Linux学习笔记——数据结构
前言
学习数据结构是为了让大家简洁高效的写程序,数据结构研究的是数据的逻辑结构与存储结构及其操作
程序=数据结构+算法
数据:计算机处理的对象已不再单纯是数值,更多的是一组数据
一组数据称之为数据元素
逻辑结构:数据元素与数据元素之间的关系
1对1:线性关系 ---线性表
1对多:树型关系---主要研究1对2的关系,二叉树
多对多:网状关系---图
一、概述
学习数据结构是为了让大家简洁高效的写程序,数据结构研究的是数据的逻辑结构与存储结构及其操作
程序=数据结构+算法
数据:计算机处理的对象已不再单纯是数值,更多的是一组数据
一组数据称之为数据元素
逻辑结构:数据元素与数据元素之间的关系
1对1:线性关系 ---线性表
1对多:树型关系---主要研究1对2的关系,二叉树
多对多:网状关系---图
存储结构:
顺序存储结构-----顺序表
链式存储结构-----链表
索引存储结构
哈希春初结构-----hash结构
操作:创建、插入、显示、删除、查找、修改
二、线性表
2.1.顺序表
2.1.1顺序表特点
顺序并且连续存储,访问方便;
大小固定;
表满不能存,表恐不能取;
2.1.2定义数据元素的类型
超市管理系统:
typedef struct shop
{
char name[20]//名字
float price//价格
char produce[30]//生产日期
int count;//数量
}data_type
typedef int data_type;
2.3.1定义顺序表的数据类型
设顺序表只能存储10个元素
#define N10;
typedef struct shop
{
data_type arr[N];
int count;//保存有效数据的个数(表满count==N;表空count==0;)
}List;
2.2链表
2.2.1 链表的特点
1、申请的空间可以不连续
2、大小不固定
3、插入删除方便,不需要移动元素
4、访问不方便
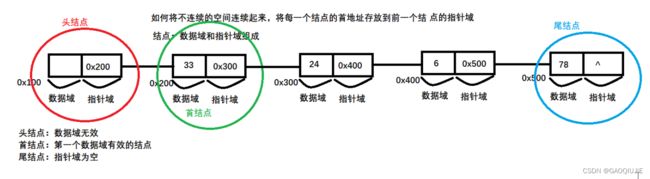
头结点:数据域无效的节点
首节点:第一个数据域有效的节点
尾结点:指针域为空
空链表:既是头结点又是尾结点,
2.2.2 链表的分类
头结点:带头结点的链表,不带头结点的链表;一般使用待头结点的链表
指针域是单向双向:单向链表,双向链表
尾结点是否指向头结点:循环链表和不循环链表
2.2.3 定义数据元素的类型
typedef int data_type
2.2.4 定义链表结点的数据类型
typedef struct linknode
{
data_type data;//数据域
struct linknode *pNext;//指针域
}Link;
2.2.5 插入结点
头插法:
1、创建新结点
pNew = (Link *)malloc(sizeof(Link));
2、将新值赋给新结点的数据域
pNew->data=item;
3、 先保护好要插入结点后面的节点
pNew->pNext = pHead->pNext
4、将新节点插入进去
pHead->pNext = pNew
尾插法:
1、创建新结点
pNew = (Link *)malloc(sizeof(Link));
2、将新值赋给新结点的数据域
pNew->data=item;
3、定义一个指针变量,初始化为头结点
Link *pFind = pHead;
4、判断pFind的指针域是否为空
while(pFind->pNext!=NULL)
{
pFind = pFind->pNext;
}
5、将新结点插入进去
pFind->pNext = pNew;
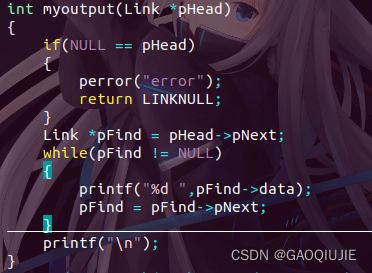
2.2.6 显示
1、定义一个指针,初始化为首结点
Link *pFind = pHead->pNext
2、判断pFind的指针域为NULL
