一图读懂-神经网络14种池化Pooling原理和可视化(MAX,AVE,SUM,MIX,SOFT,ROI,CROW,RMAC )
池化Pooling是卷积神经网络中常见的一种操作,Pooling层是模仿人的视觉系统对数据进行降维,其本质是降维。在卷积层之后,通过池化来降低卷积层输出的特征维度,减少网络参数和计算成本的同时,降低过拟合现象。

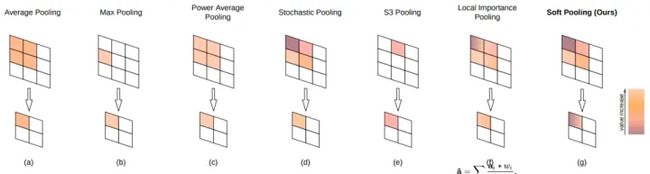


最大池化(Max Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。即,取局部接受域中值最大的点。同理,平均池化(Average Pooling)为取局部接受域中值的平均值。
max pooling 的操作如下图所示:整个图片被不重叠的分割成若干个同样大小的小块(pooling size)。每个小块内只取最大的数字,再舍弃其他节点后,保持原有的平面结构得出 output。

max pooling 在不同的 depth 上是分开执行的,且不需要参数控制。 那么问题就 max pooling 有什么作用?部分信息被舍弃后难道没有影响吗?

Max pooling 的主要功能是 downsampling,却不会损坏识别结果。
MAX pooling 指的是对于每一个 channel(假设有 N 个 channel),将该 channel 的 feature map 的像素值选取其中最大值作为该 channel 的代表,从而得到一个 N 维向量表示。笔者在 flask-keras-cnn-image-retrieval中采用的正是 MAX pooling 的方式。

MAX pooling 要稍微优于 SUM pooling、AVE pooling。不过这三种方式的 pooling 对于 object retrieval 的提升仍然有限。
Max Pooling的作用
作用1:invariance(不变性)
invariance(不变性),这种不变性包括translation(平移)不变性,rotation(旋转)不变性,scale(尺度)不变性。
(1)translation平移

图中左边两个大图,表示数字1,但是两个的位置不同,上者经过向右平移得到下者。经过池化后,得到了相同的结果。
(2)rotation

左边大图表示的是汉字“一”(姑且这么理解吧,明白就行)。经过两次池化得到了相同的结果。
(3)scale

左边大图表示的是数字0,经过两次池化得到了相同的结果。
再举一个例子:

考虑黄色区域中黑色的形状-----“横折”。经过2*2的filter之后,得到了3*3的output;
经过3*3的最大池化后,都得到了1*1的output 为3.
可以看出,“横折”这个形状,在经过池化后得到的结果是相同的,这就减小下一层输入大小,减小计算量和参数个数,降维(减小feature map的尺寸)。
作用2:增大感受野 可能跟作用1的结论有些因果关系。
首先它第一个作用是降低feature map的尺寸,减少需要训练的参数;其次,因为有缩小的作用,所以之前的4个像素点,现在压缩成1个。那么,相当于我透过这1个点,就可以看到前面的4个点,这不就是把当前map的感受野一下子放大。


Global Pooling就是Pooling的滑窗size和整个Feature Map的size一样大。在滑窗内的具体pooling方法可以是任意的,所以就会被细分为Global Average Pooling,Global Max Pooling等。


Stochastic pooling是论文《Stochastic Pooling for Regularization of Deep Convolutional Neural Networks》中提到的一种池化策略,大意是只需对特征区域元素按照其概率值大小随机选择,元素值大的被选中的概率也大。

Mix Pooling是同时利用最大值池化Max Pooling与均值池化Average Pooling两种的优势而引申的一种池化策略。常见的两种组合策略:拼接Cat与叠加Add。


SoftPool是一种变种的Pooling,它可以在保持池化层功能的同时尽可能减少池化过程中带来的信息损失。上图展示了SoftPool操作的Forward阶段与Backward阶段,6*6大小的区域表示的是激活映射a。


