2024/1/7周报
文章目录
- 摘要
- Abstract
- 文献阅读
-
- 题目
- 引言
- 贡献
- 相关工作
-
- Temporal Recommendation
- Sequential Recommendation
- 方法
-
- Problem Formulation
- Input Embedding
- Self-Attention Structure
- Model Training
- 实验
-
- 数据集
- 实验过程
- 实验结果
- 深度学习
-
- Self-attention
-
- 多头机制
- 堆叠多层
- 总结
摘要
本周阅读了一篇基于多时间嵌入的混合注意机制的顺序推荐的文章,为了解决以前模型的局限性,文章提出了MEANTIME(混合的Attention机制与多时间嵌入),它采用多种类型的时间嵌入,旨在捕捉各种模式,从用户的行为序列,和一个注意力结构,充分利用这种多样性。此外,还对self-attention的内容进行进一步的补充学习、复习。
Abstract
This week, an article on order recommendation based on multi-time embedded mixed Attention mechanism is readed. In order to solve the limitations of previous models, the author proposes MEANTIME (mixed attention mechanism and multi-time embedding), which uses various types of time embedding to capture various patterns, from the user’s behavior sequence and an attention structure, and make full use of this diversity. In addition, the content of self-attention is further supplemented and reviewed.
文献阅读
题目
MEANTIME: Mixture of Attention Mechanisms with Multi-temporal Embeddings for Sequential Recommendation
引言
背景:从用户的历史记录中获取用户的偏好对于做出有效的推荐至关重要,因为用户的偏好和项目的特征都是动态的;此外,用户的偏好在很大程度上取决于上下文;因此,sequential recommendation旨在通过用户的历史记录来预测用户可能更喜欢的下一组事物。
问题:大多数顺序推荐算法忽略了interactions’ timestamp values,虽然TiSASRec成功地结合了时间信息,但它却仅限于单个嵌入方案。由于timestamp values中的信息十分重要,因此探索多种形式的时间嵌入是有益的,而且这些嵌入可以充分提取不同的模式,以及可以充分利用这些多样性的模型架构。
方案:论文提出了MEANTIME,它引入多个时间嵌入,以更好地编码序列中用户项交互的绝对位置和相对位置。此外,论文使用了多个单独处理每个位置嵌入的自注意头,专注于特定的用户行为模式。
贡献
1)论文提出多样化用于编码序列中用户项交互位置的嵌入方案,通过将多个内核应用于序列中时间戳的位置/值来创建唯一的嵌入矩阵来实现的。
2)论文提出了一种新的模型架构,该架构同时操作多个self-attention heads,其中每个头通过利用提出的位置嵌入从用户的行为中提取特定模式。
3)通过实验证明了论文方法在真实世界数据集上的有效性,以及提供了一项全面的消融研究,帮助了解模型中各个组件的影响。
相关工作
Temporal Recommendation
Temporal Recommendation包含上下文信息,对推荐性能非常关键。TimeSVD++和BPTF将时间因子引入到矩阵分解方法中,Time-LSTM为LSTM配备了几种形式的时间门,以更好地模拟用户交互序列中的时间间隔,。CTA在时间信息上使用多个参数化核函数来校准自注意机制。
Sequential Recommendation
Sequential Recommendation的目的是根据用户的顺序历史来推荐相关的项目。SASRec成功地采用了自我注意机制,这在NLP领域取得了巨大的成功。BERT 4 Rec通过采用Transformer 和基于Cloz任务的训练方法改进了SASRec。TiSASRec通过将时间戳信息合并到自注意操作中来增强SASRec。论文工作旨在进一步扩大这一趋势,提出了一种新的模型架构,使用多种类型的时间嵌入和self-attention操作,以更好地捕捉用户行为的不同模式。
方法
本文设计了一种新的模型架构,为每个注意力头部注入各种时间嵌入,如下图所示:

Problem Formulation
基于给定的历史(Vu,Tu),预测用户u可能在目标时间戳与之交互的下一个项目。
Input Embedding
相对嵌入通过利用时间差信息来编码序列中每个交互对之间的关系。首先,我们定义了一个时间差矩阵,其元素定义为dab=(ta − tb)/T,其中T为可调整的单位时间差。如下所示,编码函数:


每一个嵌入都提供了对时间数据的独特视图。例如:Sin捕获周期性事件,较大的时间间隔要么在Exp中迅速衰减为零,要么在Log中可管理地增加;Pos可以从以前的模型中学习模式;最后Con完全消除了位置偏差,因此注意力只能集中在项目之间的关系上。
Self-Attention Structure
Attention Architecture:基于自注意力机制的模型采用了简单的绝对位置编码,将EItem和EPos的总和作为输入;EPos被仅依赖于阵列的位置索引之间差异的相对位置嵌入ER所取代,并且位置信息不再用于键和值编码器;参数bI和bR分别用作全局内容/位置偏差。对于绝对嵌入,论文也采用了前面的结构。
Stacking Layers:将Position-wise前馈网络应用于self-attention的结果,以完成单层,然后堆叠L个这样的层,为每个子层应用残差连接以促进训练:
![]()