while(pFind!=NULL)
{
printf("%d",pFind->data);
pFind = pFind->pNext;
}
3、步骤二循环至pFind的指针域为NULL结束
代码如下:
2.2.7 删除链表元素
头删法:
1、找到要删除的结点
Link *pDel = pHead->pNext;
2、保存要删除的数据
Link *pData = pDel->data;
3、保护要删除结点的后续结点
pHead->pNext = pDel->pNext;
4、删除(释放)pDel
free(pDel);
pDel = NULL;
尾删法:
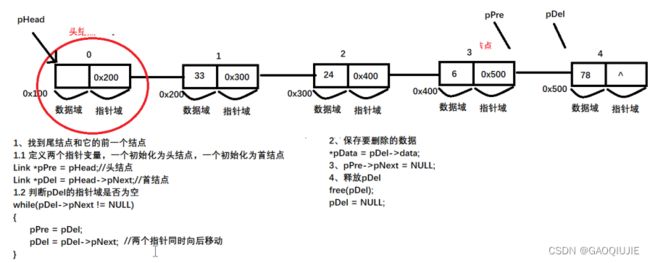
中间删除:
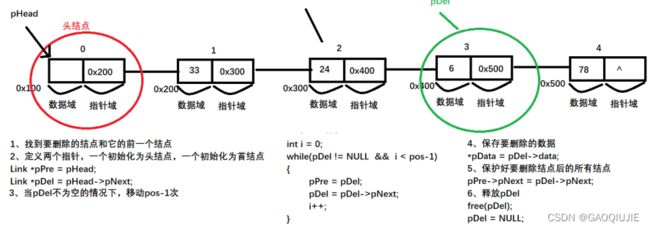
1、找到要删除的结点和他前一个结点
2、定义两个指针 一个初始化为头结点,一个初始化为首结点
Link *pDel = pHead->pNext;
Link *pPre = pHead;
2.2.8 销毁链表
思想:使用头删法的思想逐个销毁链表中的结点,直到链表为空
1、找到要删除的结点
Link *pDel = pHead->pNext;
2、保护要删除结点的后续结点
pHead->pNext = pDel->pNext;
3、删除(释放)pDel
free(pDel);
4、循环步骤1-3,直到pDel = NULL的时候完成销毁
5、释放头结点
free(pHead);
pHead = NULL;
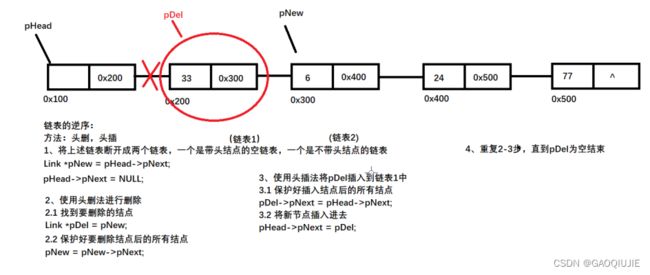
2.2.9 链表逆序
方法:头删,头插
1:断开为两个链表,一个带头结点的空链表,一个不带头结点的链表
Link *New = pHead->pNext;
pHead->pNext = NULL;
2:头删法删除
找到要删除的结点:Link *pDel = pNew;
保护后续结点:pNew = pNew->pNext;
3、头插将删除的插入到断开的头结点中
pDel->pNext
2.3 双向链表
2.3.1 双向链表中间插入
1、创建一个新结点
Dblink *pNew = (dblink)malloc(sizeof(dblink));
memset(pNew ,0,sizeof(dblink) );
2、将item赋值给pNew数据域
pNew->data = item;
3、找到要插入的结点
Dblink *pFind = pHead;
while(pFind !=NULL&& i { pFind = pFind->pNext; i++; } if(NULL == pFind) { return ERROR;} 4、保护要插入位置的前后结点 pNew->pNext = pFind->pNext; pNew->pPre = pFind; 5、插入结点 pFind->pNext = pNew; pFind->pNext->pPre = pNew; 栈的特点:先进后出;只能在栈顶操作 typedef int data_type; typedef struct stack { data_type arr[N]; int top ;//pStack->top ==-1,表示栈空,pStack->top ==N-1则表示栈满 }; 3.1.3 pStack->top ==-1,表示栈空,pStack->top ==N-1则表示栈满 入栈: 判断是否栈满 向栈中插入元素 pStack->top++; pStack->arr[top]=item; 出栈: 判断是否为空栈 *pData = pStack->arr[top]; pStack->top--; 自学 特点:先进先出;只允许在队头进行删除,队尾插入 4.1.1 定义数据元素的类型 typedef int data_type; 4.1.2 