使用爬虫爬取热门电影
文章目录
-
-
- 网站存储视频的原理
- M3U8文件解读
- 网站分析
- 代码实现
-
网站存储视频的原理
首先我们来了解一下网站存储视频的原理。
一般情况下,一个网页里想要显示出一个视频资源,必须有一个标签,
这个video标签里面的src并不是视频的真正下载地址,几乎没有视频网站会在video里直接给出下载地址。
因为这种方案使得用户体验极差,既占网速又占内存。
更好的方案是对视频进行切片(ts),切完了以后每个切片都有一个独立的url,当我们把所有的切片都获取到以后,再把切片文件的正确顺序进行保存,然后合并就可以得到一个完整的视频。
既然要把视频切成非常多个小碎片. 那就需要有个文件来记录这些小碎片的路径. 该文件一般为M3U文件. M3U文件中的内容经过UTF-8的编码后, 就是M3U8文件. 今天, 我们看到的各大视频网站平台使用的几乎都是M3U8文件.
现在的视频网站用的几乎都是这种方案。正确的加载方案是
- 先请求到M3U8文件
- 加载切片(ts)文件
- 正常播放视频
这样做的好处是可以节省网络资源,当用户快进的时候,服务器可以直接定位到对应的ts文件进行加载,极大提升用户体验,可以减小服务器压力。
M3U8文件解读
随便点击一个电影
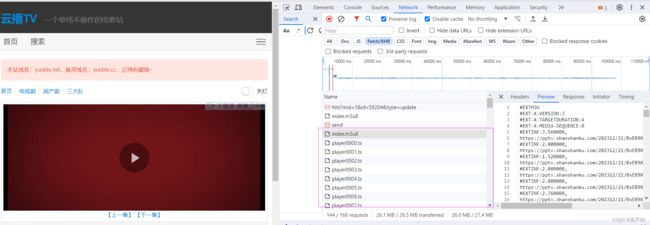
F12抓包,可以看到里面有m3u8文件和ts切片文件。
M3U8内容如下:
#EXTM3U
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=128,RESOLUTION=1142x480
900k_0X480_64k_25/hls/index.m3u8
所有的带#号的都是字段名称,不带#号的一般是路径或者文件名称。
900k_0X480_64k_25/hls/index.m3u8
很明显这里是一个网页的路径,对应一个新的M3U8文件
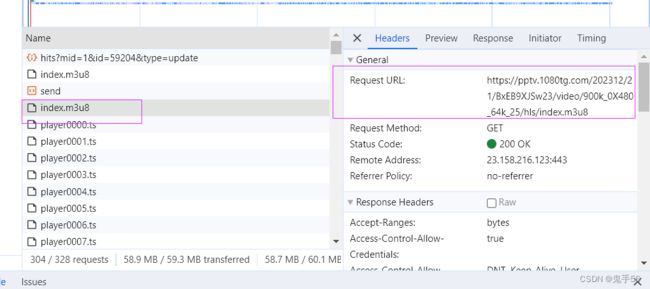
那么我们找到下面的M3U8文件,对比一下路径
https://pptv.1080tg.com/202312/21/BxEB9XJSw23/video/900k_0X480_64k_25/hls/index.m3u8
发现第一个M3U8文件里的路径就是第二个M3U8文件的URL。
第二个M3U8文件才是真实的视频的路径,内容如下:
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:4
#EXT-X-MEDIA-SEQUENCE:0
#EXTINF:3.560000,
https://pptv.shanshanku.com/202312/21/BxEB9XJSw23/video/900k_0X480_64k_25/hls/player0000.ts
#EXTINF:2.000000,
https://pptv.shanshanku.com/202312/21/BxEB9XJSw23/video/900k_0X480_64k_25/hls/player0001.ts
#EXTINF:1.520000,
https://pptv.shanshanku.com/202312/21/BxEB9XJSw23/video/900k_0X480_64k_25/hls/player0002.ts
#EXTINF:2.000000,
https://pptv.shanshanku.com/202312/21/BxEB9XJSw23/video/900k_0X480_64k_25/hls/player0003.ts
......