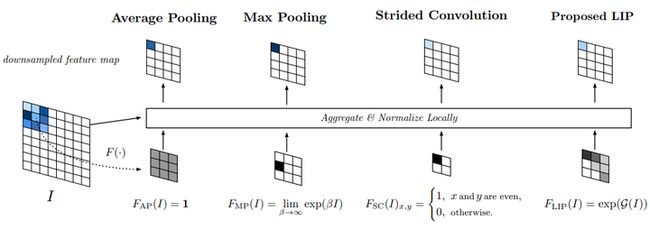
Local Importance-based Pooling提出通过一个基于输入特征的子网络自动学习重要性。它能够自适应地确定哪些特征更重要,同时在采样过程中自动增强识别特征。具体思路是,在原feature map上学习一个类似于attention的map,然后和原图进行加权求平均。需要说明的是,这里采样的间隔其实还是固定的,不符合上述描述的第一条,但是作者认为,由于importance是可变,从而实现变形的感受野。


S3Pool提出一种随机位置池化策略,集成了随机池化Stochastic Pooling与最大值池化Max Pooling。



图池化是基于条件随机场的,它是将图池化视为一个节点聚类问题,并使用CRF在不同节点的分配之间建立关系。并通过结合图拓扑信息来推广这个方法,使得图池化可以控制CRF中的成对团集。


Region of Interest Pooling是在目标检测任务中广泛使用的操作。它对于来自输入列表的每个感兴趣区域,它采用与其对应的输入特征图的一部分并将其缩放到某个预定义的大小。这可以显着加快训练和测试时间,它允许重新使用卷积网络中的特征映射,同时也允许以端到端的方式训练物体检测系统。
10.SUM pooling
基于 SUM pooling 的中层特征表示方法,指的是针对中间层的任意一个 channel(比如 VGGNet16, pool5 有 512 个 channel),将该 channel 的 feature map 的所有像素值求和,这样每一个 channel 得到一个实数值,N 个 channel 最终会得到一个长度为 N 的向量,该向量即为 SUM pooling 的结果。
11.MOP pooling
MOP Pooling 源自这篇文章,一作是 Yunchao Gong,此前在搞的时候,读过他的一些论文,其中比较都代表性的论文是 ITQ,笔者还专门写过一篇笔记。MOP pooling 的基本思想是多尺度与 VLAD(VLAD 原理可以参考笔者之前写的博文),其具体的 pooling 步骤如下:

12.CROW pooling
对于 Object Retrieval,在使用 CNN 提取特征的时候,我们所希望的是在有物体的区域进行特征提取,就像提取局部特征比如 SIFT 特征构 BoW、VLAD、FV 向量的时候,可以采用 MSER、Saliency 等手段将 SIFT 特征限制在有物体的区域。同样基于这样一种思路,在采用 CNN 做 Object Retrieval 的时候,我们有两种方式来更细化 Object Retrieval 的特征:一种是先做物体检测然后在检测到的物体区域里面提取 CNN 特征;另一种方式是我们通过某种权重自适应的方式,加大有物体区域的权重,而减小非物体区域的权重。CROW pooling ( Cross-dimensional Weighting for Aggregated Deep Convolutional Features ) 即是采用的后一种方法,通过构建 Spatial 权重和 Channel 权重,CROW pooling 能够在一定程度上加大感兴趣区域的权重,降低非物体区域的权重。其具体的特征表示构建过程如下图所示:

其核心的过程是 Spatial Weight 和 Channel Weight 两个权重。Spatial Weight 具体在计算的时候,是直接对每个 channel 的 feature map 求和相加,这个 Spatial Weight 其实可以理解为 saliency map。我们知道,通过卷积滤波,响应强的地方一般都是物体的边缘等,因而将多个通道相加求和后,那些非零且响应大的区域,也一般都是物体所在的区域,因而我们可以将它作为 feature map 的权重。Channel Weight 借用了 IDF 权重的思想,即对于一些高频的单词,比如 “the”,这类词出现的频率非常大,但是它对于信息的表达其实是没多大用处的,也就是它包含的信息量太少了,因此在 BoW 模型中,这类停用词需要降低它们的权重。借用到 Channel Weight 的计算过程中,我们可以想象这样一种情况,比如某一个 channel,其 feature map 每个像素值都是非零的,且都比较大,从视觉上看上去,白色区域占据了整个 feature map,我们可以想到,这个 channel 的 feature map 是不利于我们去定位物体的区域的,因此我们需要降低这个 channel 的权重,而对于白色区域占 feature map 面积很小的 channel,我们认为它对于定位物体包含有很大的信息,因此应该加大这种 channel 的权重。而这一现象跟 IDF 的思想特别吻合,所以作者采用了 IDF 这一权重定义了 Channel Weight。
总体来说,这个 Spatial Weight 和 Channel Weight 的设计还是非常巧妙的,不过这样一种 pooling 的方式只能在一定程度上契合感兴趣区域,我们可以看一下 Spatial Weight*Channel Weight 的热力图:

从上面可以看到,权重大的部分主要在塔尖部分,这一部分可以认为是 discriminate 区域,当然我们还可以看到,在图像的其他区域,还有一些比较大的权重分布,这些区域是我们不想要的。当然,从笔者可视化了一些其他的图片来看,这种 crow pooling 方式并不总是成功的,也存在着一些图片,其权重大的区域并不是图像中物体的主体。不过,从千万级图库上跑出来的结果来看,crow pooling 这种方式还是可以取得不错的效果。
13.RMAC pooling
RMAC pooling 的池化方式源自于 ,三作是 Hervé Jégou(和 Matthijs Douze 是好基友)。在这篇文章中,作者提出来了一种 RMAC pooling 的池化方式,其主要的思想还是跟上面讲过的 MOP pooling 类似,采用的是一种变窗口的方式进行滑窗,只不过在滑窗的时候,不是在图像上进行滑窗,而是在 feature map 上进行的 (极大的加快了特征提取速度),此外在合并 local 特征的时候,MOP pooling 采用的是 VLAD 的方式进行合并的,而 RMAC pooling 则处理得更简单 (简单并不代表效果不好),直接将 local 特征相加得到最终的 global 特征。其具体的滑窗方式如下图所示:

图片来源:
图中示意的是三种窗口大小,图中‘x’代表的是窗口的中心,对于每一个窗口的 feature map,论文中采用的是 MAX pooling 的方式,在 L=3 时,也就是采用图中所示的三种窗口大小,我们可以得到 20 个 local 特征,此外,我们对整个 fature map 做一次 MAX pooling 会得到一个 global 特征,这样对于一幅图像,我们可以得到 21 个 local 特征 (如果把得到的 global 特征也视为 local 的话),这 21 个 local 特征直接相加求和,即得到最终全局的 global 特征。论文中作者对比了滑动窗口数量对 mAP 的影响,从 L=1 到 L=3,mAP 是逐步提升的,但是在 L=4 时,mAP 不再提升了。实际上 RMAC pooling 中设计的窗口的作用是定位物体位置的 (CROW pooling 通过权重图定位物体位置)。如上图所示,在窗口与窗口之间,都是一定的 overlap,而最终在构成 global 特征的时候,是采用求和相加的方式,因此可以看到,那些重叠的区域我们可以认为是给予了较大的权重。
上面说到的 20 个 local 特征和 1 个 global 特征,采用的是直接合并相加的方式,当然我们还可以把这 20 个 local 特征相加后再跟剩下的那一个 global 特征串接起来。实际实验的时候,发现串接起来的方式比前一种方式有 2%-3% 的提升。在规模 100 万的图库上测试,RMAC pooling 能够取得不错的效果,跟 Crow pooling 相比,两者差别不大。
神经网络池化pooling就为大家介绍到这里,欢迎大家收藏CSDN学院课程《从0到1 Python数据科学之旅》,课程有大量数据科学建模实际案例,大家记得收藏课程。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
参考链接:
https://arxiv.org/pdf/1611.05138.pdf
https://arxiv.org/pdf/1301.3557.pdf
https://arxiv.org/pdf/2101.00440.pdf
https://arxiv.org/pdf/1908.04156.pdf
https://openreview.net/pdf?id=BJxg_hVtwH
https://deepsense.ai/region-of-interest-pooling-explained/
https://arxiv.org/abs/2009.07485
https://www.jianshu.com/p/c3ba4ca849d3
https://blog.csdn.net/jiachen0212/article/details/78548667
https://www.cnblogs.com/ying-chease/p/8658351.html
https://www.sohu.com/a/160924449_651893
https://www.cnblogs.com/guoyaohua/p/8674228.html
https://blog.csdn.net/dulingtingzi/article/details/79848625
https://blog.csdn.net/u010402786/article/details/51541465
https://blog.csdn.net/weixin_41513917/article/details/102514739
Overview of multi-scale orderless pooling for CNN activations (MOP-CNN). Our proposed feature is a concatenation of the feature vectors from three levels: (a)Level 1, corresponding to the 4096-dimensional CNN activation for the entire 256256image; (b) Level 2, formed by extracting activations from 128128 patches and VLADpooling them with a codebook of 100 centers; (c) Level 3, formed in the same way aslevel 2 but with 64*64 patches.