链表(1)(基本概念与相关的几道习题讲解)
1.链表的简介:
链表是一种类似于锁链的数据结构,锁链的每一节可以看成是链表之中的一个元素。
我们只要记录每一节之前和之后分别是哪一节就能把整个链表串起来。
类似于锁链,链表的每一节都可以打开,能够快速做到一些用数组存储数据时比较麻烦的操作,比如在中间插入或删除数据、取一段连续的数据、对一段连续的数据进行翻转等操作。
但是链表在访问特定编号节点的时候,需要按链上顺序逐个查找,不如数组来的方便。
2.链表的结构:
链表上的数据存储单元,一般称为节点(Node),类似于数组中的一个位置。
一个节点包含它存储的数据(Date),以及一或两个用来指向上一个/下一个节点的位置的指针。
链表有很多的类型,我目前学习的是单向链表,单向链表中的节点只记录后一节点的位置信息。
在c++中,一般使用结构体来存储链表的节点。
struct Node{
int value;
Node *next;
//若是双向链表
Node *prev;
};上述就是用结构体的形式存储链表节点的例子。
单向链表:
为了维护链表i,我们一般会记录下链表的头指针(Node *head)。
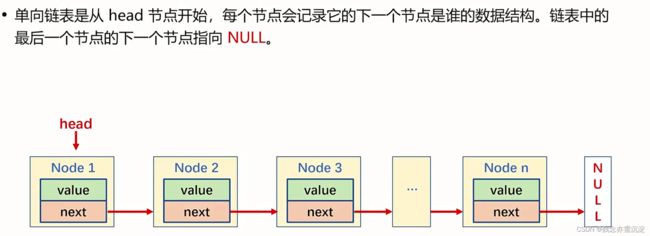
在初始化的时候,一般将head设置成空指针:
Node *head=NULL单向链表的插入: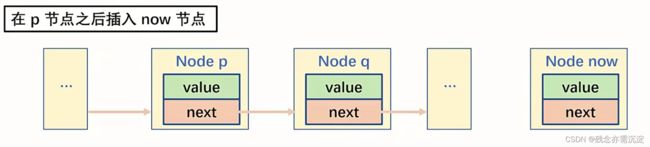

我们通常使用函数实现此功能:
void Insert(Node *p,Node *now){
now->next=p->next;
p->next=now;
}当遇见特殊情况的时候,例如我们要在头指针前插入now,那么可以这么写:
void Insert(Node *head,Node *now){
now->next=head;
head=now;
}单向链表的删除:
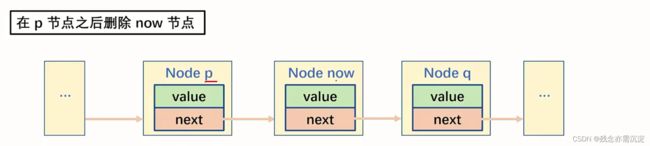
void Delete(Node *p,Node *now){
p->next=now->next;
now->next=NULL;
}我们可以通过几个例题来对链表的应用进行简单的理解:
1.小学生排序: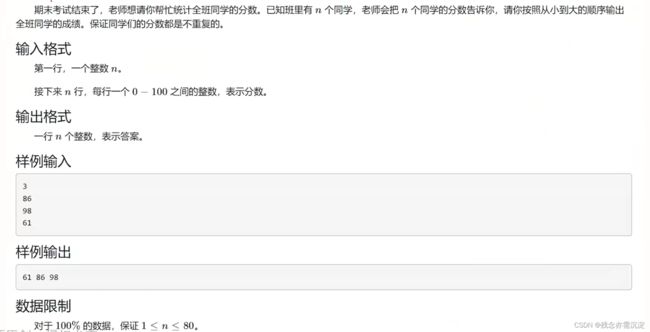
接下来给出代码实现:
#include
#include
using namespace std;
int n;
struct Node{//定义结构体其中包含了学生的分数以及用来指向链表下一个元素的指针变量next
int s;
Node *next;
}*head,a[81];//记住不要忘了设置链表的头部
int main(){
cin>>n;
head=NULL;//首先将头部定义为空
for(int i=1;i<=n;i++){
cin>>a[i].s;
if(head==NULL){
head=&a[i];//将第一个读入的元素设置成链表的头部
}
else
{
if(a[i].ss){//如果读入的数字比链表头部更小那么将读入的这一个数字更新成链表
的头部
a[i].next=head;
head=&a[i];
}
else {//将读入的元素与链表中的元素从头部开始依次进行比较
Node *p=head;
for(Node *v=head;v;v=v->next){
if(a[i].s>v->s)
p=v;
else
break;
}
a[i].next=p->next;//将这个读入的元素插入到链表正确的位置上面
p->next=&a[i];
}
}
}
for(Node *v=head;v;v=v->next)
cout<s<<' ';//逐个输出
return 0;
} 第二题:链表中间的元素
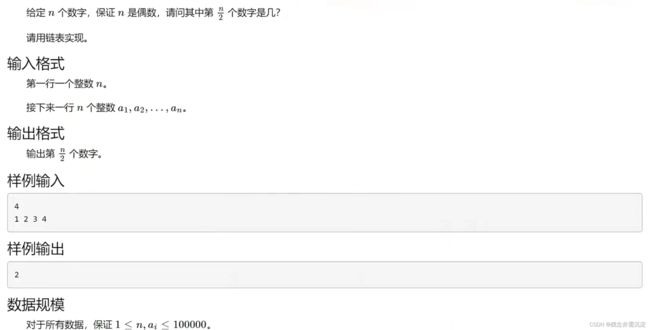
代码实现如下:
#include
using namespace std;
int n;
struct Node{
int v;
Node *next;
}*head,*tail,a[100001];
int main(){
cin>>n;
head=tail=NULL;
for(int i=1;i<=n;i++){
cin>>a[i].v;
if(head==NULL)
head=tail=&a[i];
else {
tail->next=&a[i];
tail=&a[i];
}
}
Node *p1=head,*p2=head->next;