#EXT-X-ENDLIST
里面最重要的就是每一个ts文件的路径了,而且这个ts文件是没有加密的。
网站分析
接着我们来看一下整个过程,首先我们需要先通过这个网站把m3u8文件获取到。

直接搜一下网页的源代码,发现m3u8文件的链接就在这个url的字段里面。
我们拿到这个文件就可以去获取第二个m3u8文件,接着再取解析m3u8文件,然后爬取电影切片数据。
步骤如下:
- 通过网页源码获取第一层m3u8文件地址
- 下载第一层m3u8文件,获取第二层m3u8文件地址
- 解析第二层m3u8文件,爬取视频切片
- 对TS文件进行合并,还原回MP4文件
代码实现
第一步,我们需要从网页源码中,通过数据解析的方式,拿到第一层m3u8的链接
def GetFirstM3u8Url():
# 拿到页面源码
url = "https://www.yunbtv.org/vodplay/sandadui-2-1.html"
resp= requests.get(url)
resp.encoding="utf-8"
tree=etree.HTML(resp.text)
# 解析出url
script_content=tree.xpath('//script[contains(text(), "player_aaaa")]/text()')[0]
# 我们需要从脚本中提取JSON部分
json_str = script_content[script_content.find('{'):script_content.rfind('}') + 1]
# 解析JSON字符串
data = json.loads(json_str)
# 提取URL值
url_value = data.get("url", "")
print(url_value)
输出结果如下:
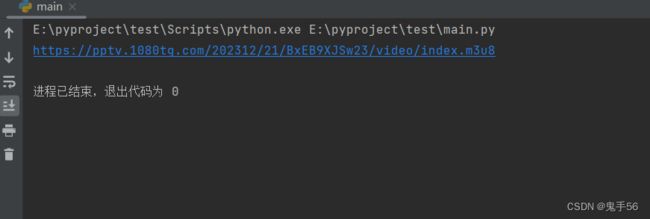
这样的话第一步就完成了。
第一层M3U8的链接拿到之后,接下来需要下载到第二层的M3U8文件
def DownloadM3u8File(first_m3u8_url):
resp = requests.get(first_m3u8_url)
resp.encoding = "utf-8"
url2 = resp.text.split()[-1]
# 移除第一个URL的最后一个分段(即去掉'/index.m3u8')
base_url = first_m3u8_url.rsplit('/', 1)[0]
# 第二层M3U8的地址
Second_m3U8_Url = f"{base_url}/{url2}"
#下载M3U8文件
M3u8Resp=requests.get(Second_m3U8_Url)
M3u8Resp.encoding = "utf-8"
with open("m3u8.txt",mode="w",encoding="utf-8") as f:
f.write(M3u8Resp.text)
实际效果:
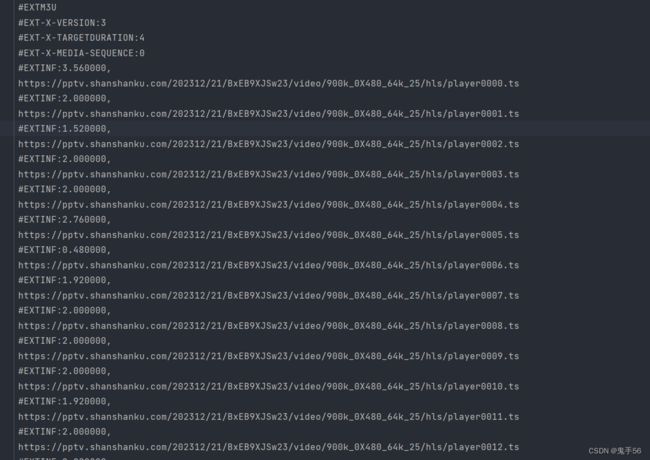
现在我们的m3u8文件就已经下载下来了
接下来处理这个M3U8文件,用协程逐个下载ts文件
# 下载单个ts文件
async def download_one(url):
print("正在下载:"+url)
# 重试10次 防止下载失败
for i in range(10):
try:
file_name=url.split("/")[-1]
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
content=await resp.content.read()
async with aiofiles.open(f"./TsFiles/{file_name}",mode="wb") as f:
await f.write(content)
break
except:
print("下载失败:"+url)
await asyncio.sleep((i+1)*5)
async def download_all_ts():
# 准备好任务列表
tasks=[]
# 读取m3u8文件
with open("m3u8.txt",mode="r",encoding="utf-8") as f:
for line in f:
# 排除所有#开头的
if line.startswith("#"):
continue
line=line.strip()
task=asyncio.create_task(download_one(line))
tasks.append(task)
# 等待任务全部结束
await asyncio.wait(tasks)
这样的话,我们的ts文件就下载完成了

接着通过TS的文件名,进行合并
def MergeTsFiles():
print("正在合并文件")
name_list=[]
with open("m3u8.txt",mode="r",encoding="utf-8") as f:
for line in f:
# 排除所有#开头的
if line.startswith("#"):
continue
line=line.strip()
file_name=line.split("/")[-1]
name_list.append(file_name)
with open(".\TsFiles\m3u8.txt", mode="w", encoding="utf-8") as f:
for data in name_list:
f.write("file "+"'"+data+"'"+"\n")
# 记录当前的工作目录
now_dir = os.getcwd()
# 切换工作目录
os.chdir("./TsFiles")
os.system("D:\\ffmpeg\\ffmpeg.exe -f concat -safe 0 -i m3u8.txt -c copy output.mp4")
# 所有操作后要把工作目录切换回来
os.chdir(now_dir)
print("文件合并完成")
这样的话,所有工作就完成了