requests库的使用
基本用法
安装:pip install requests
实例1:
与urllib库中urlopen()方法相对应
import requests
response = requests.get('http://www.baidu.com')
print(type(response))//输出响应类型
print(response.status_code)//状态码
print(type(response.text))//响应体类型(为字符串str类型)
print(response.cookies)//Cookies(为RequestsCookieJar类型)
print(response.text)//内容
结果:
F:\PycharmProjects\Maoyantop100\venv\Scripts\python.exe F:/PycharmProjects/Maoyantop100/test.py
200

å
³äºŽç™¾åº¦ About Baidu
©2017 Baidu 使用百度å‰å¿
读 æ„è§å馈 京ICPè¯030173å• 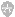
Process finished with exit code 0
GET请求
通过requests 构建get请求
实例2:
import requests
response = requests.get('http://httpbin.org/get')
print(response.text)
结果:
{
“args”: {},
“headers”: {
“Accept”: “/”,
“Accept-Encoding”: “gzip, deflate”,
“Host”: “httpbin.org”,
“User-Agent”: “python-requests/2.24.0”,
“X-Amzn-Trace-Id”: “Root=1-5f0a8295-c8c31a369e769966f9ff46ea”
},
“origin”: “117.140.168.127”,
“url”: “http://httpbin.org/get”
}
Process finished with exit code 0
实例3:
往get请求中加入信息,例如添加name和age等信息,可以通过字典的方式来存储将要添加的信息
import requests
data = {
'name':'simnp',
'age' : 18
}
response = requests.get('http://httpbin.org/get',params=data)
print(response.text)
结果:
{
“args”: {
“age”: “18”,
“name”: “simnp”
},
“headers”: {
“Accept”: “/”,
“Accept-Encoding”: “gzip, deflate”,
“Host”: “httpbin.org”,
“User-Agent”: “python-requests/2.24.0”,
“X-Amzn-Trace-Id”: “Root=1-5f0a87f8-c19bb9cfd81b009e619728c5”
},
“origin”: “117.140.168.127”,
“url”: “http://httpbin.org/get?name=simnp&age=18”
}
实例 4:
可以直接调用json()方法将网页返回的str类型转换为字典格式
import requests
response = requests.get('http://httpbin.org/get')
print(type(response.text))//json格式字符串类型
print(response.json())//调用json方法
print(type(response.json()))//返回字典格式
结果:
{‘args’: {}, ‘headers’: {‘Accept’: ‘/’, ‘Accept-Encoding’: ‘gzip, deflate’, ‘Host’: ‘httpbin.org’, ‘User-Agent’: ‘python-requests/2.24.0’, ‘X-Amzn-Trace-Id’: ‘Root=1-5f0a89a3-d221f6da108d6a14247ebec6’}, ‘origin’: ‘117.140.168.127’, ‘url’: ‘http://httpbin.org/get’}
实例5:
抓取二进制数据(图片,音频,视频)如下所示:这里使用了open()方法,第一个参数是保存位置和文件名称,第二个参数是以二进制写的形式打开,可以向文件里面写入二进制数据。
import requests
import re
r = requests.get('http://img.jf258.com/i/1a1293690796x811437375b27.jpg')
with open('E:\picture\ioo.ico','wb') as f://放在E盘下面的picture文件夹里面名为ioo
f.write(r.content)
结果:
F:\PycharmProjects\Maoyantop100\venv\Scripts\python.exe F:/PycharmProjects/Maoyantop100/test.py
实例6:
post请求
import requests
data = {
'name':'maomao',
'age':18
}
r = requests.post('https://httpbin.org/post',data = data)
print(r.text)
结果:
{
“args”: {},
“data”: “”,
“files”: {},
“form”: {
“age”: “18”,
“name”: “maomao”
},
“headers”: {
“Accept”: “/”,
“Accept-Encoding”: “gzip, deflate”,
“Content-Length”: “18”,
“Content-Type”: “application/x-www-form-urlencoded”,
“Host”: “httpbin.org”,
“User-Agent”: “python-requests/2.24.0”,
“X-Amzn-Trace-Id”: “Root=1-5f0aaab1-59e40b91bb83c480b45192e2”
},
“json”: null,
“origin”: “117.140.168.127”,
“url”: “https://httpbin.org/post”
}
实例 7:
import requests
r = requests.get('https://www.baidu.com/')
print(r.status_code,type(r.status_code))
print(r.headers,type(r.headers))
print(r.cookies,type(r.cookies))
print(r.url,type(r.url))
print(r.history,type(r.history))
结果:
200
{‘Cache-Control’: ‘private, no-cache, no-store, proxy-revalidate, no-transform’, ‘Connection’: ‘keep-alive’, ‘Content-Encoding’: ‘gzip’, ‘Content-Type’: ‘text/html’, ‘Date’: ‘Sun, 12 Jul 2020 06:33:19 GMT’, ‘Last-Modified’: ‘Mon, 23 Jan 2017 13:24:33 GMT’, ‘Pragma’: ‘no-cache’, ‘Server’: ‘bfe/1.0.8.18’, ‘Set-Cookie’: ‘BDORZ=27315; max-age=86400; domain=.baidu.com; path=/’, ‘Transfer-Encoding’: ‘chunked’}
https://www.baidu.com/
[]
实例8:
通过比较返回码和内置的成功的返回码,来保证请求得到了正常的响应,
import requests
r = requests.get('https://www.baidu.com/')
exit() if not r.status_code == requests.codes.ok else print('Request Successful')
结果:
F:\PycharmProjects\Maoyantop100\venv\Scripts\python.exe F:/PycharmProjects/Maoyantop100/test.py