Prediction Layer:给定最后一层的输出,通过以下方式获得每个位置的项目得分分布:
![]()
Model Training
从(Vu,Tu)中对项目v和时间戳t的子序列进行采样,并以概率ρ用[MASK]随机屏蔽其中的一部分,将v转换为v’;然后我们将v′和t送到模型中以获得P,,损失函数如下:

实验
数据集
在四个不同领域具有稀疏性的数据集上评估了模型:MovieLens 1M、MovieLen 20M、Amazon Beauty和Amazon Game。其中遵循通用数据预处理过程,将每个数据集转换为隐式数据集,将每个数值评级或评论视为用户项交互的存在,最后按用户ID对交互进行分组,按时间戳对它们进行排序,丢弃了少于五次交互的用户和项目,以确保数据集的质量。
对于每个用户的项序列,将最后一个项用于测试,将倒数第二个项用于验证。剩下的用来训练。为了对排名列表进行评分,使用两个常用指标:Recall和Normalized Discounted Cumulative Gain (NDCG)。
Recall@K and NDCG@K都被设计为ground truth item在前k列表中排名较高时具有较大的值。设置K = 5和10。
实验过程
作者使用PyTorch实现了MEANTIME 1。
参数设置如下:
隐藏维度h ∈ {16,32,64,128},头数n ∈ {2,4},丢弃率∈ {0.2,0.5},权重衰减wd ∈ {0,0.00001}。对所有基于transformer的模型使用相同的最大序列长度(MovieLens为N = 200,Amazon为N = 50)和层数(L = 2)
实验结果
与最好基线相比,论文提出的模型在所有指标和数据集中都具有最优的性能。
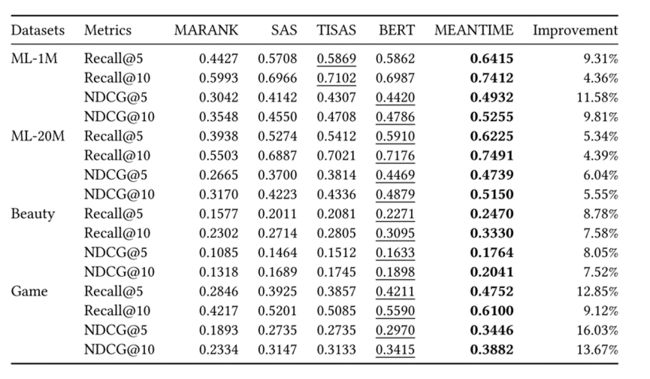
多时间嵌入的效果:
下图比较了在ML-1M和Amazon Game数据集上所有可能的时间嵌入组合情况,结果表明具有不同特征的数据集需要精心选择的时间嵌入,以提供对用户-项目交互上下文的正确看法。

深度学习
Self-attention
例子:
以两个词的输入为例来解释self-attention的大致过程:

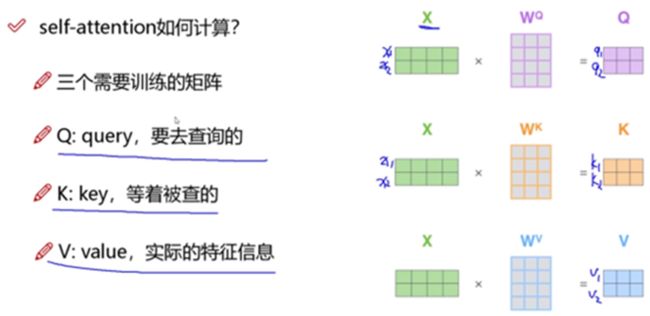

此时每个词看的是整个输入序列,不再只看之前的序列,并且是并行计算,同时计算出所有的输出结果。
再以四输入四输出的例子进行补充说明:
其中只有Wq、Wk、Wv是机器需要学习的参数。
多头机制
CNN中,可以设置不同的filter来进行卷积,self-attention中也可以设置多组q,k,v的值得到不同的特征表达,这就是multi-headed机制。一般情况下,只做8组head即可,通过不同的head得到多个特征表达。多组结果z可以拼接在一起通过全连接层进行降维得到最终的结果。
堆叠多层

Self-attention输入输出都是向量,可以将self-attention也进行多层堆叠。10层以上都是很常见的。
补充说明:
结果需要通过Add和normalize,并且也可以类似CNN使用残差网络同等映射,以防在堆叠过程中出现结果变差的情况。
总结
本周继续学习了transformer中的核心机制self-attention并进行手动模拟推导,这有利于进一步理解transformer。decoder与encoder类似,只是attention的计算略有不同以及添加了mask机制。在decoder中,只能利用序列中已得出的结果,不能用后面未推导出的部分。