残差连接指的是将上游的数据原封不动的传给下游,这样在反向传播的时候可以将梯度原封不动的传递,这可以缓解因为加深层而导致梯度变小或者梯度消失的问题;
迁移学习
将学习玩的部分权重复制到其他的神经网络,进行在学习,这对于数据集较少的情况使非常的有效;
递归结构
神经网络会受到之前生成信息的影响;
卷积
卷积层可以保持输入数据的形状,这样可以更好的理解图像数据信息;
Padding
padding可以改变输出的形状,因为卷积操作会不断缩小输出的形状,这样会导致卷积不再可用,利用padding为1可以保持输入输出同形状;
stride
应用滤波器的位置间隔,增大步幅,输出会变小

输出计算公式

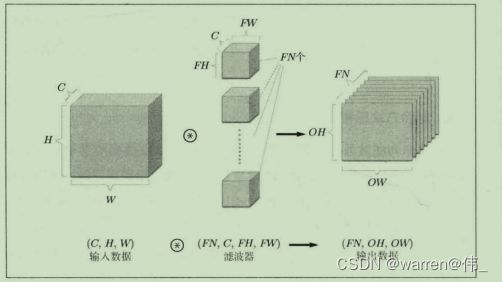
三维卷积操作:
一个三通道滤波器进行卷积运算输出一个特征图

n个三通道滤波器输出n个特征图
1x1卷积
1:有利于降维从而减少参数量和实现高速化处理;
2:增加非线性,可以增加网络的非线性拟合能力,从而提高网络的精度;
3:提取通道相关联的信息
参数初始化
参考6.2节???
评价方法
1:BELU:BLEU 最初设计用于机器翻译的质量评估,但它也可以用于其他自然语言处理任务的评估,前提是您有一个参考标准,以便将生成的文本与之进行比较得分越高越好
2:"Average Relative Distance (ARD)" 是一种用于衡量数据点之间的相对距离或相似性的统计度量。它通常用于数据挖掘、聚类分析、模式识别和机器学习等领域,以评估数据点之间的关系。得分越低越好
碰到的问题
1:训练时损失函数发散,这可能是由于学习率偏大导致的,在paddle的layout分析训练时,因为作者采用的是8卡进行训练,但我用的是1卡,未更改学习率导致无法收敛,后面将学习率调整为原来的1/8后得到改善;
学习工具
tensorboard
1)数据可视化工具,包括网络结构,损失和准确性,高维嵌入投影到低维空间
2)tensorboard --logdir=output/tensorboard --port=6009(端口若被占用可以换一个端口)
3)远程连接运行tensorboard
本地使用SSH 并将远程服务器的端口映射到本地的计算机,可以使用git bash(将远程和服务器的6009端口映射到本地16006端口)
ssh -L 16006:127.0.0.1:6009 -p 37557 [email protected]

4)本地浏览器打开http://localhost:16006/

数学知识
范数(正则化,用于控制复杂度和抑制过拟合)
L1范数(曼哈顿范数)
||x||_1 = |x_1| + |x_2| + ... + |x_n|各元素绝对值的和
L2范数(欧几里得范数)
||x||_2 = √(x_1^2 + x_2^2 + ... + x_n^2)各元素平方和的开方
L3范数(无穷范数)
||x||_∞ = max(|x_1|, |x_2|, ..., |x_n|)绝对值最大的元素