Request Successful
实例9
文件需要和当前脚本保持同一目录下
import requests
files = {'file':open('ioo.ico','rb')}
r = requests.post('http://httpbin.org/post',files=files)
print(r.text)
结果:
{
“args”: {},
“data”: “”,
“files”: {
“file”: "data:application/octet-stream;base64,/AAAAAAAAAAA
},
“form”: {},
“headers”: {
“Accept”: “/”,
“Accept-Encoding”: “gzip, deflate”,
“Content-Length”: “21553”,
“Content-Type”: “multipart/form-data; boundary=2c29593ec8137d470059f8adecebcf48”,
“Host”: “httpbin.org”,
“User-Agent”: “python-requests/2.24.0”,
“X-Amzn-Trace-Id”: “Root=1-5f0acdd9-f402fc5c4be53dfcb7a97634”
},
“json”: null,
“origin”: “117.140.168.127”,
“url”: “http://httpbin.org/post”
}
实例 10
调用itmes()方法将RequestsCookieJar类型转化为元组列表输出
import requests
r = requests.get('https://www.baidu.com')
print(r.cookies)
for key,value in r.cookies.items():
print(key+'='+value)
结果:
BDORZ=27315
实例 11:
import requests
headers = {
'Cookie':'_zap=c7cc39fc-49fd-4810-8d4c-a21c8b740f1c; d_c0="AGDYUfgbhhGPTqEO2lOk5JPeZSy-ejixrD4=|1593837696"; _ga=GA1.2.1728955418.1593837697; _gid=GA1.2.645024330.1594478731; _xsrf=n0KShkp8ZO4s9Fpv2PcIkC4jy7wCL9b7; capsion_ticket="2|1:0|10:1594527272|14:capsion_ticket|44:OTAxYmYxY2MwNjg1NGEwOTllMDRkMTZmOTA5OTRkYmQ=|d7a6781d4d9a0771833242159fb3c7ec2c955102b1a771d11ff4bbf4e855381e"; z_c0="2|1:0|10:1594527975|4:z_c0|92:Mi4xZkNsUUNRQUFBQUFBWU5oUi1CdUdFU2NBQUFDRUFsVk41eDB5WHdDZzhQU1F1a1gwcWFuU2Y2NW1ld0NOam9VTTdn|17475231bcb1cf0f9977537206ac5f66f0654af60a657898b64f6eaebf9c00c4"; tst=r; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1594480435,1594480516,1594526583,1594545019; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1594545019; _gat_gtag_UA_149949619_1=1; KLBRSID=4efa8d1879cb42f8c5b48fe9f8d37c16|1594545028|1594545014; SESSIONID=eTJn7sqaa4m64pRcTcErmq0bfFGpU3iKpWpRcHlxl8S; JOID=V18WCkmTGQu1E_uSWp_8mrYpUQdN9ElL0COK5zH1L2KJLIzCPRHEAOYW_ZxbTpeMBKqrWV7VhTchcliqO9mi0Tw=; osd=WloXAkKeHAq9GPaXW5f3l7MoWQxA8UhD2y6P5jn-ImeIJIfPOBDMC-sT_JRQQ5KNDKGmXF_djjokc1ChNtyj2Tc=',
'Host':'www.baidu.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
r = requests.get('https://zhihu.com',headers=headers)
print(r.text)
结果:知乎
实例 12
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
结果:{
“cookies”: {
“number”: “123456789”
}
}
实例 13:
设置代理若用到http basic auth 请参考如下语法格式
import requests
proxies = {
"http":"http://user:[email protected]:3128/",
}
requests.get("https://www.taobao.com",proxies=proxies)
socks协议代理
安装socks库:pip install socks
实例14:
超时设置,timeout设置为None 就不会返回错误
import requests
response = requests.get('https://www.baidu.com',timeout = None)
print(response.status_code)
传入元组,设置timeout用作连接和读取这两者的timeout总和
import requests
response = requests.get('https://www.baidu.com',timeout =(0.2,0.6))
print(response.status_code)
实例15:
身份认证:
import requests
response = requests.get('https://www.zhihu.com/signin?next=%2F',auth =('username','password'))
print(response.status_code)
实例16:
Prepare Request:用url,data,headers构建一个Request对象,然后调用Session的prepare_request()方法将其转换为Prepared Request对象,在用session的send()方法将其发送给r,然后打印出来
from requests import Request,Session
url = 'http://httpbin.org/get'
data = {
'name':'maomao'
}
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
# s = Session()
# req = Request('GET',url,data=data,headers=headers)
# prepped = s.prepare_request(req)
# r = s.send(prepped)
# print(r.text)
req = Request('GET',url,data=data,headers=headers)
pre = Session().prepare_request(req)
r = Session().send(pre)
print(r.text)
结果:
{
“args”: {},
“headers”: {
“Accept”: “/”,
“Accept-Encoding”: “gzip, deflate”,
“Content-Length”: “11”,
“Content-Type”: “application/x-www-form-urlencoded”,
“Host”: “httpbin.org”,
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36”,
“X-Amzn-Trace-Id”: “Root=1-5f0bfa2b-1693f9e01954c40aaa3bee7a”
},
“origin”: “117.140.168.127”,
“url”: “http://httpbin.org/get”
}
Process finished with exit code 0