定义顺序队列的数据类型 typedef struct queue { int front;//队头下标 int rear;//队尾下标 //一般将队头队尾下标初始化为-1 //front,rear都等于-1时,表示空队 data_type arr[N]; }Queue; 空队:pQueue->front== pQueue->rear 入队:pQueue->front = pQueue->front+1 pQueue->arr[pQueue->front] = item; 出队:pQueue->rear = pQueue->rear+1 *pData = pQueue->arr[pQueue->rear]; 满足树的条件: 1、有且只有一个根节点 2、其余的结点可以分为n个互不相交的根节点 5.1 度数 一个结点子树的个数称为该节点的度数,一棵树的度数指该树中结点最大的度数 树叶 度数为0的结点,被称为树叶 深度(高度) 结点的层数等于父节点的层数+1,根结点的层数定义为1,树中结点层数的最大值称为该树的高度或者深度 边数 一个节点系列k1,k2, ……,ki,ki+1, ……,kj,并满足ki是ki+1的父节点,就称为一条从k1到kj的路径,路径的长度为j-1,即路径中的边数 5.二叉树 定义:二叉树是n个结点的有限集合。她或者是空集,或者是由一个根节点以及两颗互不相交的左子树和右子树构成 注意:二叉树严格区分左孩子和右孩子,即使只有一个子节点也要区分 特征:二叉树做多有两个子节点; 严格区分左右子树 性质: 二叉树第i(i>=1)层上的结点最多为2(^i-1)个 深度为k(k>=1)的二叉树最多有(2^k)-1个结点 总结点的个数:n = 2^0 + 2^1+2^2+ …… 2^(k-1) 2n = 2^1 + 2^2 + …… 2^(k-1) + 2^k 两个相减得:n = 2^k – 1 案例1、具有1000个节点的二叉树的最小深度为____(第一层深度为1) A.11 B.12 C.9 D.10 二叉树的存储 顺序存储 1、将不完全二叉树变为完全二叉树 2、将完全二叉树按照从上往下、从左往右、根节点为1编号 3、将n个结点的 链式存储 定义元素的数据类型 typedef char data_type; 定义二叉树结点的数据类型 typeedef struct treeNode { struct treeNode *lchild; data_type data; struct treeNode *rchild; }Tree; 二叉树的遍历 非递归遍历 递归遍历: 先序遍历:先访问树根再访问左子树最后访问右子树 void preOrder(Tree *pBoot) { if(NULL == pBoot) { return NULL; } printf("%c",pboot->data); preOrder(pBoot->lChild); preOrder(pBoot->rChild); } 中序遍历:先访问左子树再访问根结点最后访问右子树 void minOrder(Tree *pBoot) { if(NULL == pBoot) { return NULL; } minOrder(pBoot->lChild); printf("%c",pboot->data); minOrder(pBoot->rChild); } 后序遍历:先访问左子树再访问右子树最后访问根结点 void postOrder(Tree *pBoot) { if(NULL == pBoot) { return NULL; } postOrder(pBoot->lChild); postOrder(pBoot->rChild); printf("%c",pboot->data); } 例题: 赫夫曼树: 又称最优树 注意:赫夫曼树不唯一,为了保证赫夫曼树的唯一性,我们遵循左小右大(指权值)的原则 创将一颗有序树 