while(p2!=tail){
p1=p1->next;
p2=p2->next->next;
}
cout<v< 接下来我会对这一段利用链表的思想进行解答的代码进行一些解释:首先分析题目,由于给出的n必定是偶数,所以我们这一道题目可以根据这一个条件可以利用这一个条件来实行这一题目,首先是结构体部分,我们定义了一个v代表了对应的数字,并在该结构体中定义了next指针变量指向下一个单位结构体,然后定义了头部和尾部的指针变量。
接下来进入主函数部分,首先将链表的头部和尾部都设置为空,然后从一到n进行枚举,在输入的同时,我们不段更新链表以及链表的尾部元素,这里需要仔细的理解,先声明a【i】的地址是tail的下一个位置,然后将tail更新为这一个地址以便于进行下一次的更新。
然后我们定义了两个指针变量p1和p2,将p1设置为头部然后将p2设置成链表的第二个元素,这对于一个总长度为偶数的链表来说,当p2不在尾部是,我们可以将p1加1一个地址而p2加两个地址,这样当p1对应链表的中间元素的时候,p2也必定会来到链表的尾部,最后输出这个时候p1对应的v即可。
3.合并链表:
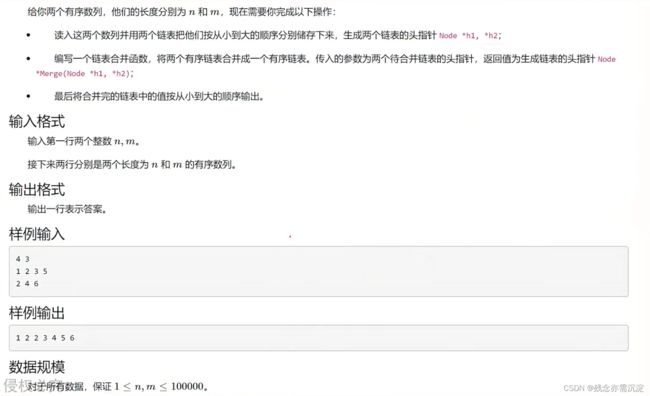
这道题的难度稍微大一些,对链表的运用稍微复杂一些,首先给出代码:
#include
#include
using namespace std;
int n,m;
struct Node{
int v;
Node *next;
}*h1,*t1,*h2,*t2,a[100001],b[100001];
Node *Merge(Node *h1,Node *h2){
Node *h3=NULL,*t3=NULL;
while(h1 && h2){
if(h1->vv){
if(h3==NULL)
h3=t3=h1;
else {
t3->next=h1;
t3=h1;}
Node *x=h1;
h1=h1->next;
x->next=NULL;
}
else{
if(h3==NULL)
h3=t3=h2;
else{
t3->next=h2;
t3=h2;}
Node *x=h2;
h2=h2->next;
x->next=NULL;
}
}
while(h1){
t3->next=h1;
t3=h1;
Node *x=h1;
h1=h1->next;
x->next=NULL;
}
while(h2){
t3->next=h2;
t3=h2;
Node *x=h2;
h2=h2->next;
x->next=NULL;
}
return h3;
}
int main(){
cin>>n>>m;
h1=t1=NULL;
for(int i=1;i<=n;i++){
cin>>a[i].v;
if(h1==NULL)
h1=t1=&a[i];
else {
t1->next=&a[i];
t1=&a[i];
}
}
h2=t2=NULL;
for(int i=1;i<=m;i++){
cin>>b[i].v;
if(h2==NULL)
h2=t2=&b[i];
else {
t2->next=&b[i];
t2=&b[i];
}
}
Node *h3=Merge(h1,h2);
for(Node *p=h3;p;p=p->next){
cout<v<<' ';
}
return 0;
}
然后我阐述一下思路:首先根据题目的要求我们知道需要分别给出长度为m,n的链表,同时保证两个链表在输入的时候,各自都是按照从小到大的顺序进行输入的,从而我们可以引入一个新的链表,它就是合并两个链表后的总链表,当输入完第一个和第二个链表之后,我们引入总链表的头部指针,并用一个函数来达到合并的功能,最后枚举总链表逐一输出即可,那么现在就主要是讲解这个merge函数:
首先这个函数是返回h3,它是合并后链表的头部指针,并且这个函数里面已经确定了头部指针后面的所有元素,我们挨着来看这个函数里面的代码:首先将头尾均设置为空,然后当h1和h2不为空的时候,每次将更小的那个排在前面,并更新尾部,同时需要注意的是,引入了一个x指针变量用于将已经插入过的链表元素设置成空,这也是函数里面最容易想不到的地方之一,然后当n和m两个值不相等的时候,就必定会有一个链表先输入完,那么接下来再用两个while,由于两个子链表都是按从小到大的顺序进行读入的,所以在第一个while循环结束之后,我们将剩下那个子链表中的元素插入到还没完善的总链表之后即可,这一总链表就完全完善了。
接下来就是回到了主函数部分,通过枚举的方式,逐一输出总链表中的元素即可。