54,26,1,33,99,66,75,81,22,17 将第一个树作为树根 后面的数,如果比树根小作为左子树,比树根大作为右子树 int arr[10] = {54,26,1,33,99,66,75,81,22,17}; 向树中插入元素 while(1) { if(pNew->data < pBoot->data) { //插入左子树 if(pBoot->lChild != NULL) { pBoot = pBoot->lChild; } else { pBoot->lChild = pNew return OK; } } else { //插入右子树 if(pBoot->rChild != NULL) { pBoot = pBoot->rChild; } else { pBoot->rChild = pNew return OK; } //插入右子树 } } 什么是算法 解决问题的思想步骤 程序 = 数据结构 + 算法 算法设计:取决于选定的逻辑结构(一对一,一对多,多对多) 算法实现:依赖于采用的存储结构(顺序存储,链式存储,索引存储,哈希存储) 消耗的时间的多少(时间复杂度,越少越好) 消耗存储空间的多少(空间复杂度) struct A struct B { { char a; int b; int b; char a; short c; short c; } } 容易理解,容易编程和调试,容易维护。时间复杂度的概念介绍 时间复杂度 时间复杂度:算法中可执行语句重复执行的频度和,记为T(n) T(n) =O( f (n) ) T(n):问题规模的时间函数 n:问题的规模 O:时间数量级 f(n):算法中语句重复执行的次数 for(i=1;i<=n;i++) { sum = sum + i ; } f(n) = n;//线性级 算法3: for(i=0;i<=n;i++) { for(i=1;i<=n;i++) { printf("hello\n") ; } } f(n) = 1+2+3+4+5+...n=n(n+1)/2 = n^2/2 + n/2 1、根据问题规模写出n的表达式f(n) = n^2/2 + n/2 2、如果有常数项,将其置为1(注意:f(n)表达式中只有常数项的时候才可以使用) 3、只保留最高项,其他项舍去f(n) = n^2/2 4、如果最高项系数不为1,将其置为1 f(n) =n^2 T(n) = O(n^2) 顺序查找 int arr[5] = {1,2,3,4,5}; for(int = 0 ; i<5 ;i++) { if(arr[i] == 5 ) { return ;} } 时间复杂度:T(n) = O(n); 注意:只能用于有序序列 int arr[10] = {11,22,33,44,55,66,77,88,93,99}; 假设查找item = 77 1、定义最小、最大的下标low、highint, low = o; int mid = (low + high)/ 2 快速排序 三.栈
3.1 顺序栈
3.1.1 定义元素数据类型
3.1.2 定义顺序栈的数据类型
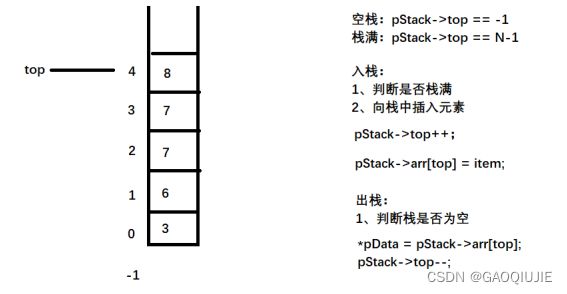
3.2 链式栈
4. 队列
4.1顺序队列

5. 树
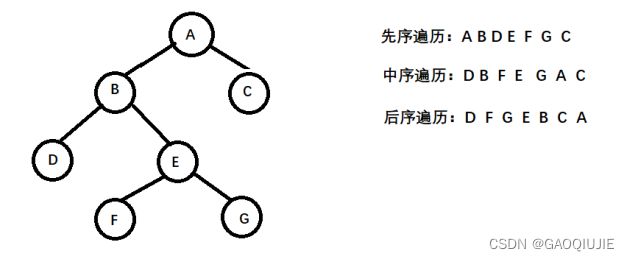
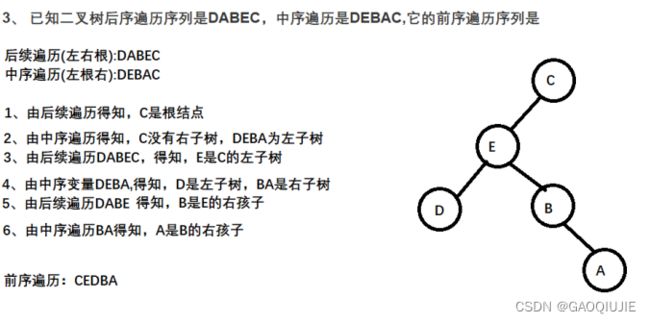

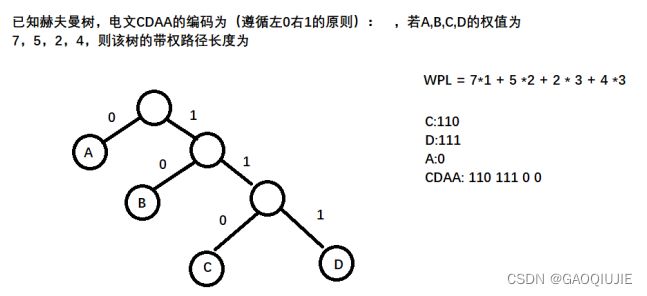

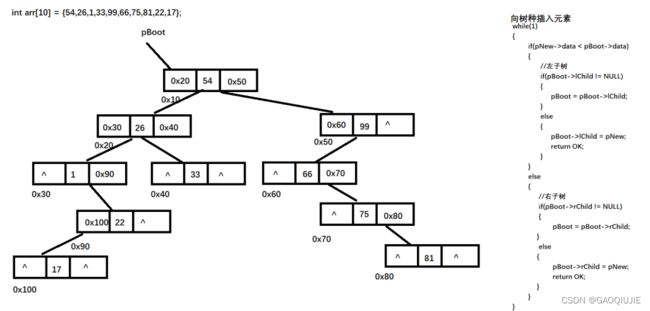
算法:
算法与数据结构
算法的特性

如何评价一个算法的好坏
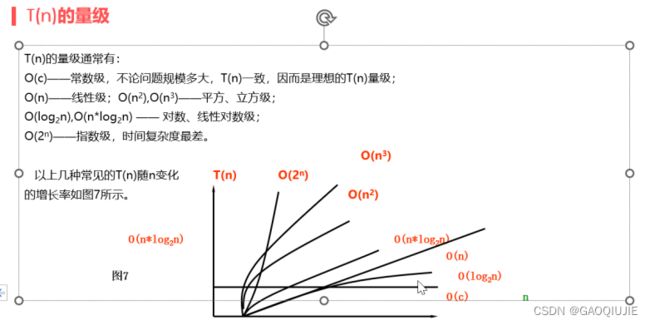
计算O的方法

查找
二分查找
int high = N-1;
2、让mid等于(low+high)/2